爬虫(十七):scrapy分布式原理
一:scrapy工作流程
scrapy单机架构:
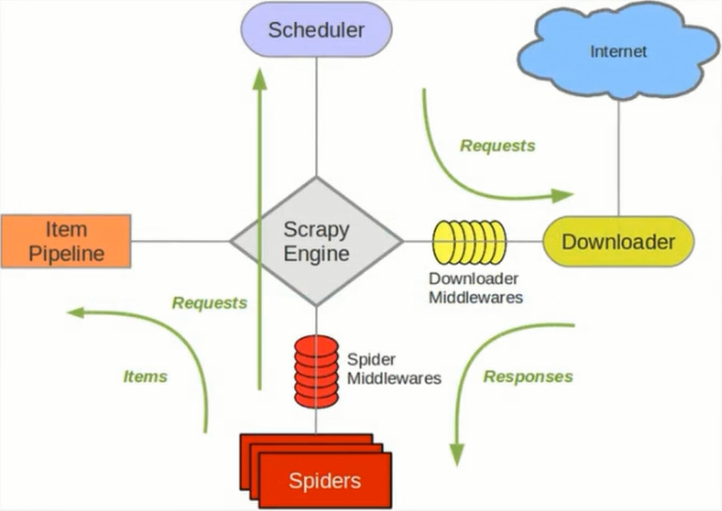
单主机爬虫架构:

分布式爬虫架构:

这里重要的就是我的队列通过什么维护?
这里一般我们通过Redis为维护,Redis,非关系型数据库,Key-Value形式存储,结构灵活。
并且redis是内存中的数据结构存储系统,处理速度快,提供队列集合等多种存储结构,方便队列维护
如何去重?
这里借助redis的集合,redis提供集合数据结构,在redis集合中存储每个request的指纹
在向request队列中加入Request前先验证这个Request的指纹是否已经加入集合中。如果已经存在则不添加到request队列中,如果不存在,则将request加入到队列并将指纹加入集合
如何防止中断?如果某个slave因为特殊原因宕机,如何解决?
这里是做了启动判断,在每台slave的Scrapy启动的时候都会判断当前redis request队列是否为空
如果不为空,则从队列中获取下一个request执行爬取。如果为空则重新开始爬取,第一台丛集执行爬取向队列中添加request
如何实现上述这种架构?
这里有一个scrapy-redis的库,为我们提供了上述的这些功能
scrapy-redis改写了Scrapy的调度器,队列等组件,利用他可以方便的实现Scrapy分布式架构
关于scrapy-redis的地址--》scrapy-redis GitHub地址
二:搭建分布式爬虫
参考--》官网地址
前提是要安装scrapy_redis模块:pip install scrapy_redis
这里的爬虫代码是用的之前写过的爬取知乎用户信息的爬虫
修改该settings中的配置信息:
替换scrapy调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
添加去重的class
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
添加pipeline
如果添加这行配置,每次爬取的数据也都会入到redis数据库中,所以一般这里不做这个配置
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
共享的爬取队列,这里用需要redis的连接信息
这里的user:pass表示用户名和密码,如果没有则为空就可以
REDIS_URL = 'redis://user:pass@hostname:9001'
设置为为True则不会清空redis里的dupefilter和requests队列
这样设置后指纹和请求队列则会一直保存在redis数据库中,默认为False,一般不进行设置
SCHEDULER_PERSIST = True
设置重启爬虫时是否清空爬取队列
这样每次重启爬虫都会清空指纹和请求队列,一般设置为False
SCHEDULER_FLUSH_ON_START=True
分布式
将上述更改后的代码拷贝的各个服务器,当然关于数据库这里可以在每个服务器上都安装数据,也可以共用一个数据,我这里方面是连接的同一个mongodb数据库,当然各个服务器上也不能忘记:
所有的服务器都要安装scrapy,scrapy_redis,pymongo
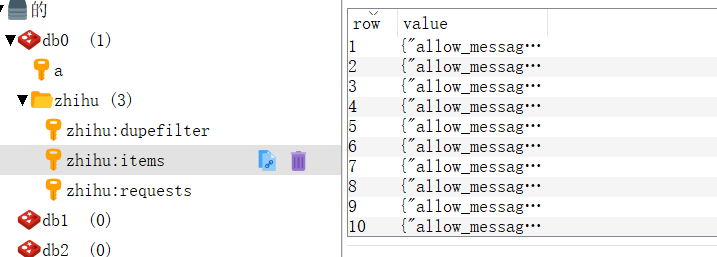
这样运行各个爬虫程序启动后,在redis数据库就可以看到如下内容,dupefilter是指纹队列,requests是请求队列
项目代码GitHub地址--》分布式爬取知乎
爬虫(十七):scrapy分布式原理的更多相关文章
- Python 爬虫之 Scrapy 分布式原理以及部署
Scrapy分布式原理 关于Scrapy工作流程 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享 ...
- scrapy分布式原理
scrapy分布式原理 关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键 ...
- Python爬虫从入门到放弃(二十)之 Scrapy分布式原理
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列. 分布式架 ...
- Python爬虫【五】Scrapy分布式原理笔记
Scrapy单机架构 在这里scrapy的核心是scrapy引擎,它通过里面的一个调度器来调度一个request的队列,将request发给downloader,然后来执行request请求 但是这些 ...
- Python之爬虫(二十二) Scrapy分布式原理
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列. 分布式架 ...
- 第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点 1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- python网络爬虫之scrapy 工程创建以及原理介绍
执行scrapy startproject XXXX的命令,就会在对应的目录下生成工程 在pycharm中打开此工程目录:并在Run中选择Edit Configuration 点击+创建一个Pytho ...
- scrapy分布式爬虫scrapy_redis二篇
=============================================================== Scrapy-Redis分布式爬虫框架 ================ ...
- 一篇文章教会你理解Scrapy网络爬虫框架的工作原理和数据采集过程
今天小编给大家详细的讲解一下Scrapy爬虫框架,希望对大家的学习有帮助. 1.Scrapy爬虫框架 Scrapy是一个使用Python编程语言编写的爬虫框架,任何人都可以根据自己的需求进行修改,并且 ...
随机推荐
- .net framework 4.0 安装一直失败,错误代码0x80240037,解决
本文链接:https://blog.csdn.net/Chris_Ime/article/details/81626778 今天遇到一问题,在新电脑win7系统上安装.net framework 4. ...
- 案例(2)-- 线程不安全对象(SimpleDateFormat)
问题描述: 1.系统偶发性抛出异常:java.lang.NumberFormatException: multiple points ,追溯源头抛出的类为:SimpleDateFormat 问题的定位 ...
- The Preliminary Contest for ICPC Asia Xuzhou 2019 E XKC's basketball team [单调栈上二分]
也许更好的阅读体验 \(\mathcal{Description}\) 给n个数,与一个数m,求\(a_i\)右边最后一个至少比\(a_i\)大\(m\)的数与这个数之间有多少个数 \(2\leq n ...
- 全栈项目|小书架|服务器开发-NodeJS 项目分包
唠嗑 参考的是慕课网七月老师的课程,七月的课质量真的挺高的,推荐一波.这次的小书架项目源码不会全部公开,因为用了七月老师课程的绝大部分代码.虽然代码不全,但是只要思路看得懂,代码实现就很简单了. 小书 ...
- GOF学习笔记1:术语
1.abstract class 抽象类定义了一个接口,把部分或全部实现留给了子类,不能实例化. 2.abstract coupling 抽象耦合如果一个类A引用了另一个抽象类B,那么就说A是抽象耦 ...
- copy 合并
copy /b xxx.jpg + yyy.txt zzz.jpg /b 二进制 /a 文本
- 微信小程序自定义组件——接受外部传入的样式类
https://developers.weixin.qq.com/miniprogram/dev/framework/custom-component/wxml-wxss.html 外部样式类 有时, ...
- Apollo 与 .net core
appsettings配置内容 { "Apollo": { "AppId": "netcore", "Env": &qu ...
- interface Part3(实现:显示和隐式)
1. 接口的实现实际上和类之间的继承是一样的,也是重写了接口中的方法,让其有了具体的实现内容. 2. 但需要注意的是,在类中实现一个接口时必须将接口中的所有成员都实现,否则该类必须声明为抽象类,并将接 ...
- git 打tag标着版本
1.git tag v1.0 2.git push origin v1.0