scrapy分布式原理
scrapy分布式原理
关于Scrapy工作流程回顾
Scrapy单机架构
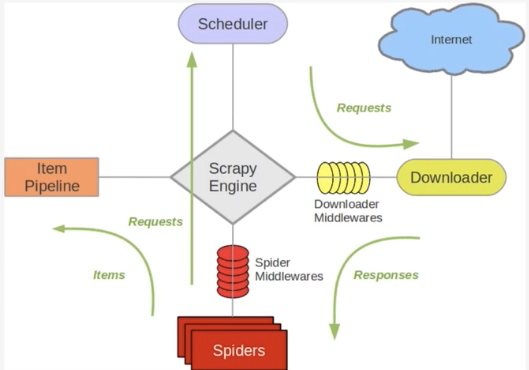
上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列。
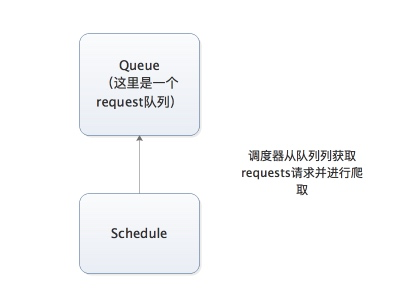
分布式架构
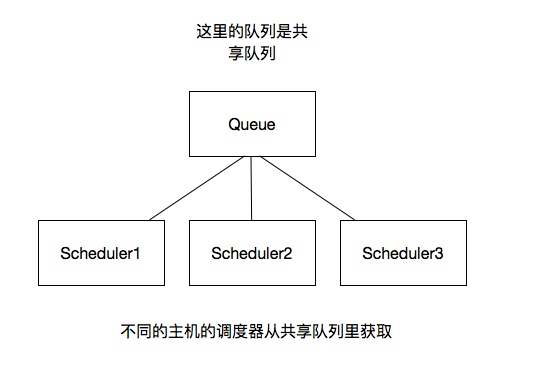
我将上图进行再次更改
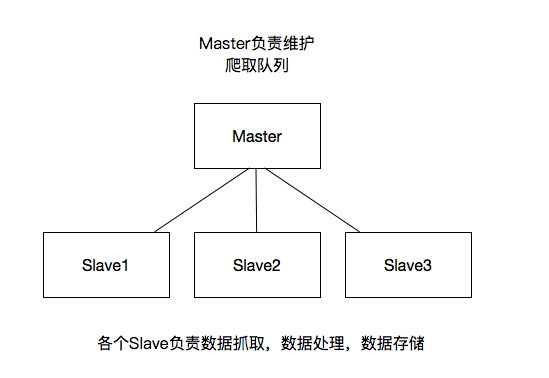
这里重要的就是我的队列通过什么维护?
这里一般我们通过Redis为维护,Redis,非关系型数据库,Key-Value形式存储,结构灵活。
并且redis是内存中的数据结构存储系统,处理速度快,提供队列集合等多种存储结构,方便队列维护
如何去重?
这里借助redis的集合,redis提供集合数据结构,在redis集合中存储每个request的指纹
在向request队列中加入Request前先验证这个Request的指纹是否已经加入集合中。如果已经存在则不添加到request队列中,如果不存在,则将request加入到队列并将指纹加入集合
如何防止中断?如果某个slave因为特殊原因宕机,如何解决?
这里是做了启动判断,在每台slave的Scrapy启动的时候都会判断当前redis request队列是否为空
如果不为空,则从队列中获取下一个request执行爬取。如果为空则重新开始爬取,第一台丛集执行爬取向队列中添加request
如何实现上述这种架构?
这里有一个scrapy-redis的库,为我们提供了上述的这些功能
scrapy-redis改写了Scrapy的调度器,队列等组件,利用他可以方便的实现Scrapy分布式架构
关于scrapy-redis的地址:https://github.com/rmax/scrapy-redis
搭建分布式爬虫
参考官网地址:https://scrapy-redis.readthedocs.io/en/stable/
前提是要安装scrapy_redis模块:pip install scrapy_redis
这里的爬虫代码是用的之前写过的爬取知乎用户信息的爬虫
修改该settings中的配置信息:
替换scrapy调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
添加去重的class
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
添加pipeline
如果添加这行配置,每次爬取的数据也都会入到redis数据库中,所以一般这里不做这个配置
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
共享的爬取队列,这里用需要redis的连接信息
这里的user:pass表示用户名和密码,如果没有则为空就可以
REDIS_URL = 'redis://user:pass@hostname:9001'
设置为为True则不会清空redis里的dupefilter和requests队列
这样设置后指纹和请求队列则会一直保存在redis数据库中,默认为False,一般不进行设置
SCHEDULER_PERSIST = True
设置重启爬虫时是否清空爬取队列
这样每次重启爬虫都会清空指纹和请求队列,一般设置为False
SCHEDULER_FLUSH_ON_START=True
分布式
将上述更改后的代码拷贝的各个服务器,当然关于数据库这里可以在每个服务器上都安装数据,也可以共用一个数据,我这里方面是连接的同一个mongodb数据库,当然各个服务器上也不能忘记:
所有的服务器都要安装scrapy,scrapy_redis,pymongo
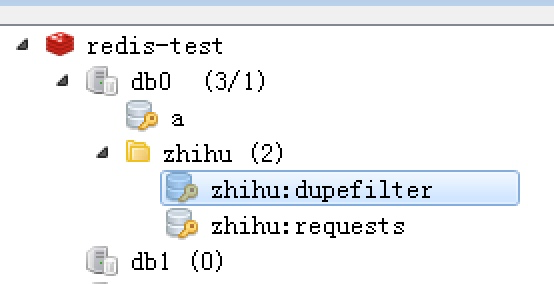
这样运行各个爬虫程序启动后,在redis数据库就可以看到如下内容,dupefilter是指纹队列,requests是请求队列
scrapy分布式原理的更多相关文章
- Python 爬虫之 Scrapy 分布式原理以及部署
Scrapy分布式原理 关于Scrapy工作流程 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享 ...
- Python爬虫从入门到放弃(二十)之 Scrapy分布式原理
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列. 分布式架 ...
- Python爬虫【五】Scrapy分布式原理笔记
Scrapy单机架构 在这里scrapy的核心是scrapy引擎,它通过里面的一个调度器来调度一个request的队列,将request发给downloader,然后来执行request请求 但是这些 ...
- 爬虫(十七):scrapy分布式原理
一:scrapy工作流程 scrapy单机架构: 单主机爬虫架构: 分布式爬虫架构: 这里重要的就是我的队列通过什么维护?这里一般我们通过Redis为维护,Redis,非关系型数据库,Key-Valu ...
- Python之爬虫(二十二) Scrapy分布式原理
关于Scrapy工作流程回顾 Scrapy单机架构 上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列. 分布式架 ...
- 第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点
第三百五十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy分布式爬虫要点 1.分布式爬虫原理 2.分布式爬虫优点 3.分布式爬虫需要解决的问题
- 学习笔记TF061:分布式TensorFlow,分布式原理、最佳实践
分布式TensorFlow由高性能gRPC库底层技术支持.Martin Abadi.Ashish Agarwal.Paul Barham论文<TensorFlow:Large-Scale Mac ...
- scrapy分布式的几个重点问题
我们之前的爬虫都是在同一台机器运行的,叫做单机爬虫.scrapy的经典架构图也是描述的单机架构.那么分布式爬虫架构实际上就是:由一台主机维护所有的爬取队列,每台从机的sheduler共享该队列,协同存 ...
- scrapy分布式浅谈+京东示例
scrapy分布式浅谈+京东示例: 学习目标: 分布式概念与使用场景 浅谈去重 浅谈断点续爬 分布式爬虫编写流程 基于scrapy_redis的分布式爬虫(阳关院务与京东图书案例) 环境准备: 下载r ...
随机推荐
- [noi2002]M号机器人
3030年,Macsy正在火星部署一批机器人.第1秒,他把机器人1号运到了火星,机器人1号可以制造其他的机器人.第2秒,机器人1号造出了第一个机器人——机器人2号.第3秒,机器人1号造出了另一个机器人 ...
- led子系统【转】
本文转载自:http://blog.csdn.net/yuanlulu/article/details/6438841 版权声明:本文为博主原创文章,未经博主允许不得转载. ============= ...
- 将PHP数组输出为HTML表格
1. [代码][PHP]代码 <?phpclass xtable{ private $tit,$arr,$fons,$sextra; public function __con ...
- Jmeter参数化_CSV Data Set Config
1. 在用函数助手进行参数化的时候遇到一个问题,每个线程组每次循环的时候读取的值都是一样的,为了解决这个问题,将函数助手替换为CSV_Data_Set_Config. 2. 添加配置元件csv dat ...
- Java网络编程Socket通信
TCP(Transmission Control Protocol 传输控制协议)是一种面向连接的.可靠的.基于字节流的传输层通信协议 UDP (User Datagram Proto ...
- ios系统的特点
iOS优势 1). 比较稳定,因为他是一个完全封闭的系统,不开源,但是这个系统有他自己严格管理体系,比如app store的app应用:他有自己的评审规则,另外很多软件是需要收费的,这在一定程度上也说 ...
- BZOJ_1095_[ZJOI2007]Hide 捉迷藏_动态点分治+堆
BZOJ_1095_[ZJOI2007]Hide 捉迷藏_动态点分治+堆 Description 捉迷藏 Jiajia和Wind是一对恩爱的夫妻,并且他们有很多孩子.某天,Jiajia.Wind和孩子 ...
- AQS共享锁应用之Semaphore原理
我们调用Semaphore方法时,其实是在间接调用其内部类或AQS方法执行的.Semaphore类结构与ReetrantLock类相似,内部类Sync继承自AQS,然后其子类FairSync和NoFa ...
- html锚点实现的方法
1 通过id <a href="#div1"> 通过id获取锚点</a> <div style=" height:200px; width: ...
- iOS中判断基础字符(大小写、数字等的判断)
函数:isdigit 用法:#include 功能:判断字符c是否为数字 说明:当c为数字0-9时,返回非零值,否则返回零. 函数:islower 用法:#include 功能:判断字符c是否为小写英 ...