Hadoop集群搭建-02安装配置Zookeeper
这一篇接着记录集群搭建,开始安装配置zookeeper,它的作用是做集群的信息同步,zookeeper配置时本身就是一个独立的小集群,集群机器一般为奇数个,只要机器过半正常工作那么这个zookeeper集群就能正常工作,工作时自动选举一个leader其余为follower,所以最低是配置三台。
注意本篇文章的几乎所有操作如不标注,则默认为hadoop用户下操作
1.首先修改下上一篇写的批量脚本
复制一份,然后把ips内删除两台机器名,,只留下前三台即可,然后把几个脚本的名称啥的都改一下,和内部引用名都改一下。
可以用我改好的https://www.lanzous.com/b849762/ 密码:1qq6
2.安装zookeeper
可以用xshell的rz命令上传zookeeper安装包,安装包在这里https://www.lanzous.com/b849708/ 密码:8a10
[hadoop@nn1 ~]$ cd zk_op/
批量发送给三台机器
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh ~/upload/zookeeper-3.4.8.tar.gz /tmp/
查看是否上传成功
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /tmp | grep zoo*"
批量解压到各自的/usr/local/目录下
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh tar -zxf /tmp/zookeeper-3.4.8.tar.gz -C /usr/local/
再次查看是否操作成功
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /usr/local/ | grep zoo*"
批量改变/usr/local/zookeeper-3.4.8目录的用户组为hadoop:hadoop
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh chown -R hadoop:hadoop /usr/local/zookeeper-3.4.8
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh chmod -R 770 /usr/local/zookeeper-3.4.8
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /usr/local/ | grep zookeeper-3.4.8"
批量创建软链接(可以理解为快捷方式)
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh ln - s /usr/local/zookeeper-3.4.8/ /usr/local/zookeeper
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh "ls -l /usr/local/ | grep zookeeper"
这里软链接的用户组合权限可以不用修改,默认为root或者hadoop都可以。
修改/usr/local/zookeeper/conf/zoo.cfg
可以用我改好的https://www.lanzous.com/b849762/ 密码:1qq6
批量删除原有的zoo_sample.cfg文件,当然先备份为好
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh rm -f /usr/local/zookeeper/conf/zoo_sample.cfg
把我们准备好的配置文件放进去,批量。
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh ~/zoo.cfg /usr/local/zookeeper/conf/
=================================================================================================
然后修改/usr/local/zookeeper/bin/zkEnv.sh脚本文件,添加日志文件路径
[hadoop@nn1 zk_op]$ vim /usr/local/zookeeper/bin/zkEnv.sh
ZOO_LOG_DIR=/data
把这个配置文件批量分发给其他机器
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh /usr/local/zookeeper/bin/zkEnv.sh /usr/local/zookeeper/bin/
给5台机器创建/data目录,注意这里是给5台机器创建。用的没改过的原本批量脚本。
[hadoop@nn1 hadoop_base_op]$ ./ssh_root.sh mkdir /data
[hadoop@nn1 hadoop_base_op]$ ./ssh_root.sh chown hadoop:hadoop /data
[hadoop@nn1 hadoop_base_op]$ ./ssh_all.sh "ls -l | grep data"
上面为啥是突然创建5个/data呢,,,因为后边的hdfs和yarn都需要,后边的hdfs是运行在后三台机器上的,所以现在直接都创建好。
然后回到zk_op中,给前三台机器创建id文件。用于zookeeper识别
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh touch /data/myid
然后_分别进三台机器_,给这个文件追加id值。
第一台:
echo "1" > /data/myid
第二台:
echo "2" > /data/myid
第三台:
echo "3" > /data/myid
3.批量设置环境变量
在nn1上切换到root用户更改系统环境变量
[hadoop@nn1 zk_op]$ su - root
[root@nn1 ~]# vim /etc/profile
文件在末尾添加
#set Hadoop Path
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HDFS_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native:/usr/lib64
export HBASE_HOME=/usr/local/hbase
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$HIVE_HOME/bin:/usr/local/zookeeper/bin
然后批量发送给其他两台机器
[hadoop@nn1 zk_op]$ ./zk_scp_all.sh /etc/profile /tmp/
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh cp -f /tmp/profile /etc/profile
批量检查一下
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh tail /etc/profile
批量source一下环境变量
[hadoop@nn1 zk_op]$ ./zk_ssh_root.sh source /etc/profile
4.批量启动zookeeper
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh /usr/local/zookeeper/bin/zkServer.sh start
查看一下是否启动。看看有没有相关进程
[hadoop@nn1 zk_op]$ ./zk_ssh_all.sh jps
如下图查看进程,有QPM进程就说明启动成功
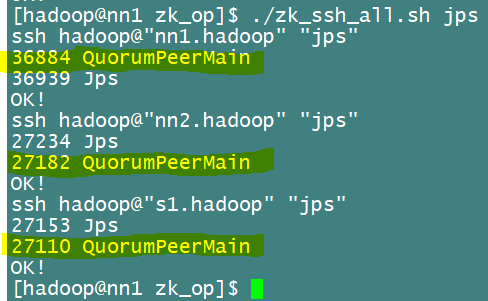
或者直接查看状态,
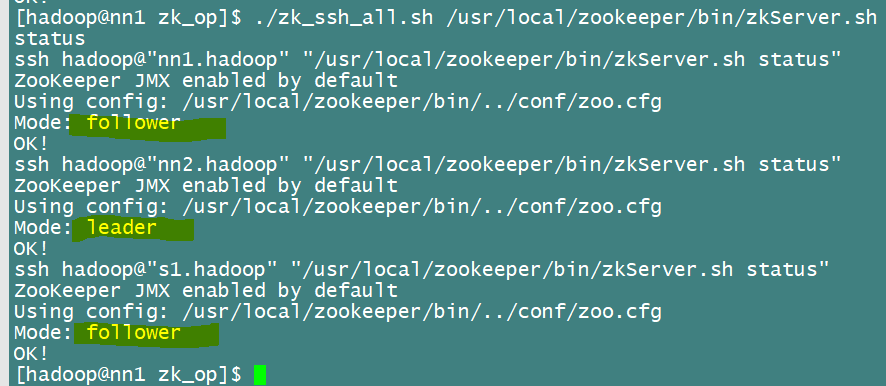
好了,zookeeper安装配置顺利结束!!!
Hadoop集群搭建-02安装配置Zookeeper的更多相关文章
- Hadoop集群搭建-05安装配置YARN
Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hadoop集群搭建-01前期准备 先保证集群5台虚 ...
- Hadoop集群搭建-04安装配置HDFS
Hadoop集群搭建-05安装配置YARN Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hado ...
- 基于Hadoop集群搭建Hive安装与配置(yum插件安装MySQL)---linux系统《小白篇》
用到的安装包有: apache-hive-1.2.1-bin.tar.gz mysql-connector-java-5.1.49.tar.gz 百度网盘链接: 链接:https://pan.baid ...
- Linux下Hadoop集群环境的安装配置
1)安装Ubuntu或其他Linux系统: a)为减少错误,集群中的主机最好安装同一版本的Linux系统,我的是Ubuntu12.04. b)每个主机的登陆用户名也最好都一样,比如都是hadoop,不 ...
- Hadoop集群搭建(六)~安装JDK
前面集群的准备工作都做完了,本篇记录安装JDK,版本位1.8 1,在opt目录下创建software和module文件夹:software用来放安装包,module为安装目录 2,把JDK和hadoo ...
- Hadoop集群搭建的密钥配置SSH实现机制的配置(2)
[hadoop@weekend110 ~]$ ssh-keygen -t rsa 用来生产密钥对 Generating public/private rsa key pair. Enter file ...
- Hadoop集群搭建-虚拟机安装(转)(一)
1.软件准备 a).操作系统:CentOS-7-x86_64-DVD-1503-01 b).虚拟机:VMware-workstation-full-9.0.2-1031769(英文原版先安装) VM ...
- Hadoop集群搭建的密钥配置SSH实现机制
- Hadoop集群搭建-03编译安装hadoop
Hadoop集群搭建-05安装配置YARN Hadoop集群搭建-04安装配置HDFS Hadoop集群搭建-03编译安装hadoop Hadoop集群搭建-02安装配置Zookeeper Hado ...
随机推荐
- socketserver(多连接)
正如前面的socket模块部分看到的一样,写一个简单套接字服务器不是很难,如果想实现超出继承的应用,最好寻求一些帮助,socketserver模块是标准库中很多服务器框架的基础,这些服务器架构包括Ba ...
- MySQL认识索引
什么是索引? 索引在MySQL中也叫是一种“键”,是存储引擎用于快速找到记录的一种数据结构.索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要.索引优化应该是对查询 ...
- C++ 仿函数和适配器
本文从不断复杂的应用场景入手,来说明C++设计仿函数和适配器的原因,并深入源码来介绍仿函数和适配器的使用方法. 仿函数 现有一个vector,需要统计大于8的元素个数. 使用std::count_if ...
- CF1207B
CF1207B-Square Filling 题意: 两个矩阵a,b,已知矩阵b,每次能修改b矩阵中相邻的四个格(b为空矩阵),使b变为a 解法: 枚举矩阵中的1,按题意修改,并把改过的四个点都标记一 ...
- The JAVA_HOME environment variable is not defined correctly的错误
The JAVA_HOME environment variable is not defined correctlyThis environment variable is needed to ru ...
- Java图片裁剪
public static void main(String[] args) throws IOException { String path = "C:/Users/yang/Deskto ...
- IDEA如何切换到括号外
一般我们输入完括号后都会习惯性Enter或者Shift + Enter切换到括号外,结果却变成了: public void nothing() Enter → public void nothing( ...
- Linux 常用命令安装
系统版本: Centos-7-x86_64-minimal 1. 网络相关 1.1 MTR 跟踪路由,还可以测试丢包率.网络延迟 yum -y install mtr 2. 文件相关 2.1 sz ...
- 负载均衡 | Nginx+Tomcat 动静分离实现负载均衡
0.前期准备 使用Debian环境.安装Nginx(默认安装),一个web项目,安装tomcat(默认安装)等. 1.一份Nginx.conf配置文件 基本配置这个文件,就可以实现负载了.但是里面的各 ...
- Go项目的测试代码3(测试替身Test Double)
上一篇文章介绍了项目中测试代码的写法. Go项目的测试代码2(项目运用) 这里简单的共享一下测试替身. 当我们写测试代码的时候,经常遇到一个问题.跟别的模块或服务有依赖性,可是功能还没开发完.或是因为 ...