spark的task调度器(FAIR公平调度算法)
FAIR 调度策略的树结构如下图所示:
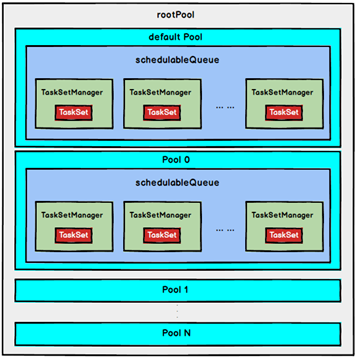
FAIR 调度策略内存结构
FAIR 模式中有一个 rootPool 和多个子 Pool, 各个子 Pool 中存储着所有待分配的 TaskSetMagager 。
在 FAIR 模 式 中 , 需 要 先 对 子 Pool 进 行 排 序 , 再 对 子 Pool 里 面 的
TaskSetMagager 进行排序,因为 Pool 和 TaskSetMagager 都继承了 Schedulable 特质, 因此使用相同的排序算法。
排序过程的比较是基于 Fair-share 来比较的,每个要排序的对象包含三个属性:
runningTasks 值( 正在运行的 Task 数)、minShare 值、weight 值,比较时会综合考量 runningTasks 值, minShare 值以及 weight 值。
注意,minShare、weight 的值均在公平调度配置文件 fairscheduler.xml 中被指定,调度池在构建阶段会读取此文件的相关配置。
1) 如果 A 对象的 runningTasks 大于它的 minShare, B 对象的 runningTasks 小于它的 minShare,那么 B 排在 A 前面; ( runningTasks比 minShare小的先执行)
2) 如果 A 、B 对象的 runningTasks 都小于它们的 minShare ,那么就比较runningTasks 与 minShare 的比值( minShare 使用率),谁小谁排前面;( minShare使用率低的先执行)
3) 如果 A 、B 对象的 runningTasks 都大于它们的 minShare ,那么就比较runningTasks 与 weight 的比值( 权重使用率),谁小谁排前面。(权重使用率低的先执行)
4) 如果上述比较均相等,则比较名字。
整体上来说就是通过 minShare 和 weight 这两个参数控制比较过程, 可以做到让 minShare 使用率和权重使用率少( 实际运行 task 比例较少) 的先运行。
private[spark] class FairSchedulingAlgorithm extends SchedulingAlgorithm {
override def comparator(s1: Schedulable, s2: Schedulable): Boolean = {
val minShare1 = s1.minShare
val minShare2 = s2.minShare
默认为0,除非通过fair的配置文件进行了配置指定
val runningTasks1 = s1.runningTasks
val runningTasks2 = s2.runningTasks
如果是TaskSetManager时,就是taskSet中运行的task的个数,
如果是Pool实例是表示是所有使用这个poolName的所有的TaskSetManager正在运行的task的个数.
val s1Needy = runningTasks1 < minShare1
val s2Needy = runningTasks2 < minShare2
只有在minShare在fair的配置文件中显示配置,同时大于正在运行的task的个数时,才会为true
val minShareRatio1 = runningTasks1.toDouble / math.max(minShare1, 1.0).toDouble
val minShareRatio2 = runningTasks2.toDouble / math.max(minShare2, 1.0).toDouble
运行的task的个数针对于minShare的比重
val taskToWeightRatio1 = runningTasks1.toDouble / s1.weight.toDouble
val taskToWeightRatio2 = runningTasks2.toDouble / s2.weight.toDouble
得到正在运行的task个数针对于pool的weight的比重
var compare: Int = 0
这里首先根据正在运行的task的个数是否已经达到调度队列中最小的分片的个数来进行排序,
如果s1中运行运行的个数小于s1的pool的配置的minShare,返回true,表示s1排序在前面.
如果s2中运行的task的个数小于s2的pool中配置的minShare(最小分片数)的值,表示s1小于s2,这时s2排序应该靠前.
if (s1Needy && !s2Needy) {
return true
} else if (!s1Needy && s2Needy) {
return false
} else if (s1Needy && s2Needy) {
这种情况表示s1与s2两个队列中,正在运行的task的个数都已经大于(不小于)了两个子调度器中配置的minShare的个数时,根据两个子调度器队列中正在运行的task的个数对应此调度器中最小分片的值所占的比重最小的一个排序更靠前
compare = minShareRatio1.compareTo(minShareRatio2)
} else {
这种情况表示s1与s2两个子调度器的队列中,正在运行的task的个数都还没有达到配置的最小分片的个数的情况,比较两个队列中正在运行的task的个数对应调度器队列的weigth的占比,最小的一个排序更靠前
compare = taskToWeightRatio1.compareTo(taskToWeightRatio2)
}
if (compare < 0) {
true
} else if (compare > 0) {
false
} else {
如果两个根据上面的计算,排序值都相同,就看看这两个调度器的名称,按名称的字节序来排序了.
s1.name < s2.name
}
}
}
spark的task调度器(FAIR公平调度算法)的更多相关文章
- 调度器&负载均衡调度算法整理
一.Linux 调度器 Linux中进程调度器已经经过很多次改进了,目前核心调度器是在CFS(Completely Fair Scheduler),从2.6.23开始被作为默认调度器.用作者Ing ...
- Volcano成Spark默认batch调度器
摘要:对于Spark用户而言,借助Volcano提供的批量调度.细粒度资源管理等功能,可以更便捷的从Hadoop迁移到Kubernetes,同时大幅提升大规模数据分析业务的性能. 2022年6月16日 ...
- Yarn 公平调度器案例
目录 公平调度器案例 需求 配置多队列的公平调度器 1 修改yarn-site.xml文件,加入以下从参数 2 配置fair-scheduler.xml 3 分发配置文件重启yarn 4 测试提交任务 ...
- YARN调度器(Scheduler)详解
理想情况下,我们应用对Yarn资源的请求应该立刻得到满足,但现实情况资源往往是有限的,特别是在一个很繁忙的集群,一个应用资源的请求经常需要等待一段时间才能的到相应的资源.在Yarn中,负责给应用分配资 ...
- Linux IO Scheduler(Linux IO 调度器)
每个块设备或者块设备的分区,都对应有自身的请求队列(request_queue),而每个请求队列都可以选择一个I/O调度器来协调所递交的request.I/O调度器的基本目的是将请求按照它们对应在块设 ...
- Hadoop的调度器总结
Hadoop的调度器总结 随着MapReduce的流行,其开源实现Hadoop也变得越来越受推崇.在Hadoop系统中,有一个组件非常重要,那就是调度器,它的作用是将系统中空闲的资源按一定策略分配给作 ...
- Linux IO 调度器
Linux IO Scheduler(Linux IO 调度器) 每个块设备或者块设备的分区,都对应有自身的请求队列(request_queue),而每个请求队列都可以选择一个I/O调度器来协调所递交 ...
- Linux IO Scheduler(Linux IO 调度器)【转】
每个块设备或者块设备的分区,都对应有自身的请求队列(request_queue),而每个请求队列都可以选择一个I/O调度器来协调所递交的request.I/O调度器的基本目的是将请求按照它们对应在块设 ...
- Linux I/O 调度器
每个块设备或者块设备的分区,都对应有自身的请求队列, 而每个请求队列都可以选择一个I/O调度器来协调所递交的.I/O调度器的基本目的是将请求按照它们对应在块设备上的扇区号进行排列,以减少磁头的移动, ...
随机推荐
- 面向对象中特殊方法的补充、isinstance/issubclass/type、方法和函数、反射
一.面向对象中特殊方法的补充 1.__str__ 能将对象名改成你想要的字符串,但是类型还是类 class Foo(object): def __init__(self): pass def func ...
- 【转】Python源码学习Schedule
原文:https://www.cnblogs.com/angrycode/p/11433283.html ----------------------------------------------- ...
- No qualifying bean of type 'org.springframework.scheduling.TaskScheduler' available
2019-07-22 17:59:30,966 [DEBUG] [localhost-startStop-1] [ScheduledAnnotationBeanPostProcessor.java : ...
- SQL SERVER表压缩
概述 SQL Server的主要性能取决于磁盘I/O效率,SQL Server .2008提供了数据压缩功能来提高磁盘I/O效率.表压缩意味着减小数据的磁盘占有量,所以压缩可以用在堆表.聚集索引的表. ...
- CentOS7.x安装nodejs-10.16.3
Wiki.js 安装 需要用到nodejs,本文介绍下快速安装nodejs 环境: 操作系统:CentOS7.6 nodejs版本:10.16.3 官网:https://nodejs.org/en/ ...
- ask confirm shell
#/bin/bash BASEDIR=$(cd $() && pwd) cd $BASEDIR>/dev/null usage="Usage: $0 -o/--org ...
- 利用 BackgroundService 固定时间间隔执行某动作
继承 BackgroundService 类: 为什么会写这个东西呢?本人在写消息队列的时候思考过一个问题——比如,每5秒从队列里面取一条消息(一条消息里面又包含了1000条数据),要把这1000条数 ...
- 关于 js 函数参数的this
先看一道面试题: var number = 10; function fn() { console.log(this.number); } var obj = { number: 2, show: f ...
- scrapy vs requests+beautifulsoup
两种爬虫模式比较: 1.requests和beautifulsoup都是库,scrapy是框架. 2.scrapy框架中可以加入requests和beautifulsoup. 3.scrapy基于tw ...
- NetworkX系列教程(4)-设置graph的信息
小书匠Graph图论 要画出美观的graph,需要对graph里面的节点,边,节点的布局都要进行设置,具体可以看官方文档:Adding attributes to graphs, nodes, and ...