Hive安装配置详解步骤以及hive使用mysql配置
Hive是一个数据仓库基础工具在Hadoop中用来处理结构化数据。它架构在Hadoop之上,总归为大数据,并使得查询和分析方便。并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
环境介绍:
hadoop:3.2.0
jdk:1.8
Linux:centos7
mysql:5.6
1.mysql安装配置
wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm
rpm -ivh mysql-community-release-el7-.noarch.rpm
执行yum install -y mysql -server
Systemctl start mysql
完成
2.配置创建hive需要的数据库以及账户
create database hive; create user 'hadoop1'@'localhost' identified by ''; grant all privileges on *.* to 'hadoop1'@'localhost' with grant option;
3.下载hive
wget http://mirror.bit.edu.cn/apache/hive/hive-3.1.1/apache-hive-3.1.1-bin.tar.gz
tar xzvf apache-hive-3.1.1-bin.tar.gz
cd hive-3.1.1
4.配置hive以及hadoop的变量记得source 让bianl生效。
vim /etc/profile
export HIVE_HOME=/home/apache-hive-3.1.-bin
export HADDOP_HOME=/home//home/hadoop-3.2.0
export PATH=.:${JAVA_HOME}/bin/:$HIVE_HOME/bin:$HADOOP_HOME/bin:$PATH
5.编辑hive-site.xml 和hive-env.sh文件
此文件是通过hive-default.xml.template 复制出来的,需要删除原文件所有内容后新增如下配置,因为hive在启动的时候会加载两个文件,default.xml和Hive-site.xml,所以如果直接新增一下内容是无效的。
[root@localhost conf]# cat hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hadoop</value>####用户注意修改
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value></value>####密码注意修改
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
</configuration>
[root@localhost conf]#
hive-env.sh

6.在初始化前查看是否有mysql的connectorjar包如果没有请下载
[root@localhost apache-hive-3.1.1-bin]# ll lib/mysql-
mysql-connector-java-5.1.47.jar
下载地址:http://central.maven.org/maven2/mysql/mysql-connector-java/找对应的下载即可。
wget http://central.maven.org/maven2/mysql/mysql-connector-java/5.1.47/mysql-connector-java-5.1.47.jar
7.初始化hive
[root@localhost apache-hive-3.1.-bin]# bin/schematool -dbType mysql -initSchema
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/apache-hive-3.1.-bin/lib/log4j-slf4j-impl-2.10..jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/hadoop-3.2./share/hadoop/common/lib/slf4j-log4j12-1.7..jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: hadoop
Starting metastore schema initialization to 3.1.
Initialization script hive-schema-3.1..mysql.sql
······································此处省略 太多log了----------
Initialization script completed
schemaTool completed
8.出现初始化完成之后可以去mysql数据库中查看hive下的表
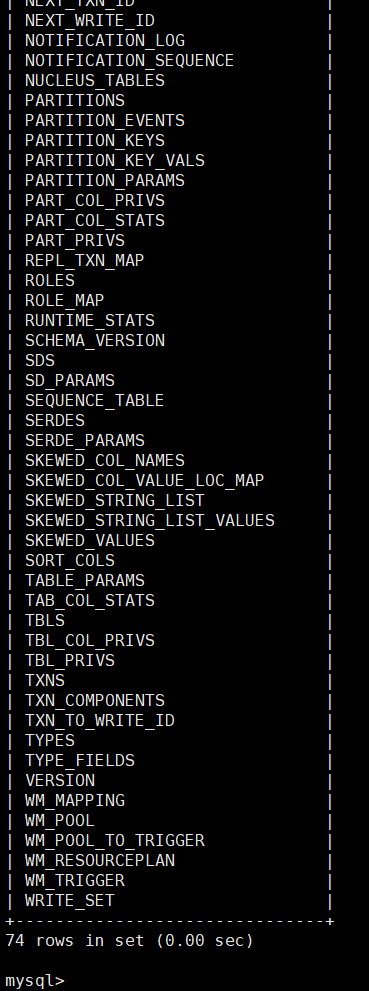
会出现74张表。到此hive的配置和部署完成。
Hive安装配置详解步骤以及hive使用mysql配置的更多相关文章
- Apollo的docker配置详解步骤
Apollo 的docker配置 基础环境 centOS7 + Docker服务 + mysql服务 1. 下载Apollo的包 git clone https://github.com/ctripc ...
- 缓存varnish的管理及配置详解
一 工作原理 在当前主流的Web服务架构体系中,Cache担任着越来越重要的作用.常见的基于浏览器的C/S架构,Web Cache更是节约服务器资源的关键.而最近几年由FreeBSD创始人之一Kamp ...
- 华为ensp模拟某公司网络架构及配置详解
1.先晒下架构图,二层设备省略..... 2.下面开始具体配置详解 2.1.从路由器开始配置,先用远程工具远程AR1220F-S路由,secureCRT ,putty,xshell任选其中一个均可,功 ...
- (网页)Java日志记录框架Logback配置详解(企业级应用解决方案)(转)
转自CSDN: 前言 Logback是现在比较流行的一个日志记录框架,它的配置比较简单学习成本相对较低,所以刚刚接触该框架的朋友不要畏惧,多花点耐心很快就能灵活应用了.本篇博文不会具体介绍Logbac ...
- ThinkPHP 配置详解
3.0 ThinkPHP配置详解 3.1 入口文件的配置 一般不建议在入口文件做过多的配置,但可以重新定义一些系统常量,以下简单介绍几个常用的系统常量. 1.APP_PATH 默认情况下,框架的项 ...
- Hive的配置详解和日常维护
Hive的配置详解和日常维护 一.Hive的参数配置详解 1>.mapred.reduce.tasks 默认为-1.指定Hive作业的reduce task个数,如果保留默认值,则Hive 自 ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
转自:http://blog.csdn.net/iamdll/article/details/20998035 分类: 分布式 2014-03-11 10:31 156人阅读 评论(0) 收藏 举报 ...
- libCURL开源库在VS2010环境下编译安装,配置详解
libCURL开源库在VS2010环境下编译安装,配置详解 转自:http://my.oschina.net/u/1420791/blog/198247 http://blog.csdn.net/su ...
随机推荐
- CentOS7 配置sendmial + PHP mail函数发送邮件
https://blog.csdn.net/jiabangok/article/details/51840556
- Django:使用模态框新增数据,成功后提示“提交成功”,并刷新表格bootstrap-table数据
废话不说先看图: 代码实现: 前台代码: {% load staticfiles %} <!DOCTYPE html> <html lang="en"> ...
- 推荐两本CCF教材
希望学习电脑程序设计的同学,可以购买如下两本教材,先学习入门篇,再学习基础篇.淘宝.当当.京东均有售.建议选择比较靠谱的网店,避免买到盗版书.
- 高级UI-SVG
栅格图可以实现图片的清晰显示,但这也意味着如果要在各种设备上使用栅格图,那么在使用的时候就会产生为了适配各种尺寸的设备而增加大量不同规格的栅格图,这也直接导致了资源文件体积的增大,矢量图就不存在这个问 ...
- 高级UI-CardView
CardView是在Android 5.0推出的新控件,为了兼容之前的版本,将其放在了v7包里面,在现在扁平化设计潮流的驱使下,越来越多的软件使用到了CardView这一控件,那么这篇文章就来看看Ca ...
- vue 跨域简记
0.服务端设置 app.use(function(req, res, next){ //设置跨域访问 res.header('Access-Control-Allow-Origin', '*'); r ...
- Extjs locked无效,使用enableLocking即可
一.前言 在使用 extjs 做表格时,由于表格的列太多,我们需要设置一些固定列来查看数据,所以我们需要用到 locked 属性.普通加载 columns 的列是有效的,如果是动态加载的话,使用 lo ...
- Maven工具-简介
Maven工具-简介 定义 ①maven是一款服务于java平台的自动化构建工具 make→Ant→maven→Gradle ②构建 [1]概念:以"java源文件"." ...
- 转:对JavaScript中闭包的理解
关于 const let var 总结: 建议使用 let ,而不使用var,如果要声明常量,则用const. ES6(ES2015)出现之前,JavaScript中声明变量只有 ...
- python 之 前端开发(盒子模型、页面布局、浮动、定位、z-index、overflow溢出)
11.312 盒子模型 HTML文档中的每个元素都被比喻成矩形盒子, 盒子模型通过四个边界来描述:margin(外边距),border(边框),padding(内填充),content(内容区域),如 ...