jdk1.8-LinkedList源码分析
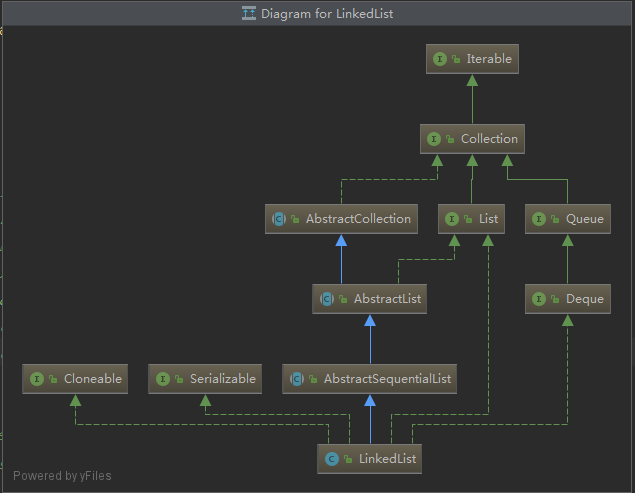
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
继承抽象的AbstractSequentiaList类,供了一个基本的List接口实现,为实现序列访问的数据储存结构的提供了所需要的最小化的接口实现。.
/**
* 当前链表长度
*/
transient int size = 0;
/**
* 头结点
*/
transient Node<E> first;
/**
* 尾结点
*/
transient Node<E> last;
/**
* 静态内部类,它的创建是不需要依赖于外围类,可以被实例化
* @param <E>
*/
private static class Node<E> {
//当前结点值
E item;
//下一结点
Node<E> next;
//上一节点
Node<E> prev;
//构造函数初始化
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
分析:我们知道java的LinkedList是个双向链表,java没有指针,那么是怎么找到前一个元素结点和后一个元素结点呢?从上面的代码很容易就可以看出,其实就是在Node类的成员属性下直接记录了下一个结点Node<E> next 和 上一个结点 Node<E> prev,从而达到模拟指针的效果。
/**
* Constructs an empty list.
*/
public LinkedList() {
}
/**
* 带参构造方法,传入集合
*/
public LinkedList(Collection<? extends E> c) {
//构造方法
this();
//添加方法
addAll(c);
}
分析:这里将集合直接传入addAll()方法
/**
* 参数为前链表长度和集合
*/
public boolean addAll(Collection<? extends E> c) {
return addAll(size, c);
}
分析:这里传入了当前链表长度和集合
/**
* 从索引为index结点的尾部,开始插入所有集合的元素
*/
public boolean addAll(int index, Collection<? extends E> c) {
//检验长度是否在链表长度区间
checkPositionIndex(index);
//将集合转为数组
Object[] a = c.toArray();
//数组长度
int numNew = a.length;
//如果等于0直接返回false
if (numNew == 0)
return false;
//两个记录结点
Node<E> pred, succ;
//如果当前传入的长度等于链表当前最大长度
if (index == size) {
//succ结点等于null
succ = null;
//pred结点等于尾结点
pred = last;
} else {
//返回index索引的结点
succ = node(index);
//pred记录等于index索引结点的上一个结点
pred = succ.prev;
}
//遍历数组
for (Object o : a) {
//将值强转为E类型
@SuppressWarnings("unchecked") E e = (E) o;
//每次循环new一个newNode结点,newNode结点的值等于e,newNode上一结点prev等于pred记录结点,newNode下一节点等于null
//其实这个newNode就是pred的下一个结点,因为newNode的上一节点等于pred
Node<E> newNode = new Node<>(pred, e, null);
//如果当前记录结点pred等于null
if (pred == null)
//则头结点等于newNode
first = newNode;
else
//当前记录pred的下一节点等于newNode,相当于把succ记录结点给覆盖了
pred.next = newNode;
//当前记录结点更新为newNode,也就是相当于链表往后移动一位
pred = newNode;
}
if (succ == null) {
//尾结点等于当前记录结点pred
last = pred;
} else {
//重新把pred结点下一个结点赋值为succ记录结点
pred.next = succ;
//并且让succ记录结点的上一个结点等于最新的pred记录结点
succ.prev = pred;
}
//链表的长度加上集合的长度
size += numNew;
//修改次数加1
modCount++;
return true;
}
分析:首先我们要知道这个addAll()方法是从索引为index结点开始向后插入元素的,链表的索引是从0开始的。那么到底是怎么插入元素的呢?我们来逐步分析下:
//检验长度是否在链表长度区间
checkPositionIndex(index);
//将集合转为数组
Object[] a = c.toArray();
//数组长度
int numNew = a.length;
//如果等于0直接返回false
if (numNew == 0)
return false;
分析:这里这先校验下传入的index长度是否在链表区间(0到size),然后将集合转为数组,如果数组长度等于0的话,直接返回了。
//两个记录结点
Node<E> pred, succ;
//如果当前传入的索引等于链表当前最大长度
if (index == size) {
//succ结点等于null
succ = null;
//pred结点等于尾结点
pred = last;
} else {
//返回index索引的结点
succ = node(index);
//pred记录等于index索引结点的上一个结点
pred = succ.prev;
}
分析:两个记录结点Node<E> pred,succ非常重要,它是为了方便我们我们操作链表的。
/**
* 传入index长度,链表返回索引为index的node结点(注意这里的链表索引也是从0开始)
* 如果传入的长度小于链表长度一遍,那么从链表头结点开始遍历
* 如果传入的长度大于或等于链表长度的一半,那么从链表的尾结点开始遍历
*/
Node<E> node(int index) {
//如果传入的长度小于链表长度的一半(size >> 1链表长度除以2,这种写法运算速度稍快,可以根据实际需求应用)
if (index < (size >> 1)) {
//当前记录结点等于头结点
Node<E> x = first;
//从下表为0开始遍历到索引为index-1
//这里注意下从0到index-1需要迭代7次
for (int i = 0; i < index; i++)
//当前记录结点等于下一节点
x = x.next;
//所以返回的是索引为indx的点!!
return x;
} else {
//如果传入的长度大于或者等于当前链表长度的一半
//当前记录结点等于尾结点
Node<E> x = last;
//从链表末尾开始往前遍历
for (int i = size - 1; i > index; i--)
//当前记录结点等于上一节点
x = x.prev;
//返回索引为index的点!
return x;
}
}
//两个记录结点
Node<E> pred, succ;
这两个结点的含义,succ代表当前传入索引index的结点,pred代表索引index结点的上一个结点,这两个结点是为了我们方便操作链表。
//遍历数组
for (Object o : a) {
//将值强转为E类型
@SuppressWarnings("unchecked") E e = (E) o;
//每次循环new一个newNode结点,newNode结点的值等于e,newNode上一结点prev等于pred记录结点,newNode下一节点等于null
//其实这个newNode就是pred的下一个结点,因为newNode的上一节点等于pred
Node<E> newNode = new Node<>(pred, e, null);
//如果当前记录结点pred等于null
if (pred == null)
//则头结点等于newNode
first = newNode;
else
//当前记录pred的下一节点等于newNode,相当于把succ记录结点给覆盖了
pred.next = newNode;
//当前记录结点更新为newNode,也就是相当于链表往后移动一位
pred = newNode;
}
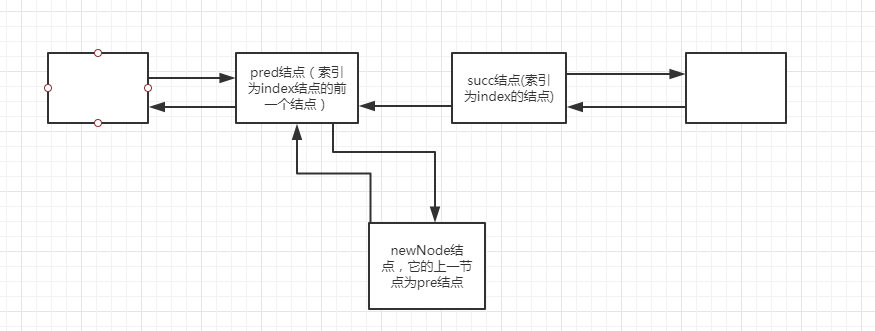
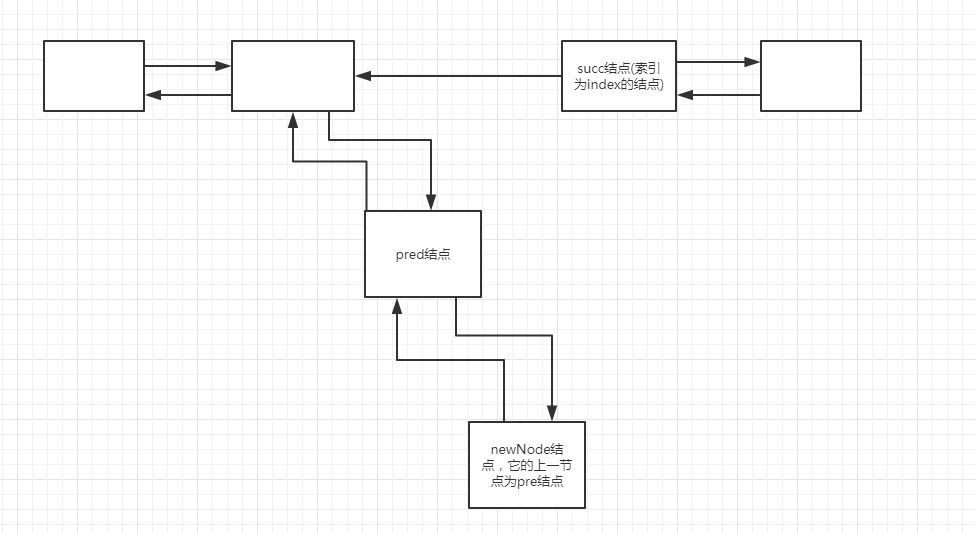
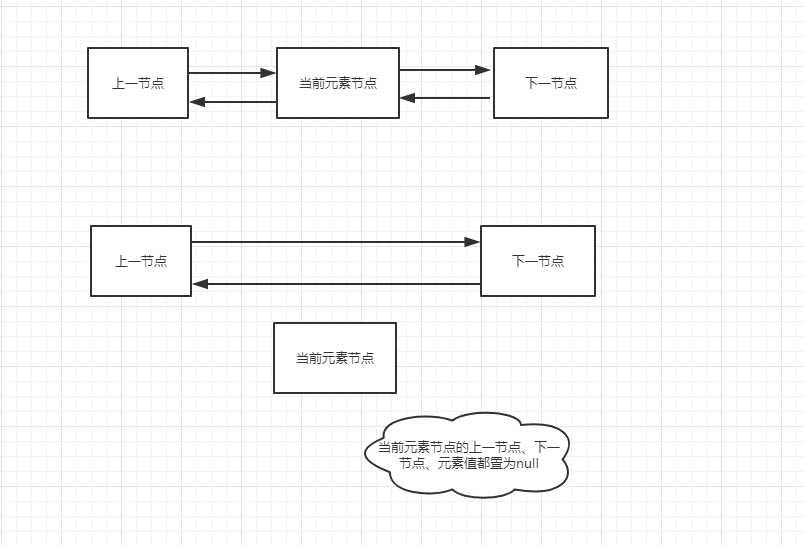
分析:前面将集合转为了数组,这里遍历数组,每次循环将遍历的值转为类型E(泛型)。new一个名为newNode的结点,构造函数初始化,newNode结点的上一结点等于pred结点(pred代表索引index结点的上一个结点),newNode结点的值为e,newNode结点的下一节点为null。看懂了没,哈哈,其实这个newNode相当于“覆盖”了succ结点(当前索引为index的结点),这里画个图给大家理解下吧。

if (pred == null)
//则头结点等于newNode
first = newNode;
else
//当前记录pred的下一节点等于newNode,相当于把succ记录结点给覆盖了
pred.next = newNode;

if (succ == null) {
//尾结点等于当前记录结点pred
last = pred;
} else {
//重新把pred结点下一个结点赋值为succ记录结点
pred.next = succ;
//并且让succ记录结点的上一个结点等于最新的pred记录结点
succ.prev = pred;
}
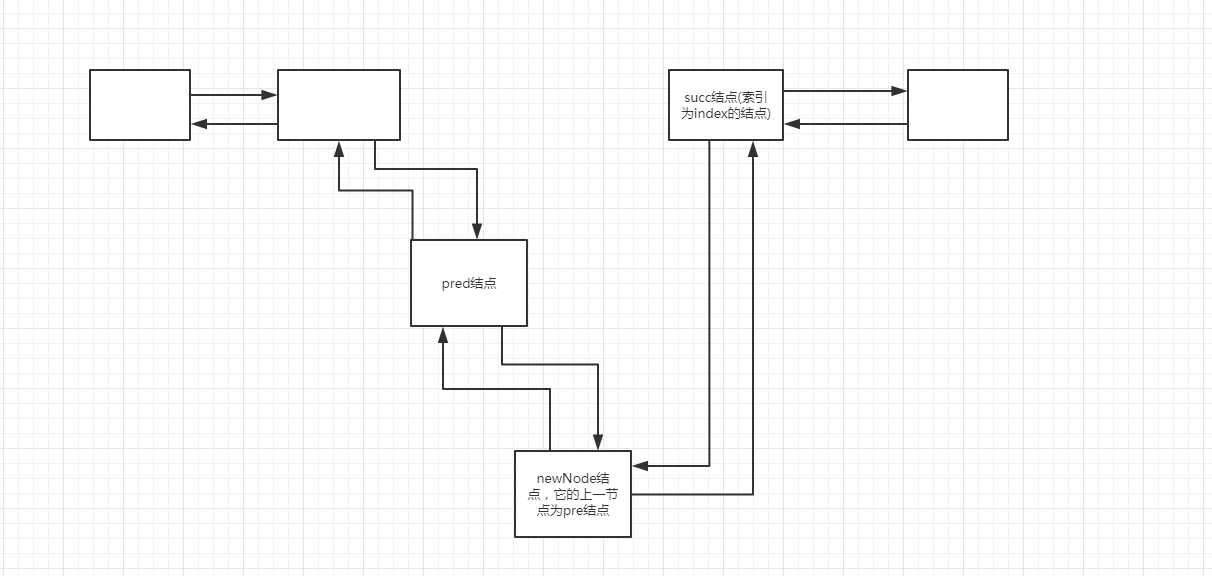
分析:当传入的index等于链表长度size时,链表索引是从0开始的,所以超出链表索引,那么当前索引succ == null,则直接让pred等于尾结点(很好理解吧?succ的上一个结点不就是索引为index-1的尾结点)。如果不等于null,把pred(此时的pred等于最后一个newNode结点)下一个结点指向succ结点,succ的上一个结点指向pred,效果如下图:
//链表的长度加上集合的长度
size += numNew;
//修改次数加1
modCount++;
return true;
分析:链表长度加上集合的长度,修改次数加1,返回
/**
* 往链表末尾添加元素
*/
public boolean add(E e) {
linkLast(e);
return true;
}
分析:传入元素的值,调用linkLast()方法
/**
* Links e as last element.
*/
void linkLast(E e) {
//尾结点
final Node<E> l = last;
//new一个新结点,上一个结点等于尾结点,结点值等于e,下一个结点等于null
final Node<E> newNode = new Node<>(l, e, null);
//尾结点等于新结点
last = newNode;
//链表没有元素,则尾结点为null
if (l == null)
//让头结点等于新结点
first = newNode;
else
//否则,尾结点的下一个结点等于新结点
l.next = newNode;
//链表长度加1
size++;
//修改次数加1
modCount++;
}
分析:这里添加和上面思想其实是一致的,所以就不详解了和画图了,直接看上面我写的注释。
/**
* 根据索引删除结点
*/
public E remove(int index) {
//检查索引是否越界
checkElementIndex(index);
//node(index)索引为index的node结点,传入unLink()方法
return unlink(node(index));
}
/**
* 删除指定节点元素
*/
E unlink(Node<E> x) {
// assert x != null;
//当前节点元素值
final E element = x.item;
//当前节点的下一节点
final Node<E> next = x.next;
//当前节点的上一节点
final Node<E> prev = x.prev;
//如果当前节点的上一节点prev为null
if (prev == null) {
//头节点等于下一节点
first = next;
} else {
//上一节点成员变量下一节点改为next
prev.next = next;
//当前节点的上一节点置为null方便回收
x.prev = null;
}
//如果当前节点的下一节点next为null(也就是链表最后一个元素)
if (next == null) {
//链表的尾节点等于当前节点的上一节点prev
last = prev;
} else {
//当前节点的下一节点next的成员变量prev等于当前节点的上一节点prev
next.prev = prev;
//当前节点的下一节点置为null
x.next = null;
}
//当前节点的值置为null
x.item = null;
//当前链表长度减1
size--;
//修改次数加1
modCount++;
//返回当前节点元素值
return element;
}
分析:这里的删除指定节点,其实道理也是类似,通过改变上一节点和下一节点各自的成员变量引用从而达到删除当前元素节点的效果。
jdk1.8-LinkedList源码分析的更多相关文章
- Java入门系列之集合LinkedList源码分析(九)
前言 上一节我们手写实现了单链表和双链表,本节我们来看看源码是如何实现的并且对比手动实现有哪些可优化的地方. LinkedList源码分析 通过上一节我们对双链表原理的讲解,同时我们对照如下图也可知道 ...
- ArrayList 和 LinkedList 源码分析
List 表示的就是线性表,是具有相同特性的数据元素的有限序列.它主要有两种存储结构,顺序存储和链式存储,分别对应着 ArrayList 和 LinkedList 的实现,接下来以 jdk7 代码为例 ...
- Java集合之LinkedList源码分析
概述 LinkedLIst和ArrayLIst一样, 都实现了List接口, 但其内部的数据结构不同, LinkedList是基于链表实现的(从名字也能看出来), 随机访问效率要比ArrayList差 ...
- java集合系列之LinkedList源码分析
java集合系列之LinkedList源码分析 LinkedList数据结构简介 LinkedList底层是通过双端双向链表实现的,其基本数据结构如下,每一个节点类为Node对象,每个Node节点包含 ...
- HashMap实现原理(jdk1.7),源码分析
HashMap实现原理(jdk1.7),源码分析 HashMap是一个用来存储Key-Value键值对的集合,每一个键值对都是一个Entry对象,这些Entry被以某种方式分散在一个数组中,这个数 ...
- Java集合基于JDK1.8的LinkedList源码分析
上篇我们分析了ArrayList的底层实现,知道了ArrayList底层是基于数组实现的,因此具有查找修改快而插入删除慢的特点.本篇介绍的LinkedList是List接口的另一种实现,它的底层是基于 ...
- LinkedList源码分析(jdk1.8)
LinkedList概述 LinkedList 是 Java 集合框架中一个重要的实现,我们先简述一下LinkedList的一些特点: LinkedList底层采用的双向链表结构: LinkedL ...
- LinkedList(JDK1.8)源码分析
双向循环链表 双向循环链表和双向链表的不同在于,第一个节点的pre指向最后一个节点,最后一个节点的next指向第一个节点,也形成一个"环".而LinkedList就是基于双向循环链 ...
- List中的ArrayList和LinkedList源码分析
List是在面试中经常会问的一点,在我们面试中知道的仅仅是List是单列集合Collection下的一个实现类, List的实现接口又有几个,一个是ArrayList,还有一个是LinkedLis ...
- LinkedList 源码分析(JDK 1.8)
1.概述 LinkedList 是 Java 集合框架中一个重要的实现,其底层采用的双向链表结构.和 ArrayList 一样,LinkedList 也支持空值和重复值.由于 LinkedList 基 ...
随机推荐
- python 示例代码2
示例2:变量赋值,打印拼接(var.py) 变量定义的规则: 变量名只能是字母.数字或下划线的任意组合 变量名的第一个字符不能是数字 以下关键字不能声明为变量名 ['and', 'as', 'asse ...
- springboot-拦截器redis注入空问题解决
转自:https://blog.csdn.net/liuyang1835189/article/details/81056162 主要问题是在拦截器的配置类里面,配置的类,spring容器无法获取,所 ...
- CSS引入外部字体方法,附可用demo
有时候我们做的页面需要用到一些更好看的字体又不想用图片代替,图片会影响加载速度则使用外部字体来显示但是直接通过font-family又不一定全部都行这就需要我们在css中进行定义并且引入字体文件路径然 ...
- 题解 [USACO Mar08] 奶牛跑步
[USACO Mar08] 奶牛跑步 Description Bessie准备用从牛棚跑到池塘的方法来锻炼. 但是因为她懒,她只准备沿着下坡的路跑到池塘,然后走回牛棚. Bessie也不想跑得太远,所 ...
- 【JDK】MacBook 安装JDK及卸载步骤
一.安装步骤 1.官网下载jdk https://www.oracle.com/technetwork/java/javase/downloads/index.html 勾选 Accept Lic ...
- 51 Nod 1072 威佐夫游戏
https://baike.baidu.com/item/%E5%A8%81%E4%BD%90%E5%A4%AB%E5%8D%9A%E5%BC%88/19858256?fr=aladdin&f ...
- Inter IPP & Opencv + codeblocks 在centos 环境下的配置
一.先安装codeblocks wget http://dl.fedoraproject.org/pub/epel/7/x86_64/Packages/e/epel-release-7-12.noar ...
- uni-app 尺寸单位
uni-app 支持的通用 css 单位包括 px.rpx px 即屏幕像素 rpx 即响应式px,一种根据屏幕宽度自适应的动态单位.以750宽的屏幕为基准,750rpx恰好为屏幕宽度.屏幕变宽,rp ...
- 【Blog怎么玩】什么叫EntryName友好地址名?
EntryName友好地址名 其实就是你这个页面的别名,如果设置的好的话,在SEO搜索中,会更清晰的显示出来. 好处1:清晰的URL 比如我有一篇展示可爱兔子的博文,我想让它的网址清晰的显示出来,而不 ...
- vue-cli 3x 的使用
当我们使用 npm 下载过文件之后,里面就会有缓存 我们要使用 npm cache clean --force 来清除缓存 创建项目:vue create 文件名 然后:cd 文件名 启动程序:npm ...