selenium 模拟登陆豆瓣,爬取武林外传的短评
selenium 模拟登陆豆瓣,爬去武林外传的短评:
在最开始写爬虫的时候,抓取豆瓣评论,我们从F12里面是可以直接发现接口的,但是最近豆瓣更新,数据是JS异步加载的,所以没有找到合适的方法爬去,于是采用了selenium来模拟浏览器爬取。
豆瓣登陆也是改了样式,我们可以发现登陆页面是在另一个frame里面
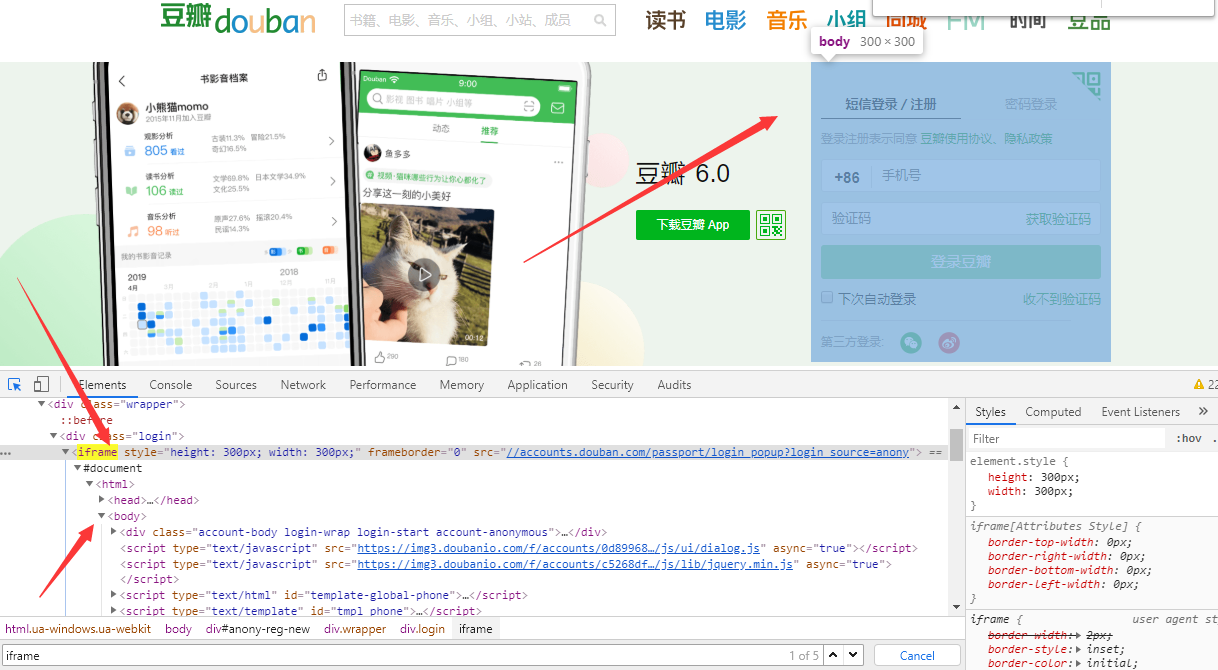
所以代码如下:
# -*- coding:utf-8 -*-
# 导包
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# 创建chrome参数对象
opt = webdriver.ChromeOptions()
# 把chrome设置成无界面模式,不论windows还是linux都可以,自动适配对应参数
opt.set_headless()
# 用的是谷歌浏览器
driver = webdriver.Chrome(options=opt)
driver=webdriver.Chrome()
# 登录豆瓣网
driver.get("http://www.douban.com/") # 切换到登录框架中来
driver.switch_to.frame(driver.find_elements_by_tag_name("iframe")[0])
# 点击"密码登录"
bottom1 = driver.find_element_by_xpath('/html/body/div[1]/div[1]/ul[1]/li[2]')
bottom1.click() # # 输入密码账号
input1 = driver.find_element_by_xpath('//*[@id="username"]')
input1.clear()
input1.send_keys("xxxxx") input2 = driver.find_element_by_xpath('//*[@id="password"]')
input2.clear()
input2.send_keys("xxxxx") # 登录
bottom = driver.find_element_by_class_name('account-form-field-submit ')
bottom.click()
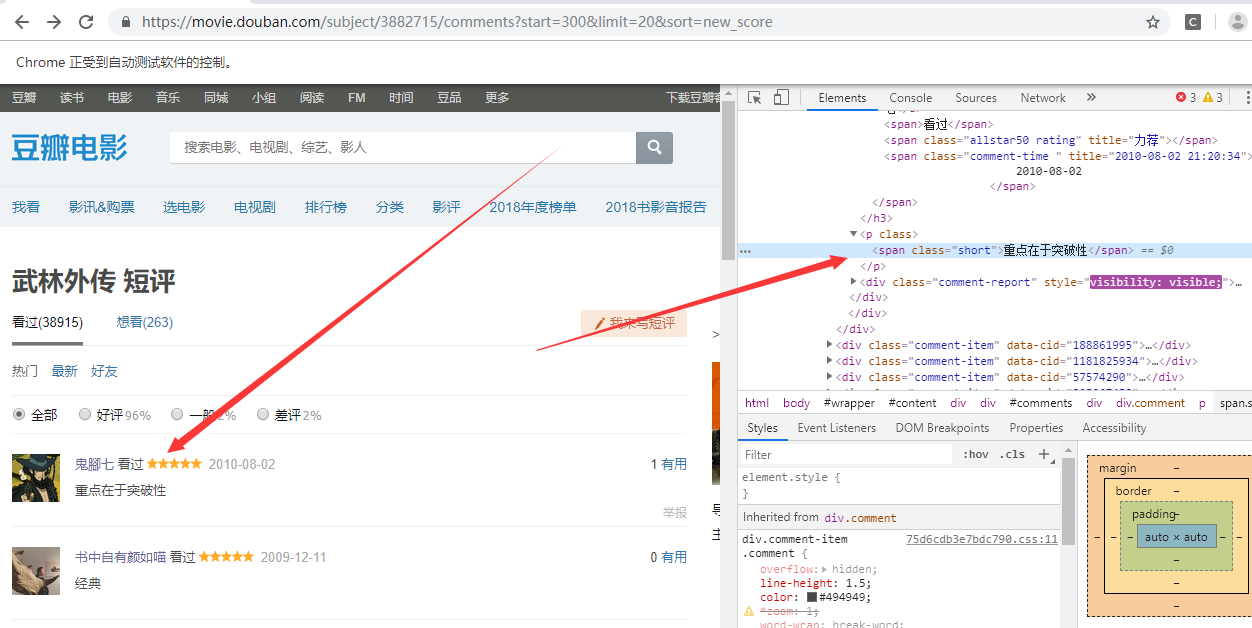
然后跳转到评论界面 https://movie.douban.com/subject/3882715/comments?sort=new_score
点击下一页发现url变化 https://movie.douban.com/subject/3882715/comments?start=20&limit=20&sort=new_score 所以我们观察到变化后可以直接写循环
获取用户的姓名
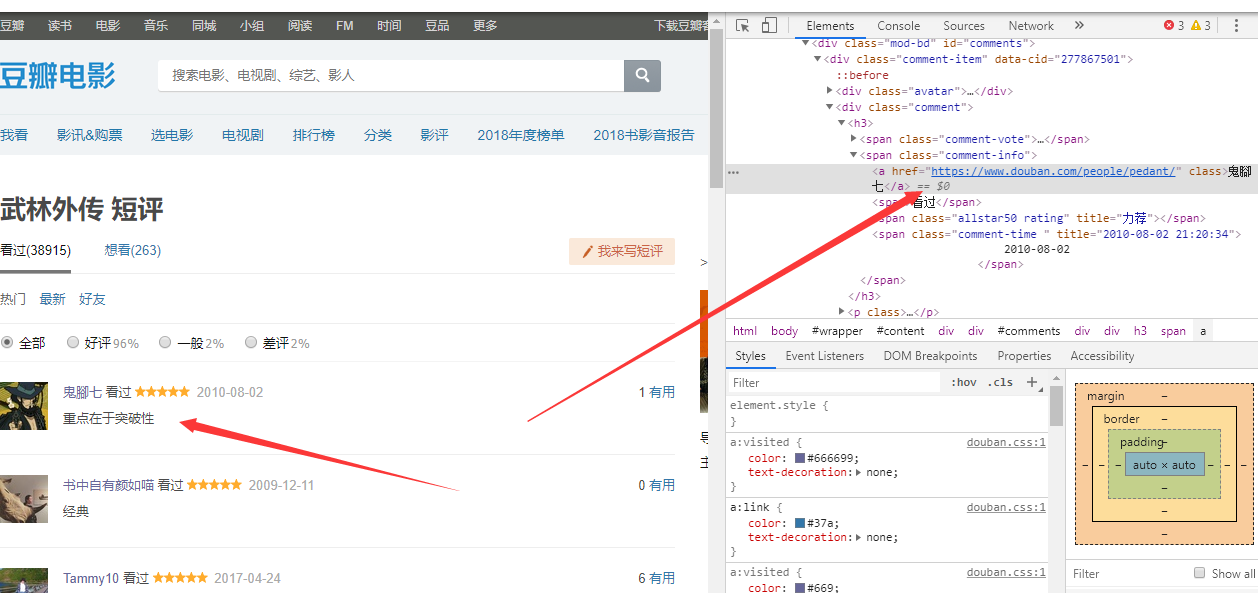
driver.find_element_by_xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a'.format(str(i))).text
用户的评论
driver.find_element_by_xpath('//*[@id="comments"]/div[{}]/div[2]/p/span'.format(str(i))).text
然后我们想要知道用户的居住地:
#获取用户的url然后点击url获取居住地
userInfo=driver.find_element_by_xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a'.format(str(i))).get_attribute('href')
driver.get(userInfo)
try:
userLocation = driver.find_element_by_xpath('//*[@id="profile"]/div/div[2]/div[1]/div/a').text
print("用户的居之地是: ")
print(userLocation)
except Exception as e:
print(e)
这里要注意有些用户没有写居住地,所以必须要捕获异常
完整代码
# -*- coding:utf-8 -*-
# 导包
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys class doubanwlwz_spider():
def __init__(self):
# 创建chrome参数对象
opt = webdriver.ChromeOptions()
# 把chrome设置成无界面模式,不论windows还是linux都可以,自动适配对应参数
opt.set_headless()
# 用的是谷歌浏览器
driver = webdriver.Chrome(options=opt)
driver=webdriver.Chrome()
self.getInfo(driver)
def getInfo(self,driver):
# 切换到登录框架中来
# 登录豆瓣网
driver = driver
driver.get("http://www.douban.com/")
driver.switch_to.frame(driver.find_elements_by_tag_name("iframe")[0])
# 点击"密码登录"
bottom1 = driver.find_element_by_xpath('/html/body/div[1]/div[1]/ul[1]/li[2]')
bottom1.click()
# # 输入密码账号
input1 = driver.find_element_by_xpath('//*[@id="username"]')
input1.clear()
input1.send_keys("ZZZ2") input2 = driver.find_element_by_xpath('//*[@id="password"]')
input2.clear()
input2.send_keys("ZZZ") # 登录
bottom = driver.find_element_by_class_name('account-form-field-submit ')
bottom.click() time.sleep(1)
driver.get('https://movie.douban.com/subject/3882715/comments?start=300&limit=20&sort=new_score')
search_window = driver.current_window_handle
# pageSource=driver.page_source
# print(pageSource)
#获取用户的名字 每页20个
for i in range(1,21):
print("用户的评论是: ")
print(driver.find_element_by_xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a'.format(str(i))).text)
# 获取用户的评论
# print(driver.find_element_by_xpath('//*[@id="comments"]/div[1]/div[2]/p/span').text)
print("用户的名字是: ")
print(driver.find_element_by_xpath('//*[@id="comments"]/div[{}]/div[2]/p/span'.format(str(i))).text)
#获取用户的url然后点击url获取居住地
userInfo=driver.find_element_by_xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a'.format(str(i))).get_attribute('href')
driver.get(userInfo)
try:
userLocation = driver.find_element_by_xpath('//*[@id="profile"]/div/div[2]/div[1]/div/a').text
print("用户的居之地是: ")
print(userLocation)
except Exception as e:
print(e)
driver.back() pageNum=int(input("请输入您想要爬去的步行街的页数: "))
AAA=doubanwlwz_spider()
selenium 模拟登陆豆瓣,爬取武林外传的短评的更多相关文章
- 模拟登陆并爬取Github
因为崔前辈给出的代码运行有误,略作修改和简化了. 书上例题,不做介绍. import requests from lxml import etree class Login(object): def ...
- 模拟登陆+数据爬取 (python+selenuim)
以下代码是用来爬取LinkedIn网站一些学者的经历的,仅供参考,注意:不要一次性大量爬取会被封号,不要问我为什么知道 #-*- coding:utf-8 -*- from selenium impo ...
- Scrapy模拟登陆豆瓣抓取数据
scrapy startproject douban 其中douban是我们的项目名称 2创建爬虫文件 进入到douban 然后创建爬虫文件 scrapy genspider dou douban. ...
- Python爬虫(二十二)_selenium案例:模拟登陆豆瓣
本篇博客主要用于介绍如何使用selenium+phantomJS模拟登陆豆瓣,没有考虑验证码的问题,更多内容,请参考:Python学习指南 #-*- coding:utf-8 -*- from sel ...
- 使用Selenium&PhantomJS的方式爬取代理
前面已经爬取了代理,今天我们使用Selenium&PhantomJS的方式爬取快代理 :快代理 - 高速http代理ip每天更新. 首先分析一下快代理,如下 使用谷歌浏览器,检查,发现每个代理 ...
- 【转】详解抓取网站,模拟登陆,抓取动态网页的原理和实现(Python,C#等)
转自:http://www.crifan.com/files/doc/docbook/web_scrape_emulate_login/release/html/web_scrape_emulate_ ...
- python模拟登陆豆瓣——简单方法
学爬虫有一段时间了,前面没有总结又重装了系统,导致之前的代码和思考都没了..所以还是要及时整理总结备份.下面记录我模拟登陆豆瓣的方法,方法一登上了豆瓣,方法二重定向到了豆瓣中“我的喜欢”列表,获取了第 ...
- Selenium模拟登陆百度贴吧
Selenium模拟登陆百度贴吧 from selenium import webdriver from time import sleep from selenium.webdriver.commo ...
- 通过scrapy,从模拟登录开始爬取知乎的问答数据
这篇文章将讲解如何爬取知乎上面的问答数据. 首先,我们需要知道,想要爬取知乎上面的数据,第一步肯定是登录,所以我们先介绍一下模拟登录: 先说一下我的思路: 1.首先我们需要控制登录的入口,重写star ...
随机推荐
- Android jni/ndk编程三:native访问java
一.访问静态字段 Java层的field和method,不管它是public,还是package.private和protected,从 JNI都可以访问到,Java面向语言的封装性不见了. 静态字段 ...
- vue路由跳转到登录页
// 第一种 { path:'/', component: require('../components/Login.vue') }, // 第二种 { path: '/', redirect: '/ ...
- 使用Statement执行DML和DQL语句
import com.loaderman.util.JdbcUtil; import java.sql.Connection; import java.sql.DriverManager; impor ...
- Alert 警告
基本用法 页面中的非浮层元素,不会自动消失. Alert 组件提供四种主题,由type属性指定,默认值为info. <template> <el-alert title=" ...
- Python re 正则表达式【一】【转】
数量词的贪婪模式与非贪婪模式 正则表达式通常用于在文本中查找匹配的字符串.Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符:非贪婪的则相反,总是尝试匹配尽 ...
- 深入理解红黑树及C++实现
介绍 红黑树是一种特殊的平衡二叉树(AVL),可以保证在最坏的情况下,基本动态集合操作的时间复杂度为O(logn).因此,被广泛应用于企业级的开发中. 红黑树的性质 在一棵红黑树中,其每个结点上增加了 ...
- Python操作SQLite
1. 导入sqlite3数据库模块,从python2.5以后,sqlite3成为内置模块,不需要额外安装,只需要导入即可. import sqlite3 2.创建/打开数据库 使用connect方法打 ...
- LeetCode.1122-相对排序数组(Relative Sort Array)
这是小川的第393次更新,第427篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第258题(顺位题号是1122).给定两个数组arr1和arr2,arr2中的元素是不同的 ...
- Leetcode之动态规划(DP)专题-877. 石子游戏(Stone Game)
Leetcode之动态规划(DP)专题-877. 石子游戏(Stone Game) 亚历克斯和李用几堆石子在做游戏.偶数堆石子排成一行,每堆都有正整数颗石子 piles[i] . 游戏以谁手中的石子最 ...
- Leetcode之动态规划(DP)专题-931. 下降路径最小和(Minimum Falling Path Sum)
Leetcode之动态规划(DP)专题-931. 下降路径最小和(Minimum Falling Path Sum) 给定一个方形整数数组 A,我们想要得到通过 A 的下降路径的最小和. 下降路径可以 ...