使用Selenium&PhantomJS的方式爬取代理
前面已经爬取了代理,今天我们使用Selenium&PhantomJS的方式爬取快代理 :快代理 - 高速http代理ip每天更新。
首先分析一下快代理,如下
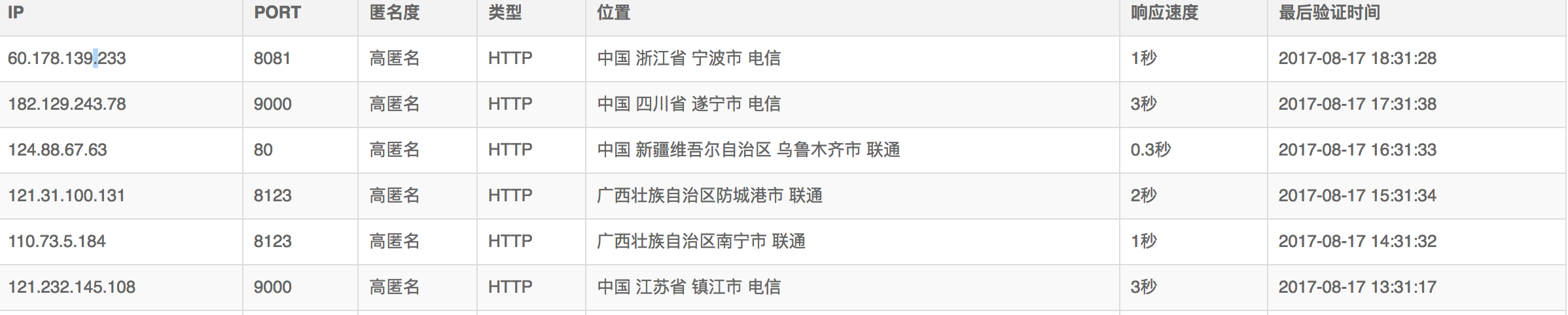
使用谷歌浏览器,检查,发现每个代理信息都在tr里面,每个tr里面包含多个td,就是IP的信息。
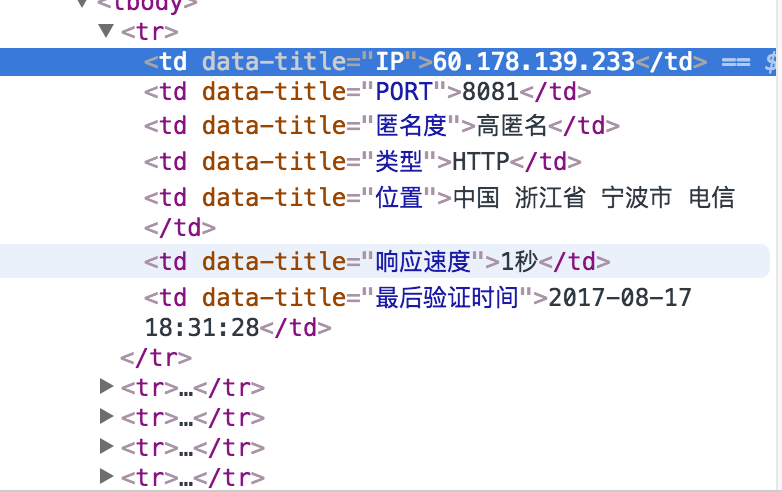
这个结构我们可以通过多种方法抓取,例如bs4、xpath、selenium等
这里我们演示selenium方法。具体解释在下面代码中都有的。
from selenium import webdriver class Item(object):
'''
模拟scrapy框架
写item类
用以表示每个代理
'''
ip = None #IP地址
port = None #端口
anonymous = None #是否匿名
type = None #http 或者https
local = None #物理地址
speed = None #速度 class GetProxy(object):
def __init__(self):
self.starturl = 'http://www.kuaidaili.com/free/inha/'
self.urls = self.get_urls()
self.proxylist = self.get_proxy_list(self.urls)
self.filename = 'proxy.txt'
self.saveFile(self.filename,self.proxylist) def get_urls(self):
'''
:return: 返回代理url列表
'''
urls = []
for i in range(1,3):
url = self.starturl + str(i)
urls.append(url)
return urls def get_proxy_list(self,urls):
'''
爬取代理列表
:param urls:
:return:
'''
browser = webdriver.PhantomJS()
proxy_list = [] for url in urls:
browser.get(url) # 通过get方法打开
browser.implicitly_wait(3)
elements = browser.find_elements_by_xpath('//tbody/tr') #找到每个代理的位置
for element in elements:
item = Item()
item.ip = element.find_element_by_xpath('./td[1]').text
item.port = element.find_element_by_xpath('./td[2]').text
item.anonymous = element.find_element_by_xpath('./td[3]').text
item.local = element.find_element_by_xpath('./td[4]').text
item.speed = element.find_element_by_xpath('./td[5]').text
print(item.ip)
proxy_list.append(item) browser.quit()
return proxy_list def saveFile(self,filename,proxy_list):
'''
将爬取的信息保存到本地
:param filename:
:param proxy_list:
:return:
'''
with open(filename,'w') as f:
for item in proxy_list:
f.write(item.ip + '\t')
f.write(item.port + '\t')
f.write(item.anonymous + '\t')
f.write(item.local + '\t')
f.write(item.speed + '\n\n') if __name__ == '__main__':
Get = GetProxy()
下面我们展示一下爬取的结果

如果用到代理的话,还需要对这些IP进行测试一下。
使用Selenium&PhantomJS的方式爬取代理的更多相关文章
- 使用selenium+phantomJS实现网页爬取
有些网站反爬虫技术设计的非常好,很难采用WebClient等技术进行网页信息爬取,这时可以考虑采用selenium+phantomJS模拟浏览器(其实是真实的浏览器)的方式进行信息爬取.之前一直使用的 ...
- selenium&phantomjs实战--漫话爬取
为什么直接保存当前网页,而不是找到所有漫话链接,再有针对性的保存图片? 因为防盗链的原因,当直接保存漫话链接图片时,只能保存到防盗链的图片. #!/usr/bin/env python # _*_ c ...
- 针对源代码和检查元素不一致的网页爬虫——利用Selenium、PhantomJS、bs4爬取12306的列车途径站信息
整个程序的核心难点在于上次豆瓣爬虫针对的是静态网页,源代码和检查元素内容相同:而在12306的查找搜索过程中,其网页发生变化(出现了查找到的数据),这个过程是动态的,使得我们在审查元素中能一一对应看到 ...
- Selenium+Chrome/phantomJS模拟浏览器爬取淘宝商品信息
#使用selenium+Carome/phantomJS模拟浏览器爬取淘宝商品信息 # 思路: # 第一步:利用selenium驱动浏览器,搜索商品信息,得到商品列表 # 第二步:分析商品页数,驱动浏 ...
- Scrapy 通过登录的方式爬取豆瓣影评数据
Scrapy 通过登录的方式爬取豆瓣影评数据 爬虫 Scrapy 豆瓣 Fly 由于需要爬取影评数据在来做分析,就选择了豆瓣影评来抓取数据,工具使用的是Scrapy工具来实现.scrapy工具使用起来 ...
- python爬虫爬取代理IP
# #author:wuhao # #--*------------*-- #-****#爬取代理IP并保存到Excel----#爬取当日的代理IP并保存到Excel,目标网站xicidaili.co ...
- Python爬虫-代理池-爬取代理入库并测试代理可用性
目的:建立自己的代理池.可以添加新的代理网站爬虫,可以测试代理对某一网址的适用性,可以提供获取代理的 API. 整个流程:爬取代理 ----> 将代理存入数据库并设置分数 ----> 从数 ...
- Python实训day07pm【Selenium操作网页、爬取数据-下载歌曲】
练习1-爬取歌曲列表 任务:通过两个案例,练习使用Selenium操作网页.爬取数据.使用无头模式,爬取网易云的内容. ''' 任务:通过两个案例,练习使用Selenium操作网页.爬取数据. 使用无 ...
- 爬虫实例——爬取淘女郎相册(通过selenium、PhantomJS、BeautifulSoup爬取)
环境 操作系统:CentOS 6.7 32-bit Python版本:2.6.6 第三方插件 selenium PhantomJS BeautifulSoup 代码 # -*- coding: utf ...
随机推荐
- java代码--------实现随机输出100个随机数,10行,0--到9的数字
总结:妹纸不是那么会表述,如有不妥之处,请提出来 package com.sads; //杰伦的世界 //实现在0-100个数中,随机输出数每行10个数,也就是10行10列,这些数在0---到9之间 ...
- linux文件权限,用户和组
文件权限 默认权限分配 umask umask是通过八进制的数值来定义用户创建文件或目录的默认权限的 安全权限的临界点是,文件默认权限是644,目录默认权限是755 [root@Poppy joker ...
- lamp与lnmp的选择
lnmp和lamp业务上的不同 由于二者仅仅是区别在于web的选择,nginx更高效,占用资源更少,详情区别查看LNMP环境应用实践 lnmp和lamp安装上的不同 生产环境中,可能会遇到lamp架构 ...
- node中的socket.io制作命名空间
如果开发者想在一个特定的应用程序中完全控制消息与事件的发送,只需要使用一个默认的"/"命名空间就足够了.但是如果开发者需要将应用程序作为第三方服务提供给其他应用程序,则需要为一个用 ...
- 转:系统吞吐量(TPS)、用户并发量、性能测试概念和公式
PS:下面是性能测试的主要概念和计算公式,记录下: 一.系统吞度量要素: 一个系统的吞度量(承压能力)与request对CPU的消耗.外部接口.IO等等紧密关联. 单个reqeust 对CPU消耗越高 ...
- react组件生命
组件的生命周期主要由三个部分组成: Mounting:组件正在被插入DOM中 Updating:如果DOM需要更新,组件正在被重新渲染 Unmounting:组件从DOM中移除 React提供了方法, ...
- Linux - samba 服务
暂时关闭 iptables 防火墙 [root@sch01ar ~]# systemctl stop iptables.service 暂时关闭 firewall 防火墙 [root@sch01ar ...
- 解决 service iptables start 无法启动的问题
解决方式: iptables -F // 初始化iptables. service iptables save // 保存 service iptables restart // 重启
- 22_java之File对象
01IO技术概述 * A:IO技术概述 * a: Output * 把内存中的数据存储到持久化设备上这个动作称为输出(写)Output操作 * b: Input * 把持久设备上的数据读取到内存中的这 ...
- Flask之模板之特殊变量和方法
3.6 Flask中的特殊变量和方法: 在Flask中,有一些特殊的变量和方法是可以在模板文件中直接访问的. config 对象: config 对象就是Flask的config对象,也就是 app. ...