kube-batch 解析
kube-batch
https://github.com/kubernetes-sigs/kube-batch
一. 做什么的?
官方介绍:
A batch scheduler of kubernetes for high performance workload, e.g. AI/ML, BigData, HPC
二. 使用方式
apiVersion: batch/v1
kind: Job
metadata:
name: qj-1
spec:
backoffLimit: 6 #最大失败重试次数
completions: 6 #需要成功运行pod的次数
parallelism: 6 #并行运行pod的个数
template:
metadata:
annotations:
scheduling.k8s.io/group-name: qj-1
spec:
containers:
- image: busybox
imagePullPolicy: IfNotPresent
name: busybox
resources:
requests:
cpu: "1"
restartPolicy: Never
schedulerName: kube-batch # 指定调度器是 kube-batch
---
apiVersion: scheduling.incubator.k8s.io/v1alpha1
kind: PodGroup
metadata:
name: qj-1
spec:
minMember: 6 # 最小可用数量,达到这个数量才将任务调度到节点上去
三. 调度的单位
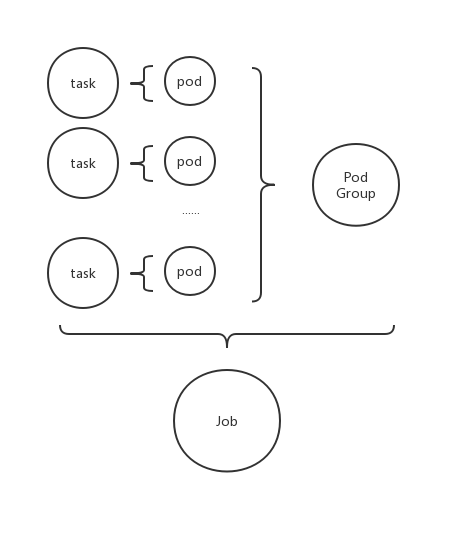
- 一个task对应一个pod
- 一个job对应一个或多个task
- Pod Group 记录该job内的pod的状态
- 一个job对应一个pod group
如果Job未声明一个对应的pod group ,
kube-batch将会给一个默认的
Pod Group 定义:
{
"metav1.TypeMeta":{},
"metav1.ObjectMeta":{},
"Spec":{
//用来做gang schedule
"MinMember":1,//default 1
"Queue":"",
"PriorityClassName":""
},
"Status":{
"Phase":"",//Pending, Running,Unknown
"Conditions":[],//optional
"Running":0,//正在运行的pod的数量
"Succeeded":0,//已经成功结束的pod的数量
"Failed":0,//失败的pod的数量
}
}
四. 整体结构
从数据流的角度给出项目框架结构:
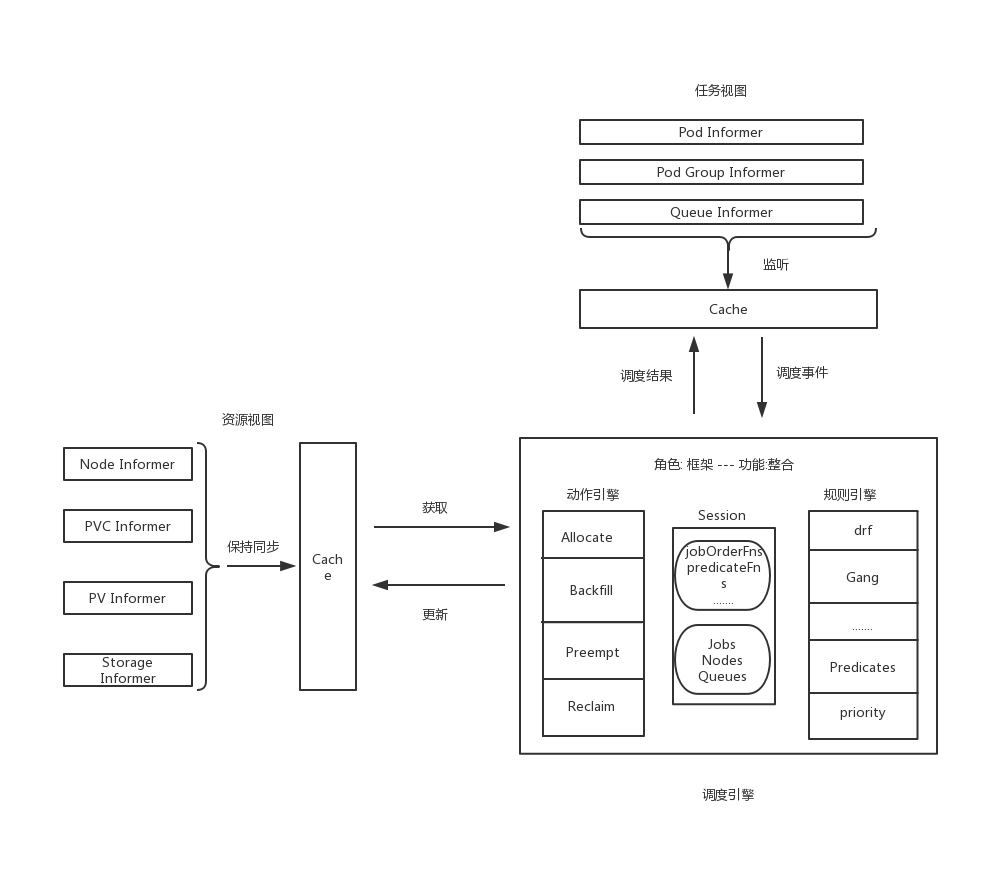
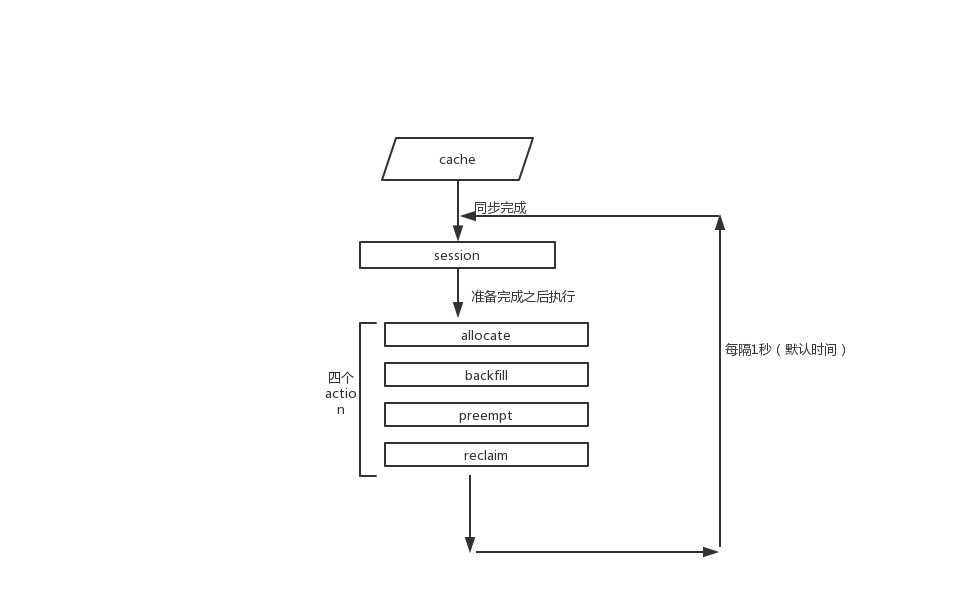
主调度流程:
五. 几个plugin
5.1 DRF (Dominant Resource Fairness)
主要资源(cpu,memory,gpu)的均衡使用算法。
目的: 尽量避免集群内某一类资源 使用比例偏高,而其他类型资源使用比例却很低的不良状态
方式: 在调度时,让具有最低资源占用比例的任务具有高优先级
细节:
DRF计算了每个job的一个share值,share值的计算公式为:
share = Max(someKindOfResource.allocated / totalResourceInTheCluster)
share = 最大的某类资源申请比例
func (drf *drfPlugin) calculateShare(allocated, totalResource *api.Resource) float64 {
res := float64(0)
for _, rn := range totalResource.ResourceNames() {
share := helpers.Share(allocated.Get(rn), totalResource.Get(rn))
if share > res {
res = share
}
}
return res
}
DRF 定义两个Function ,分别是preemptableFn 和 jobOrderFn:
jobOrderFn 是job的排序函数,会让share值越小的job排在最前面,即拥有最高的优先级,这个是实现DRF算法的关键。
preemptableFn 返回可抢占的job列表,job的筛选规则是 :如果待选job的share值大于将被调度的job的share值,则选中该待选job。
5.2 Gang
Gang策略要实现的功能: 只有当指定的某几个pod都分配到资源后,才正在地将pod调度到节点上.
定义的几个plugin function
preemptableFn为避免Gang的策略被preempt和reclaim干扰,定义了preemptableFn,排除那些还未准备就绪的job,避免被抢占。
虽然实际上这些job未真正调度到node上去,但是确实从逻辑上把资源分配给它了
jobOrderFn为让已经就绪的job尽快被调度到节点,定义了jobOrderFn,让已经就绪的job拥有更高的优先级jobReadyFn用来判断一个job是否已经就绪。
解析Kube-Batch 实现gang的方式:
无论是k8s默认的scheduler, 还是kube-batch ,再进行调度时都是先从逻辑上分配资源给pod,等满足某一条件之后,才真正将pod 调度到某一个节点上。
kube-batch/pkg/scheduler/framework/session.go Line 281
if ssn.JobReady(job) {
for _, task := range job.TaskStatusIndex[api.Allocated] {
if err := ssn.dispatch(task); err != nil {
glog.Errorf("Failed to dispatch task <%v/%v>: %v",task.Namespace, task.Name, err)
return err
}
}
}
dispatch内包bind job到node 等实际的调度动作.
jobReady会调用所有注册了的 plugin的 Ready 判定函数,只有都判定为 ready ,才返回true。
而gang plugin里面定义的ready判定函数实际上是调用 job 自带的ready函数,定义在
kube-batch/pkg/scheduler/api/job_info.go#L415
// ReadyTaskNum returns the number of tasks that are ready.
func (ji *JobInfo) ReadyTaskNum() int32 {
occupid := 0
for status, tasks := range ji.TaskStatusIndex {
if AllocatedStatus(status) ||
status == Succeeded {
occupid = occupid + len(tasks)
}
}
return int32(occupid)
}
// Ready returns whether job is ready for run
func (ji *JobInfo) Ready() bool {
occupied := ji.ReadyTaskNum()
return occupied >= ji.MinAvailable
}
5.3 Proportion
Proportion 实现了队列.
type queueAttr struct {
queueID api.QueueID // 队列的id
name string //队列的名字
weight int32 // 队列的权重,决定分配到的资源的多少
share float64 //参考 drf处的share
deserved *api.Resource //声明的资源总量
allocated *api.Resource //实际分配到的资源总量
request *api.Resource //该队列中所有job声明的要分配的资源总量
}
Proportion 根据各个队列声明的权重和全局的资源总量 初始化deserved的值,根据全局的job 初始化
allocated 和 request的值。并监听全局的资源释放 和 申请事件 更新队列的状态。
定义的几个plugin function:
- QueueOrderFn
QueueOrderFn 会决定哪一个队列里的job在调度时会被优先考虑,这里沿用了DRF处jobOrderFn的逻辑,
即share值最小的queue 会最优先被考虑.
- OverusedFn
判断queue的资源使用是否已经超出限制了,即
allocated > deserved == true
- ReclaimableFn
判断一个task是否可以被召回,如果召回之后使得已经分配到的资源小于等于deserved 就不应该被召回。
5.4 其他几个plugin
略
六. 四个Action
kube-batch 默认只开启了
Allocate和Backfill
6.1 Allocate
功能 : 将pod(task)分配到某个节点
6.2 Backfill
功能 : 调度未设置资源使用量的pod到节点(资源使用量 = 工作容器和初始化容器的各维度资源的最大值)
6.3 Reclaim
功能 : 召回满足条件的pod
6.4 Preempt
功能: 抢占已经调度了的满足条件的pod,并将目标pod调度上去
kube-batch 解析的更多相关文章
- Volcano火山:容器与批量计算的碰撞
[摘要] Volcano是基于Kubernetes构建的一个通用批量计算系统,它弥补了Kubernetes在“高性能应用”方面的不足,支持TensorFlow.Spark.MindSpore等多个领域 ...
- 博文推荐|多图详解 Apache Pulsar 消息存储模型
关于 Apache Pulsar Apache Pulsar 是 Apache 软件基金会顶级项目,是下一代云原生分布式消息流平台,集消息.存储.轻量化函数式计算为一体,采用计算与存储分离架构设计,支 ...
- 深度解析Droupout与Batch Normalization
Droupout与Batch Normalization都是深度学习常用且基础的训练技巧了.本文将从理论和实践两个角度分布其特点和细节. Droupout 2012年,Hinton在其论文中提出Dro ...
- 【网络优化】Batch Normalization(inception V2) 论文解析(转)
前言 懒癌翻了,这篇不想写overview了,公式也比较多,今天有(zhao)点(jie)累(kou),不想一点点写latex啦,读论文的时候感觉文章不错,虽然看似很多数学公式,其实都是比较基础的公式 ...
- 【转】大数据批处理框架 Spring Batch全面解析
如今微服务架构讨论的如火如荼.但在企业架构里除了大量的OLTP交易外,还存在海量的批处理交易.在诸如银行的金融机构中,每天有3-4万笔的批处理作业需要处理.针对OLTP,业界有大量的开源框架.优秀的架 ...
- 66、Spark Streaming:数据处理原理剖析与源码分析(block与batch关系透彻解析)
一.数据处理原理剖析 每隔我们设置的batch interval 的time,就去找ReceiverTracker,将其中的,从上次划分batch的时间,到目前为止的这个batch interval ...
- [k8s]Docker 用户使用 kubectl 命令指南-unkown排错(kubelet端口解析)
参考:https://kubernetes.io/docs/user-guide/kubectl-cheatsheet/ https://k8smeetup.github.io/docs/user-g ...
- 【Kubernetes】深入解析声明式API
在Kubernetes中,一个API对象在Etcd里的完整资源路径,是由:Group(API组).Version(API版本)和Resource(API资源类型)三个部分组成的. 通过这样的结构,整个 ...
- Spring Batch在大型企业中的最佳实践
在大型企业中,由于业务复杂.数据量大.数据格式不同.数据交互格式繁杂,并非所有的操作都能通过交互界面进行处理.而有一些操作需要定期读取大批量的数据,然后进行一系列的后续处理.这样的过程就是" ...
- 解析大型.NET ERP系统 十三种界面设计模式
成熟的ERP系统的界面应该都是从模板中拷贝出来的,各类功能的界面有规律可遵循.软件界面设计模式化或是艺术性的创作,我认可前者,模式化的界面客户容易举一反三,降低学习门槛.除了一些小部分的功能界面设计特 ...
随机推荐
- time,datetime模块
time模块 时间戳 返回1970年1月1日 00:00:00开始按秒计算时间偏移量 time_stamp = time.time() print(time_stamp,type(time_stamp ...
- UVA_489:Hangman Judge
Language:C++ 4.8.2 #include<stdio.h> #include<string.h> int main(void) { ]; ]; ]; ]; // ...
- hdu 1503 LCS输出路径【dp】
hdu 1503 不知道最后怎么输出,因为公共部分只输出一次.有人说回溯输出,感觉好巧妙!其实就是下图,输出的就是那条灰色的路径,但是初始时边界一定要初始化一下,因为最第一列只能向上走,第一行只能向左 ...
- HDU 5572 An Easy Physics Problem【计算几何】
计算几何的题做的真是少之又少. 之前wa以为是精度问题,后来发现是情况没有考虑全... 题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=5572 题意: ...
- Java练习 SDUT-1140_面向对象程序设计上机练习一(函数重载)
面向对象程序设计上机练习一(函数重载) Time Limit: 1000 ms Memory Limit: 65536 KiB Problem Description 利用数组和函数重载求5个数最大值 ...
- 转载:ubuntu 下的dpkg 的用法
dpkg是一个Debian的一个命令行工具,它可以用来安装.删除.构建和管理Debian的软件包. 下面是它的一些命令解释: 1)安装软件 命令行:dpkg -i <.deb file name ...
- 6、mysql的安装
1.安装mysql-Server,并输入root密码 sudo apt-get install mysql-server 2.安装mysql客户端 sudo apt-get install mysql ...
- behavior planning——10 behaior planning pseudocode
One way to implement a transition function is by generating rough trajectories for each accessible & ...
- php函数nl2br的反函数br2nl
真是搞不明白,php里有nl2br这样的好函数,但是为什么就没有它的反函数呢?只好自己在网站找了一个br2nl.分两个版本:php和javascript的. php版的代码如下: function b ...
- 洛谷P5664 Emiya 家今天的饭 问题分析
首先来看一道我编的题: 安娜写宋词 题目背景 洛谷P5664 Emiya 家今天的饭[民间数据] 的简化版本. 题目描述 安娜准备去参加宋词大赛,她一共掌握 \(n\) 个 词牌名 ,并且她的宋词总共 ...