Yandex Big Data Essentials Week1 Scaling Distributed File System
GFS Key Components
- components failures are a norm
- even space utilisation
- write-once-read-many
GFS and Hadoop Distributed File System
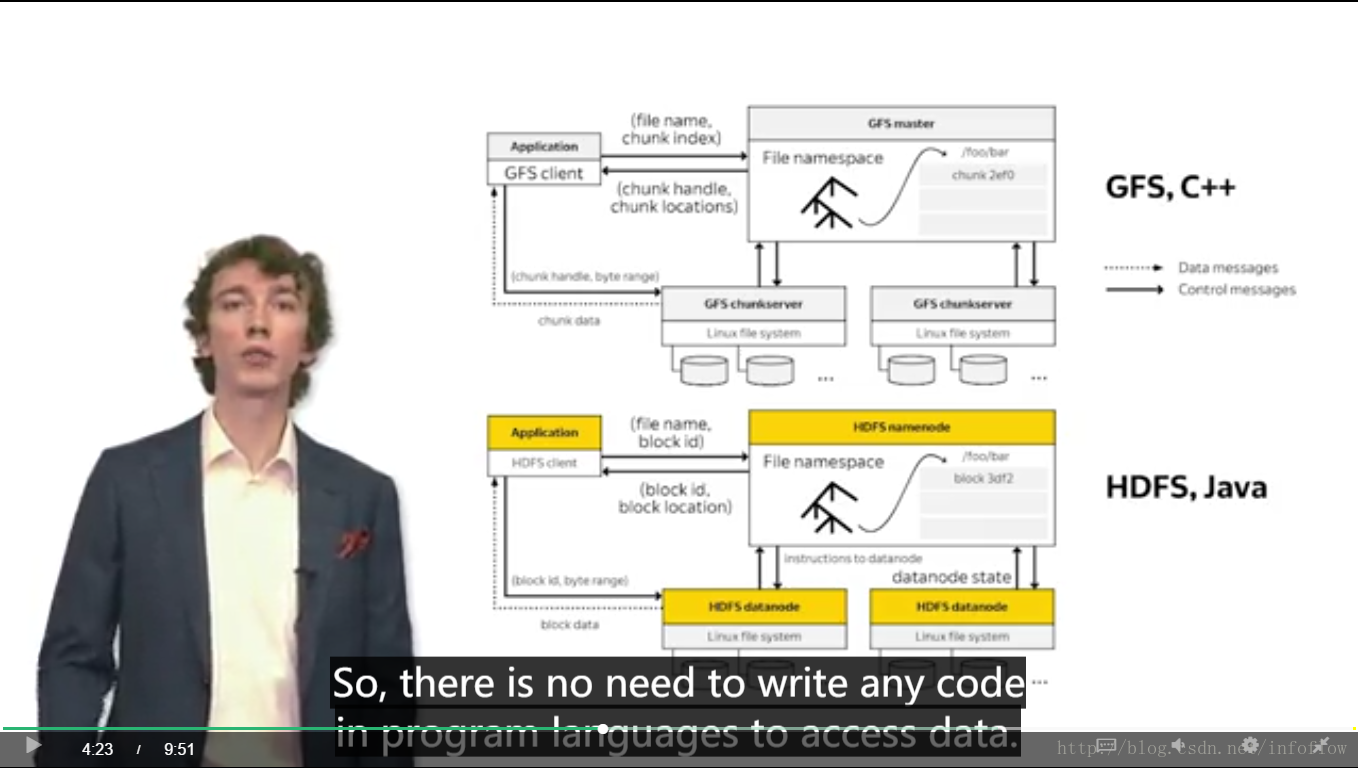
GFS主要分为:Application 、Master、ChannelServer
hdfs主要分为:Appllcation 、 NameNode 、DataNode三部分
how to read file from hdfs
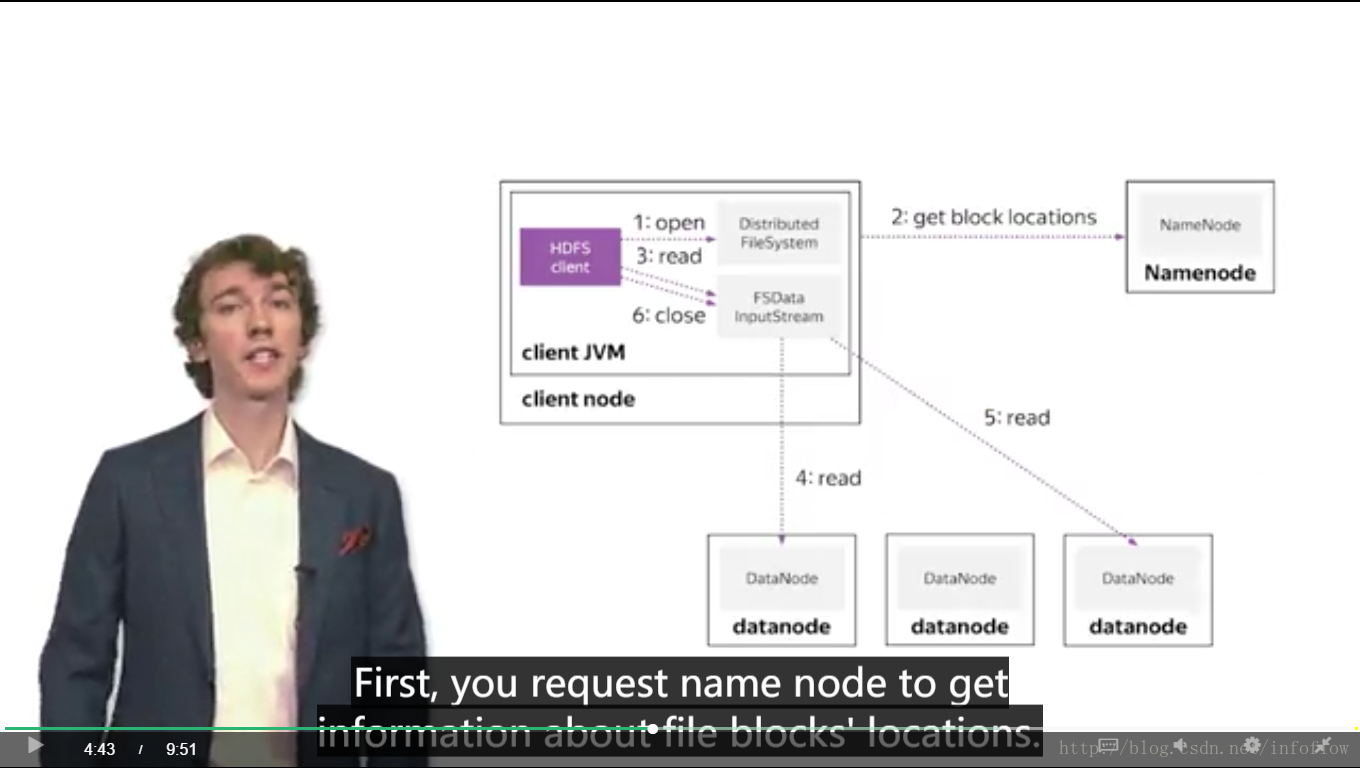
HDFS client 运行在client node 上的client jvm上。
读取文件的流程
- 打开分布式文件系统上的文件
- 从NameNode处取的文件块的位置
- HDFS client将块位置信息传给FSDataInputStream
- FSDataInputStream再从相应的DataNode里面读取其中一个块数据
- FSDataInputStream再从相应的DataNode里面读取另一个块数据
- 关闭FSDataInputStream
写入文件的流程

hdfs client 运行在client jvm上,client jvm运行在client jvm上。
写入文件的流程:
1. HDFS client 在Distributed FileSystem上创建文件
2. DistributedFileSystem 在NameNode上create一个文件
3. HDFS client 通过FSDataInputStream向datanode发送write packet
4. 至少三个datanode组成Pipeline of datanodes写入多个副本
5. datanode向FSDataInpuStream发送ack packet
6. 关闭
In DFS,you can “append” into file,but cannot “modify” a file in the middle. Why?
DFS的核心特性write once read many time 描述了一种数据存储策略。信息一旦写入就不能修改,因为修改操作需要对对底层的存储结构进行修改。如果需要修改分布式文件系统(例如hdfs)中的文件,可以写一份新的同样文件名的数据。旧的文件在hdfs在整理数据的时候会丢弃。
HDFS应用需要一个“一次写入多次读取”的文件访问模型。一个文件经过创建、写入和关闭之后就不需要改变。这一假设简化了数据一致性问题,并且使高吞吐量的数据访问成为可能。Map/Reduce应用或者网络爬虫应用都非常适合这个模型。目前还有计划在将来扩充这个模型,使之支持文件的附加写操作。
Yandex Big Data Essentials Week1 Scaling Distributed File System的更多相关文章
- Yandex Big Data Essentials Week1 Unix Command Line Interface File System exploration
File System Function In computing, a file system or filesystem is used to control how data is stored ...
- Yandex Big Data Essentials Week1 Unix Command Line Interface Processes managing
free displays the total amount of free and used memory free [options] top provides a dynamic real-ti ...
- Yandex Big Data Essentials Week1 Unix Command Line Interface File Content exploration
cat displays the contents of a file at the command line copies or apppend text file into a document ...
- HDFS分布式文件系统(The Hadoop Distributed File System)
The Hadoop Distributed File System (HDFS) is designed to store very large data sets reliably, and to ...
- HDFS(Hadoop Distributed File System )
HDFS(Hadoop Distributed File System ) HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表 ...
- 5105 pa3 Distributed File System based on Quorum Protocol
1 Design document 1.1 System overview We implemented a distributed file system using a quorum based ...
- Ceph: A Scalable, High-Performance Distributed File System译文
原文地址:陈晓csdn博客 http://blog.csdn.net/juvxiao/article/details/39495037 论文概况 论文名称:Ceph: A Scalable, High ...
- Hadoop ->> HDFS(Hadoop Distributed File System)
HDFS全称是Hadoop Distributed File System.作为分布式文件系统,具有高容错性的特点.它放宽了POSIX对于操作系统接口的要求,可以直接以流(Stream)的形式访问文件 ...
- HDFS(Hadoop Distributed File System )hadoop分布式文件系统。
HDFS(Hadoop Distributed File System )hadoop分布式文件系统.HDFS有如下特点:保存多个副本,且提供容错机制,副本丢失或宕机自动恢复.默认存3份.运行在廉价的 ...
随机推荐
- 阿里CTR预估:用户行为长序列建模
本文将介绍Alibaba发表在KDD'19 的论文<Practice on Long Sequential User Behavior Modeling for Click-Through Ra ...
- ArcEngine语法笔记(VB)
1.获取图层字段 Dim pTable As ITable = pLayer Dim pField As IField pField = pTable.Fields.Field(i) Next 2. ...
- Activiti 手工任务(manualTask)
Activiti 手工任务(manualTask) 作者:Jesai 前言: 手工任务就是一个自动执行的过程.手动任务几乎不在程序中做什么事情,只是在流程的历史中留下一点痕迹,表明流程是走过某些节点的 ...
- Jenkins自动执行python脚本输出测试报告
前言 在用python做自动化测试时,我们写好代码,然后需要执行才能得到测试报告,这时我们可以通过 Jenkins 来进一步完成自动化工作. 借助Jenkins,我们可以结合 Git/SVN 自动拉取 ...
- 【javaScript】js出现allocation size overflow以及字符串拼接优化
字符串拼接长一点了,就出现了allocation size overflow异常! 先创建缓冲字符串数组,最后将数组转化为字符串 <script type="text/javascri ...
- 【java面试】算法篇
1.冒泡排序 /** * 冒泡排序 * 比较相邻的元素.如果第一个比第二个大,就交换他们两个. * 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对.在这一点,最后的元素应该会是最大的数. ...
- python+win32--com实现excel自动化
import win32com APP_TYPE = 'Excel.Application' xlBlack,xlRed,xlGray,xlBlue = 1,3,15,41 xlBreakFull ...
- AI初探1
一个典型的机器学习的过程,首先给出一个输入数据,我们的算法会通过一系列的过程得到一个估计的函数,这个函数有能力对没有见过的新数据给出一个新的估计,也被称为构建一个模型.就如同上面的线性回归函数. 在机 ...
- tarjan缩点练习 洛谷P3387 【模板】缩点+poj 2186 Popular Cows
缩点练习 洛谷 P3387 [模板]缩点 缩点 解题思路: 都说是模板了...先缩点把有环图转换成DAG 然后拓扑排序即可 #include <bits/stdc++.h> using n ...
- 高阶函数及 map、reduce、filter 的实现
博客地址:https://ainyi.com/85 2020 开年国家经历了不少困难,最为凶猛的局势就是新型冠状病毒的蔓延,国务院最终决定春节假期延长至==2 月 2 号==:公司决定 3 - 7 号 ...