Trie(字典树)的侃侃
Trie是什么 ?
字典树 : 见名知意(在树上进行查询)。
跟字典相关的必定与查询有密切的关系,
查询就需要一定的媒介作为支撑,树就为这种查询提供支撑。
Trie做什么 ?
实现字符串快速检索的多叉树结构。
常见的字符串转化:小写字母或者大写字母组成的字符串,数字组成的字符串,01编码组成的字符串。
Trie有什么 ?
Trie 的每个节点都拥有若干个字符指针,就是说每个节点有多个子节点,通俗一点就是相当于古代
的大少爷可以有多个妻子。
Trie干什么 ?
1、插入(将一个字符串插入到字典树上)
2、检索(检索一个字符串 S 在Trie 上是否存在)
侃了这么多,看看这货到底是个啥 ?
假设有单词 : cab , cef , da 这样三个单词,那么这样三个单词组成的图是什么样的呢 ?
看下图 : (通常还要在末尾进行标记一下,表示到字符串的末尾)
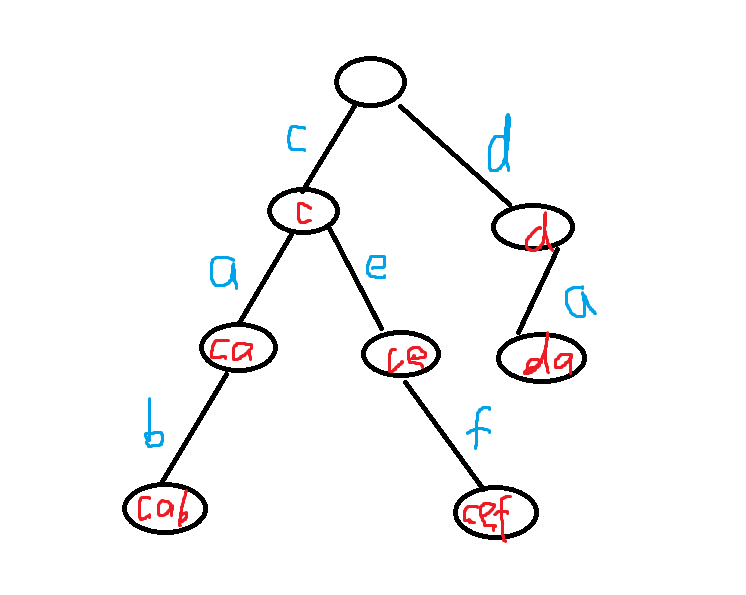
怎么实现这个玩意呢 ?
插入 :
像每个单词拼写一样,单词的开头就相当于是我们的根,从根节点出发,向儿子节点前进。
在向下走的过程中,看有没有当前这个字符的节点,如果有这个节点,就顺着这个节点继续
往下走,如果没有这个节点,就在这个节点之下再创建一个节点。
拿一个例子来说:
比如上图的 cab 和 cef, 先插入第一个字符串,从根节点出发,第一个字符是 c,我们发
现没有这个字符的节点,所以创建一个节点,将指针节点进行指向,然后一直向下移动,知道
字符串结尾。再插入第二个字符串,先检测第一个字符是否存在,我们发现存在,所以不用
创建,直接向下移动指针节点即可。
可以发现:
一个节点最多可以有26个孩子。
检索:
只需要将字符串遍历一遍,顺着根节点下来看这条路径上是否有不存在的值,即 0,如果
没有到末尾就发现有 0 ,说明这个字符串不存在,反之即存在。
Code :
插入:
void insert(char str[]) {
int len = strlen(str),p = 0; // p 作为根节点从 0 开始
for(int i = 0; i < len; i ++) {
int ch = str[i] - 'a';
if(trie[p][ch] == 0) trie[p][ch] = ++ idx; // 创建新的节点
p = trie[p][ch]; // 指针移动
}
End[p] = true; // 在末尾进行标记
return ;
}
检索:
bool query(char str[]) {
int len = strlen(str),p = 0;
for(int i = 0; i < len; i ++ ){
int ch = str[i] - '0';
if(trie[p][ch] != 0) {
p = trie[p][ch];
} else {
break; // 及时跳出
}
}
return true;
}
Example: 前缀统计
题目链接: https://www.acwing.com/problem/content/144/
题目描述:给定N个字符串S1,S2…SN,接下来进行M次询问,每次询问给定一个字符串T,求S1~SN中有多少个字符串是T的前缀。
输入字符串的总长度不超过106,仅包含小写字母。
输入格式
第一行输入两个整数N,M。
接下来N行每行输入一个字符串Si。
接下来M行每行一个字符串T用以询问。
输出格式
对于每个询问,输出一个整数表示答案。
每个答案占一行。
输入样例:
3 2
ab
bc
abc
abc
efg
输出样例:
2
0
析题得说: 统计每个字符串出现的个数即可,用一个cnt[]数组记录每个字符串出现的个数,然后进行检索要处理的字符串,累加结果(模板题)
AC代码:
#include <cstdio>
#include <string>
#include <cstring>
#include <iostream>
#include <algorithm>
using namespace std;
const int SIZE = 1e6 + 10;
int trie[SIZE][26],cnt[SIZE];
char str[SIZE];
int n,m,idx = 0;
int main(void) {
void insert();
int query();
scanf("%d%d",&n,&m);
for(int i = 1; i <= n; i ++) {
scanf("%s",str);
insert();
}
while(m --) {
scanf("%s",str);
printf("%d\n",query());
}
return 0;
}
void insert() {
int p = 0;
for(int i = 0; i < strlen(str); i ++) {
int ch = str[i] - 'a';
if(trie[p][ch] == 0) trie[p][ch] = ++ idx;
p = trie[p][ch];
}
cnt[p] ++; // 统计该字符串的个数
return ;
}
int query() {
int p = 0,res = 0;
for(int i = 0 ; i < strlen(str); i ++) {
int ch = str[i] - 'a';
if(trie[p][ch] != 0) {
p = trie[p][ch];
res += cnt[p]; // 将以该字符结尾的数量累加,最后结果就是前缀字符串的数量
} else {
break;
}
}
return res;
}
Trie(字典树)的侃侃的更多相关文章
- 萌新笔记——C++里创建 Trie字典树(中文词典)(一)(插入、遍历)
萌新做词典第一篇,做得不好,还请指正,谢谢大佬! 写了一个词典,用到了Trie字典树. 写这个词典的目的,一个是为了压缩一些数据,另一个是为了尝试搜索提示,就像在谷歌搜索的时候,打出某个关键字,会提示 ...
- Trie字典树 动态内存
Trie字典树 #include "stdio.h" #include "iostream" #include "malloc.h" #in ...
- 算法导论:Trie字典树
1. 概述 Trie树,又称字典树,单词查找树或者前缀树,是一种用于快速检索的多叉树结构,如英文字母的字典树是一个26叉树,数字的字典树是一个10叉树. Trie一词来自retrieve,发音为/tr ...
- 标准Trie字典树学习二:Java实现方式之一
特别声明: 博文主要是学习过程中的知识整理,以便之后的查阅回顾.部分内容来源于网络(如有摘录未标注请指出).内容如有差错,也欢迎指正! 系列文章: 1. 标准Trie字典树学习一:原理解析 2.标准T ...
- 817E. Choosing The Commander trie字典树
LINK 题意:现有3种操作 加入一个值,删除一个值,询问pi^x<k的个数 思路:很像以前lightoj上写过的01异或的字典树,用字典树维护数求异或值即可 /** @Date : 2017- ...
- C++里创建 Trie字典树(中文词典)(一)(插入、遍历)
萌新做词典第一篇,做得不好,还请指正,谢谢大佬! 写了一个词典,用到了Trie字典树. 写这个词典的目的,一个是为了压缩一些数据,另一个是为了尝试搜索提示,就像在谷歌搜索的时候,打出某个关键字,会提示 ...
- 数据结构 -- Trie字典树
简介 字典树:又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种. 优点:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高. 性质: 1. 根节 ...
- 踹树(Trie 字典树)
Trie 字典树 ~~ 比 KMP 简单多了,无脑子选手学不会KMP,不会结论题~~ 自己懒得造图了OI WIKI 真棒 字典树大概长这么个亚子 呕吼真棒 就是将读进去的字符串根据当前的字符是什么和所 ...
- trie字典树详解及应用
原文链接 http://www.cnblogs.com/freewater/archive/2012/09/11/2680480.html Trie树详解及其应用 一.知识简介 ...
随机推荐
- Linux 学习笔记 6 搭建nginx 实现二级域名访问
前言 在前一节的内容里面,我们学习了如何使用yum 包管理工具来安装我们需要的软件,这节内容,通过搭建Nginx 反向代理服务器,以及学习服务的配置等内容. NGINX Nginx是一款轻量级的Web ...
- express项目创建
npm install express-generator -g 全局安装express生成器 express -h 帮助中心 express 项目名 npm i 安装依赖 nod ...
- Elasticsearch系列---搜索执行过程及scroll游标查询
概要 本篇主要介绍一下分布式环境中搜索的两阶段执行过程. 两阶段搜索过程 回顾我们之前的CRUD操作,因为只对单个文档进行处理,文档的唯一性很容易确定,并且很容易知道是此文档在哪个node,哪个sha ...
- Hive 这些基础知识,你忘记了吗?
Hive 其实是一个客户端,类似于navcat.plsql 这种,不同的是Hive 是读取 HDFS 上的数据,作为离线查询使用,离线就意味着速度很慢,有可能跑一个任务需要几个小时甚至更长时间都有可能 ...
- Spring中bean的实例化过程
1.从缓存中.优先从一级缓存中拿,有则返回. 如果没有,则从二级缓存中获取,有则返回. 如果二级缓存中拿不到,则从三级缓存中拿,能拿到,则从三级缓存中删除,移到二级缓存. 如果三级缓存也没有,则返回n ...
- 史上最简单的vi教程,10分钟包教会
从第一次接触vi/vim到现在已经十几年了,在这个过程中,来来回回,反反复复,学习vi很多次了. 虽然关于vi的使用,我还远未达到"专家"的水平,但对于vi的使用,我有话说. 1. ...
- Docker + node(koa) + nginx + mysql 线上环境部署
在上一篇 Docker + node(koa) + nginx + mysql 开发环境搭建,我们进行了本地开发环境搭建 现在我们就来开始线上环境部署 如果本地环境搭建没有什么问题,那么线上部署的配置 ...
- scrapy持久化到Excel表格
前提条件: 防止乱码产生 ITEM_PIPELINES = { 'xpc.pipelines.ExcelPipeline': 300, } 方法一 1.安装openpyxl conda install ...
- Zabbix添加SNMP自定义监控项OID出现“No Such Instance currently exists at this OID”
原因:zabbix 是用snmpget来获取指定的OID数据,snmpwalk是遍历某个OID下的数据. 所以一定要用snmpget来验证某个OID是否正确. snmptranslate 获取的OID ...
- 【WPF学习】第二十六章 Application类——应用程序的生命周期
在WPF中,应用程序会经历简单的生命周期.在应用程序启动后,将立即创建应用程序对象,在应用程序运行时触发各种应用程序事件,你可以选择监视其中的某些事件.最后,当释放应用程序对象时,应用程序将结束. 一 ...