第四十七篇 入门机器学习——分类的准确性(Accuracy)
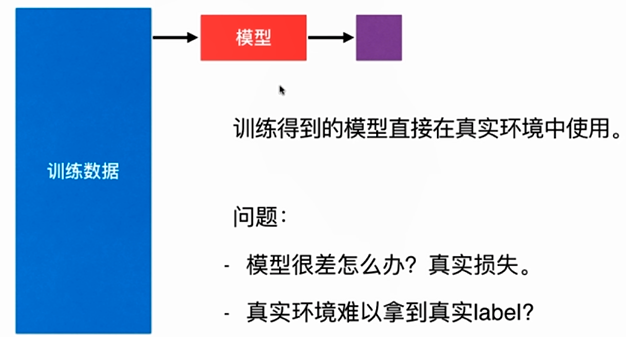
No.1. 通常情况下,直接将训练得到的模型应用于真实环境中,可能会存在很多问题
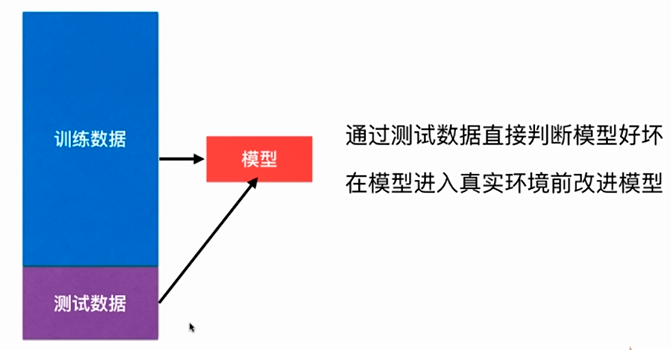
No.2. 比较好的解决方法是,将原始数据中的大部分用于训练数据,而留出少部分数据用于测试,即,将数据集切分成训练数据集和测试数据集两部分,先通过训练数据集得到一个模型,然后通过测试数据集来检验模型的性能是否满足我们的要求,根据测试结果的好坏判断模型是否需要进行改进和优化
No.3. 我们通过鸢尾花数据集来测试kNN算法的分类准确性,首先是数据准备工作
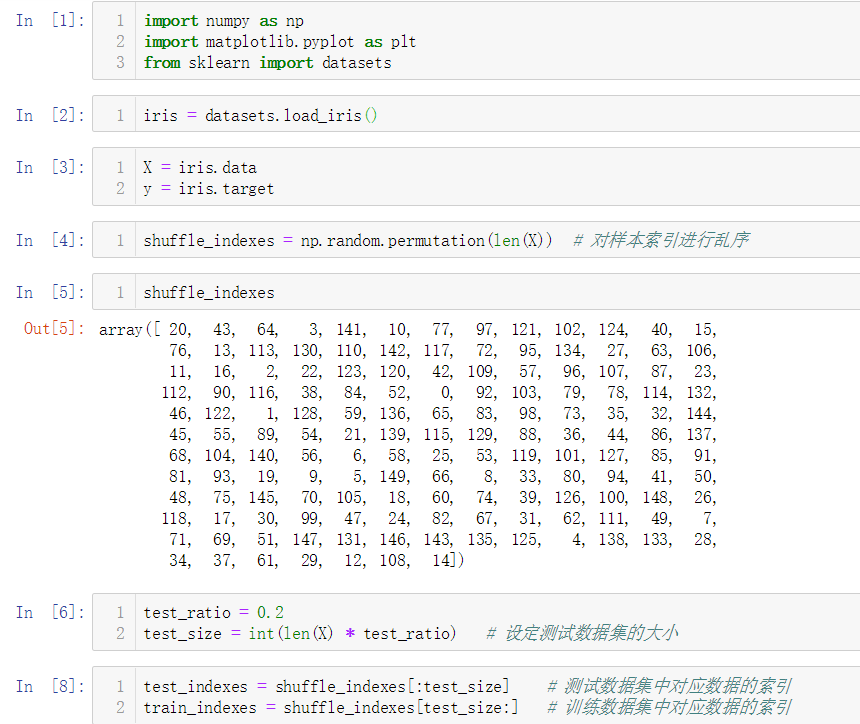
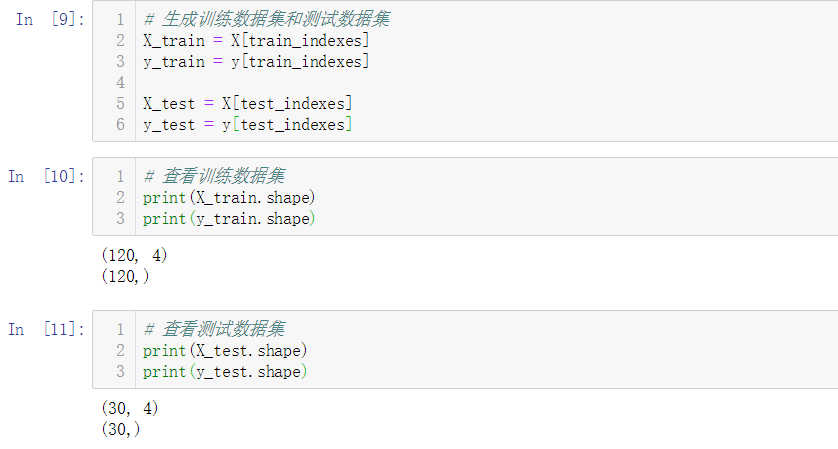
No.4. 我们可以将上述过程封装到函数中

No.5. 调用我们封装的数据集切分函数
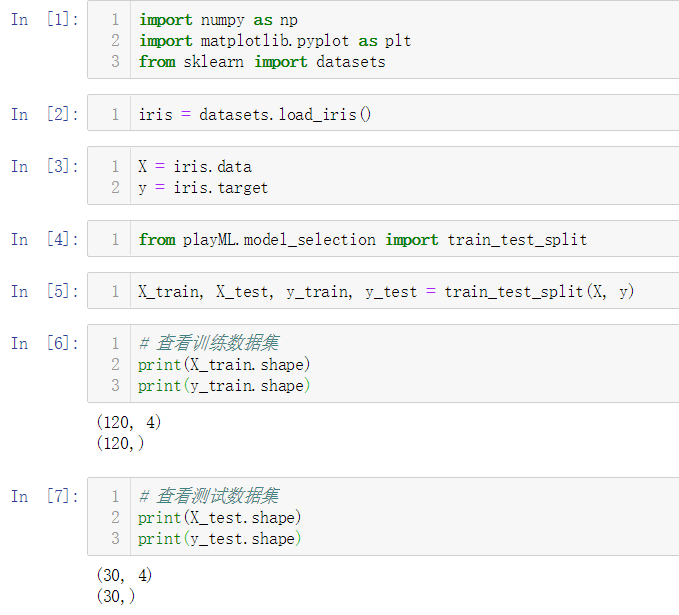
No.6. 调用自己封装的KNNClassifier类,测试其分类准确性
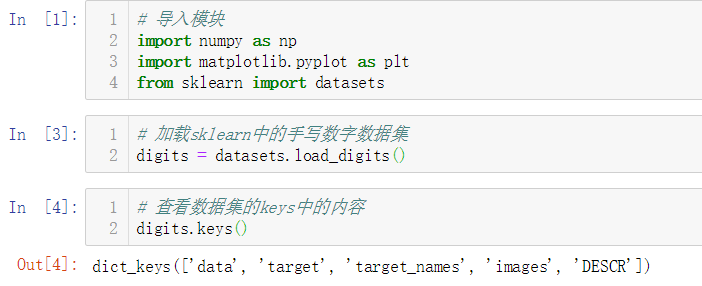
No.9. 查看一下数据集的详细描述信息
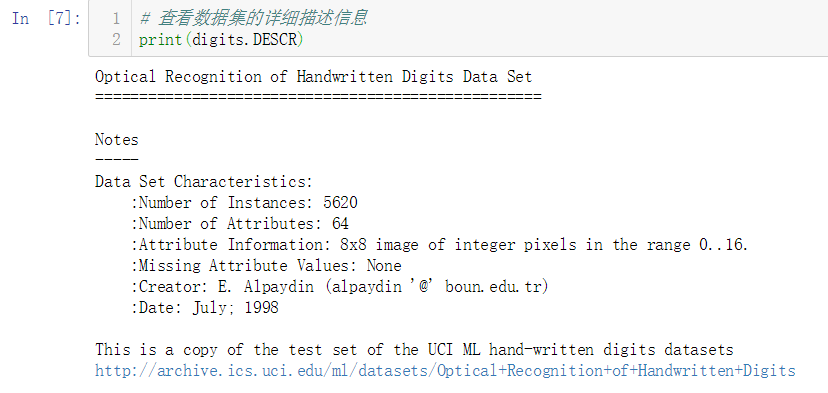
从上面的描述信息中可以了解到,这个数据集共有5620个数据实例,每个实例有64个属性(特征),这64个属性实际组成了8x8像素的图片,每个像素点的取值范围是0-16,这个数据集共分为10个类别,即0-9这10个数字。另外需要注意的一点是,这个数据集只是原数据集的一个简化副本,它实际上只存储了不到2000个数据实例。
No.10. 我们具体查看一下数据集的特征


即,这1797个数据实例都有对应的标签,标签共分为10个类别,分别为0, 1, 2, 3, 4, 5, 6, 7, 8, 9
简单查看前100个数据实例对应的标签,发现这些数据并没有按照不同类别分类存放
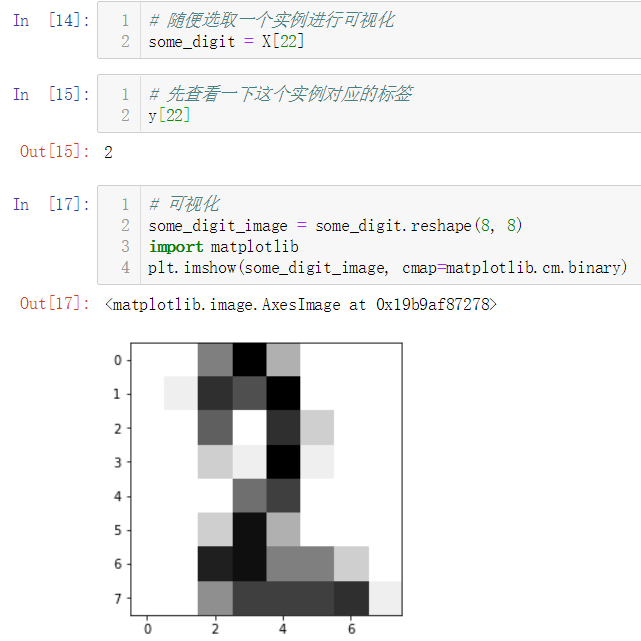
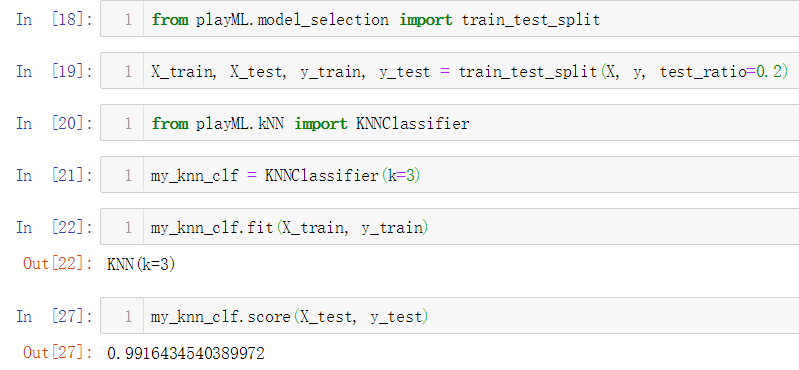
No.11. 调用我们实现的数据切分函数对数据集进行切分,再调用我们是实现的KNNClassifier类,测试其分类准确性
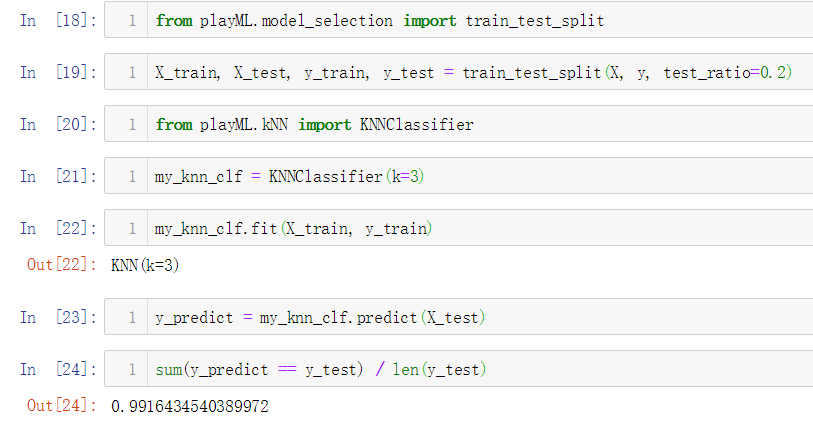
No.12. 上面在测试分类准确性的时候,计算准确性的过程还没有进行封装,我们将其封装如下:

测试一下封装好的函数:
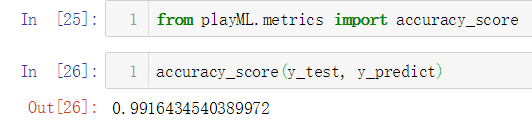
No.13. 某些情况下,我们对预测值具体是什么并不感兴趣,我们可能只想知道我们模型预测结果的准确性,这种情况下,是没有必要手动计算一遍预测值的,我们可以封装一个接口,直接获取到模型预测结果的准确性,在kNNClassifier类中添加一个方法实现这个功能:

测试一下这个接口:
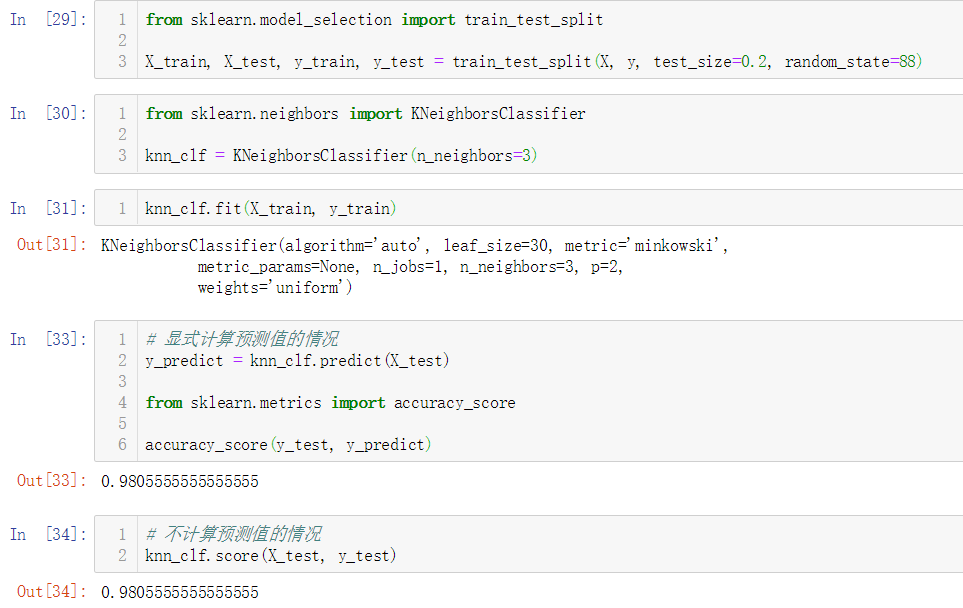
No.14. 调用sklearn提供的数据切分函数对数据集进行切分,再调用sklearn提供的KNeighborsClassifier类,测试其分类准确性
第四十七篇 入门机器学习——分类的准确性(Accuracy)的更多相关文章
- 第四十三篇 入门机器学习——Numpy的基本操作——Fancy Indexing
No.1. 通过索引快速访问向量中的多个元素 No.2. 用索引对应的元素快速生成一个矩阵 No.3. 通过索引从矩阵中快速获取多个元素 No.4. 获取矩阵中感兴趣的行或感兴趣的列,重新组成矩阵 N ...
- 第四十篇 入门机器学习——Numpy.array的基本操作——向量及矩阵的运算
No.1. Numpy.array相较于Python原生List的性能优势 No.2. 将向量或矩阵中的每个元素 + 1 No.2. 将向量或矩阵中的所有元素 - 1 No.3. 将向量或矩阵中的所有 ...
- 第三十七篇 入门机器学习——Numpy基础
No.1. 查看numpy版本 No.2. 为了方便使用numpy,在导入时顺便起个别名 No.3. numpy.array的基本操作:创建.查询.修改 No.4. 用dtype查看当前元素的数据类型 ...
- 第四十九篇 入门机器学习——数据归一化(Feature Scaling)
No.1. 数据归一化的目的 数据归一化的目的,就是将数据的所有特征都映射到同一尺度上,这样可以避免由于量纲的不同使数据的某些特征形成主导作用. No.2. 数据归一化的方法 数据归一化的方法主要 ...
- 第四十六篇 入门机器学习——kNN - k近邻算法(k-Nearest Neighbors)
No.1. k-近邻算法的特点 No.2. 准备工作,导入类库,准备测试数据 No.3. 构建训练集 No.4. 简单查看一下训练数据集大概是什么样子,借助散点图 No.5. kNN算法的目的是,假如 ...
- Jmeter(四十七) - 从入门到精通高级篇 - 分布式压测部署之负载机的设置(详解教程)
1.简介 千呼万唤始出来,这一篇感觉写了好久,总想写的清楚明白简洁,但是还是洋洋洒洒写了好多,希望大家喜欢吧!本来打算将这一篇文章是放在性能测试中讲解和分享的,但是有的童鞋或者小伙伴们私下问的太多了, ...
- 第四十四篇 入门机器学习——matplotlib基础——实现数据可视化
No.1. 绘制一条正弦曲线 No.2. 在一张图中绘制多条曲线 No.3. 可以为曲线指定颜色.线条样式 No.4. 可以指定横纵坐标轴的范围 也可以使用: No.6. 可以为每条曲线添加图示 No ...
- 第四十二篇 入门机器学习——Numpy的基本操作——索引相关
No.1. 使用np.argmin和np.argmax来获取向量元素中最小值和最大值的索引 No.2. 使用np.random.shuffle将向量中的元素顺序打乱,操作后,原向量发生改变:使用np. ...
- Python之路(第四十七篇) 协程:greenlet模块\gevent模块\asyncio模块
一.协程介绍 协程:是单线程下的并发,又称微线程,纤程.英文名Coroutine.一句话说明什么是线程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的. 协程相比于线程,最大的区别在于 ...
随机推荐
- Linux环境搭建及基础操作
一.Linux环境搭建 1.安装虚拟机软件(VMWare,Parallel) 虚拟机的作用:将本来不是适合当前操作系统的分区虚拟化成适合当前操作系统的分区格式 2.新建虚拟机: 类似买了一台新的电脑, ...
- UVA1401 (字典树加简单dp)
#pragma GCC optimize(2) #include <bits/stdc++.h> #define ll long long using namespace std; ; ; ...
- spark-sklearn TypeError: 'JavaPackage' object is not callable
from sklearn import svm, datasets from spark_sklearn import GridSearchCV from pyspark import SparkCo ...
- Canvas如何绘制精美的图?
一.Canvas的基本使用 首先在使用Canvas一般先在<body>中添加: <canvas id="></canvas> 然后使用Js进行获取canv ...
- 关于Windows系统下端口被占用的问题和task命令
一.如何解决端口被占用的问题? 此时端口4444被进程占用,只要找到端口4444的进程,并且将进程kill掉即可. 开始--运行--cmd 进入命令提示符 输入netstat -aon 即可看到所有连 ...
- Quartz.NET常用方法 02
上一篇里介绍了Job和Trigger的常用方法,这一节将介绍Calendar,它的作用是排除特定的日期时间. Calendar的常用类 DailyCalendar 排除每天某个时间段任务的执行 例 ...
- 在linux中安装nginx
linux系统安装在vmware中,首先在主机中利用shell工具与虚拟机连接 1.在linux中查看虚拟机的ip地址 在终端输入 ifconfig 红框里面就是ip地址 2.在主机中打开shell工 ...
- 为什么SSL证书要设有效期?
1.首先是为了安全考虑,CA机构不能保证一个网站永远是合法的,因此它需要定期检查网站. 2.其次,以往CA证书都非常贵,签发证书的机构通过设置期限来收费,是一种商业途径. 3.最后,还有最重要的原因就 ...
- Selenium chromeDriver启动时报错:session not created: This version of ChromeDriver only supports Chrome
解决方案: 这是因为ChromeDriver与本地chrome浏览器的版本不一致导致 ChromeDriver下载地址:http://npm.taobao.org/mirrors/chromedriv ...
- Dijkstra算法依据项目改进版,输出路径
package dijkstra; import java.util.ArrayList; public class Dijkstra { ; /*private static int[][] Gra ...