Spark学习之路 (二十三)SparkStreaming的官方文档
一、SparkCore、SparkSQL和SparkStreaming的类似之处

二、SparkStreaming的运行流程
2.1 图解说明
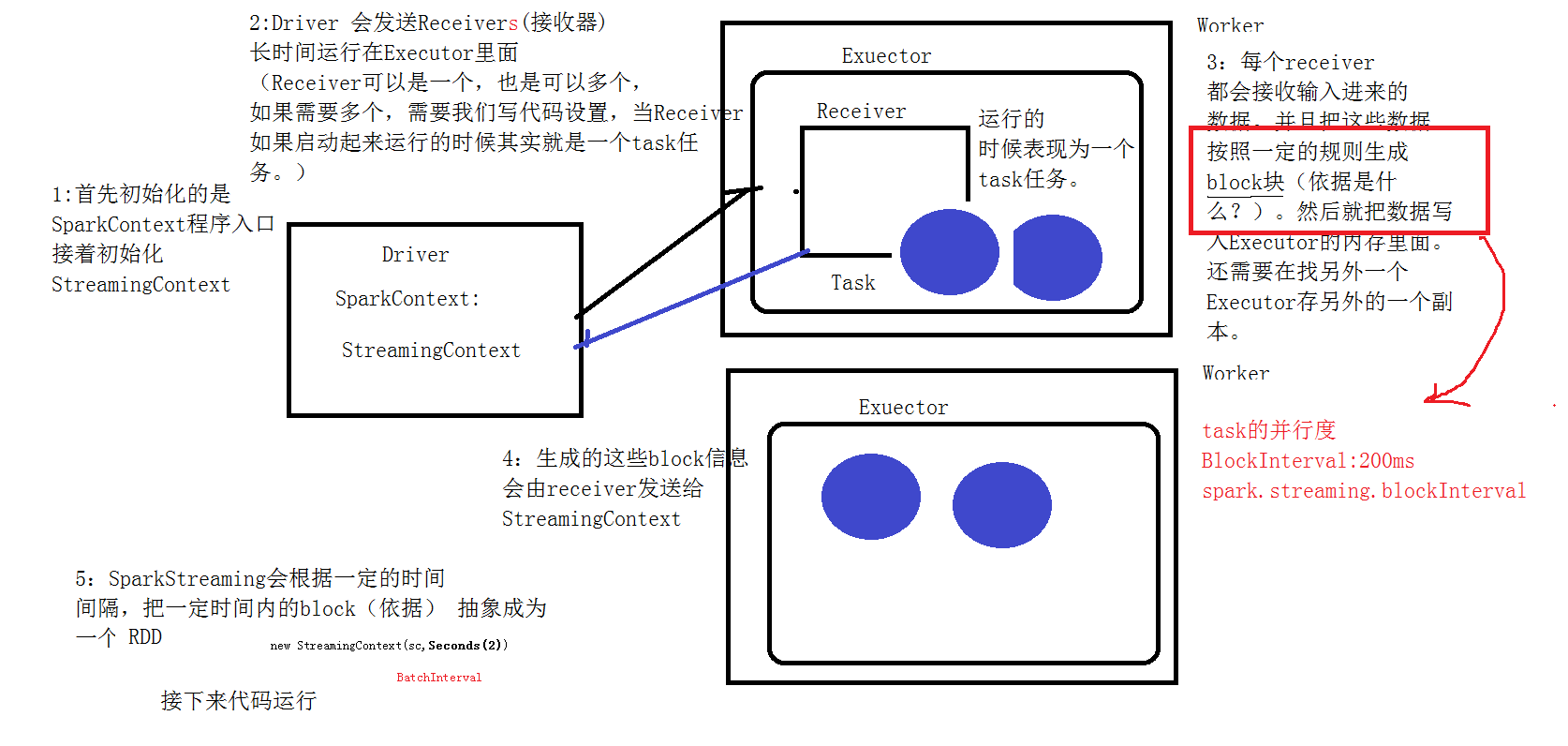
2.2 文字解说
1、我们在集群中的其中一台机器上提交我们的Application Jar,然后就会产生一个Application,开启一个Driver,然后初始化SparkStreaming的程序入口StreamingContext;
2、Master会为这个Application的运行分配资源,在集群中的一台或者多台Worker上面开启Excuter,executer会向Driver注册;
3、Driver服务器会发送多个receiver给开启的excuter,(receiver是一个接收器,是用来接收消息的,在excuter里面运行的时候,其实就相当于一个task任务)
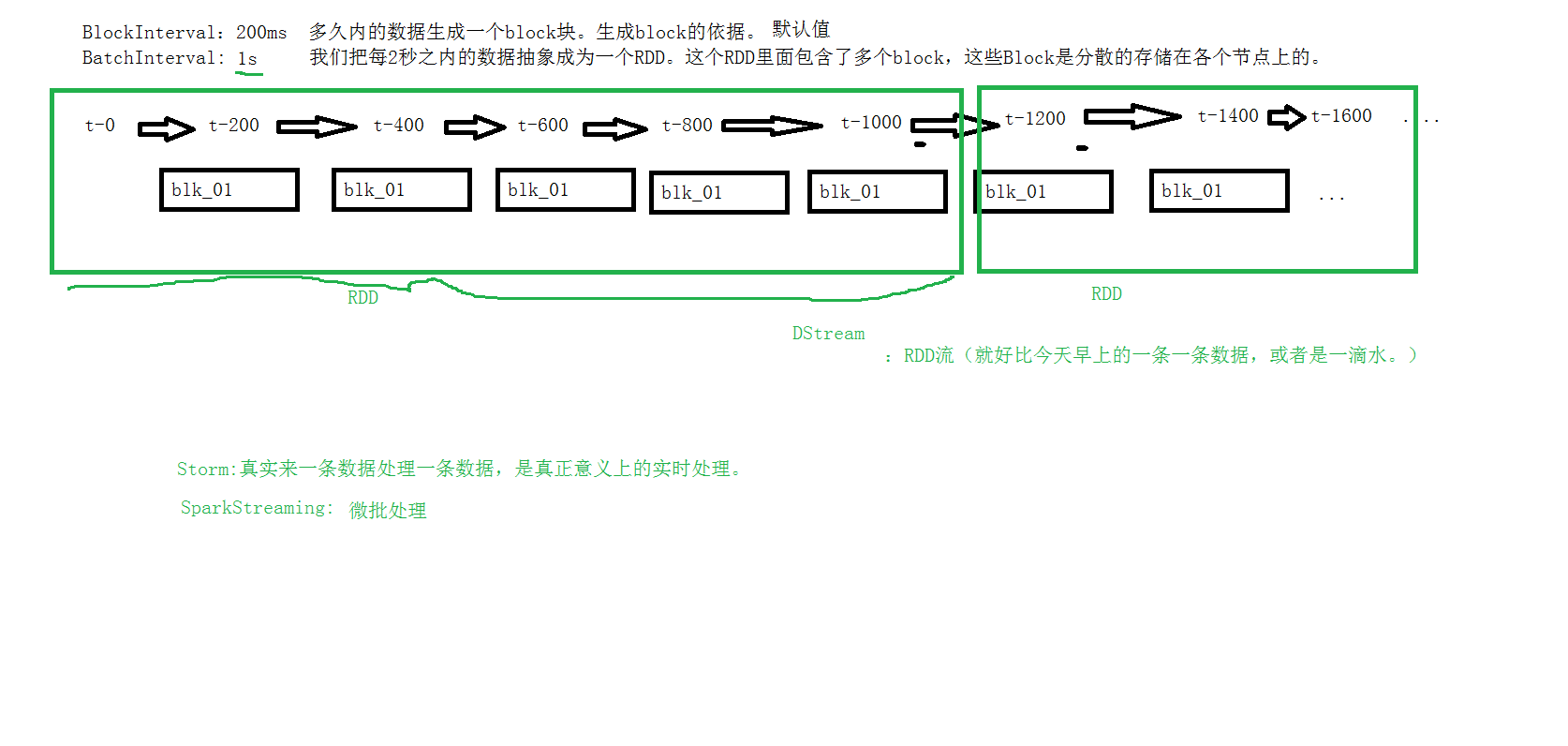
4、receiver接收到数据后,每隔200ms就生成一个block块,就是一个rdd的分区,然后这些block块就存储在executer里面,block块的存储级别是Memory_And_Disk_2;
5、receiver产生了这些block块后会把这些block块的信息发送给StreamingContext;
6、StreamingContext接收到这些数据后,会根据一定的规则将这些产生的block块定义成一个rdd;
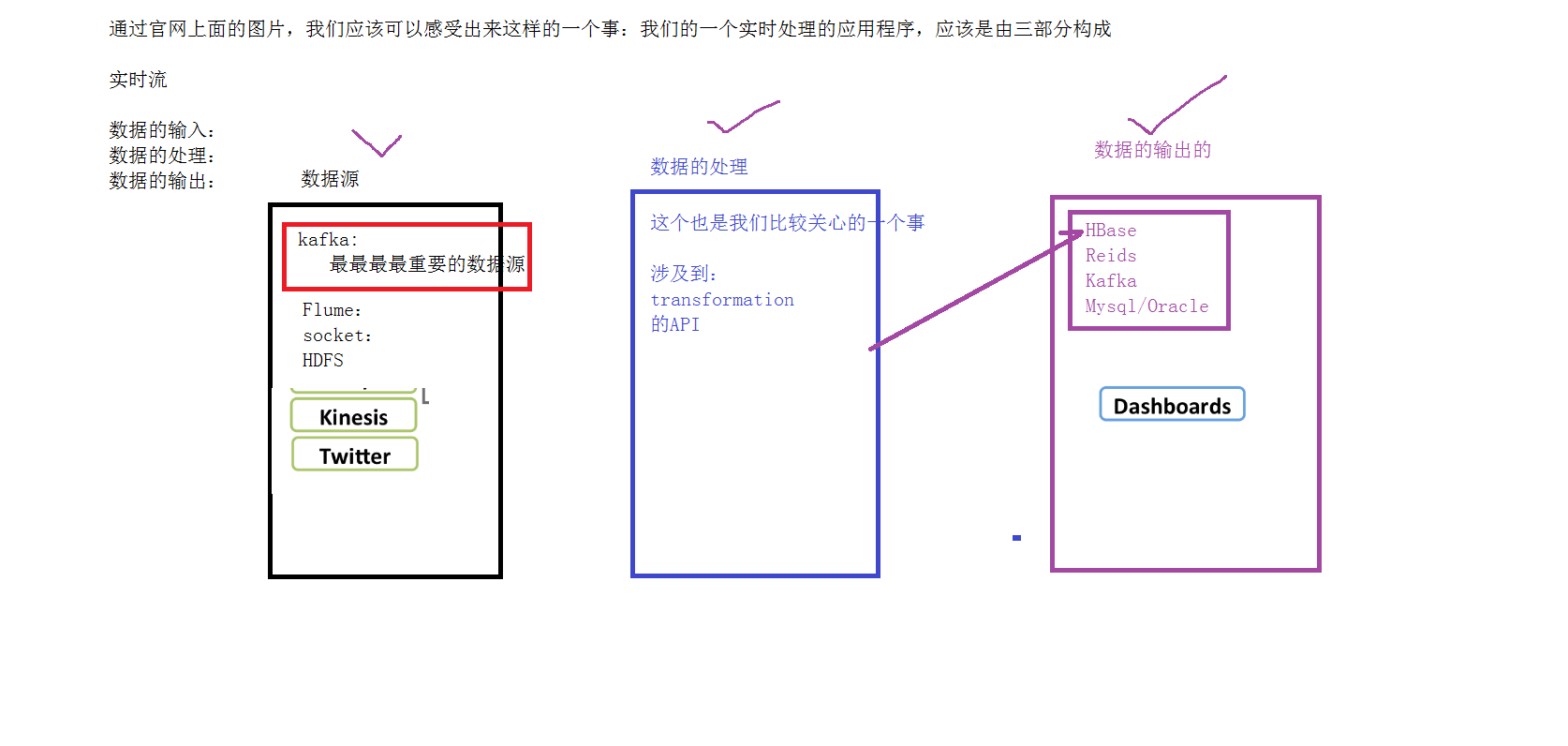
三、SparkStreaming的3个组成部分
四、 离散流(DStream)
五、小栗子
5.1 简单的单词计数
Scala代码
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object NetWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[2]")
val sparkContext = new SparkContext(conf)
val sc = new StreamingContext(sparkContext,Seconds())
/**
* 数据的输入
* */
val inDStream: ReceiverInputDStream[String] = sc.socketTextStream("bigdata",)
inDStream.print()
/**
* 数据的处理
* */
val resultDStream: DStream[(String, Int)] = inDStream.flatMap(_.split(",")).map((_,)).reduceByKey(_+_)
/**
* 数据的输出
* */
resultDStream.print()
/**
*启动应用程序
* */
sc.start()
sc.awaitTermination()
sc.stop()
}
}
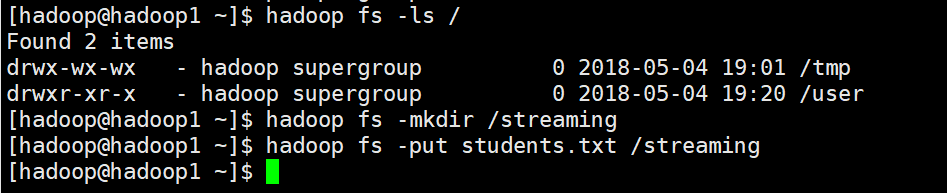
在Linux上执行以下命令

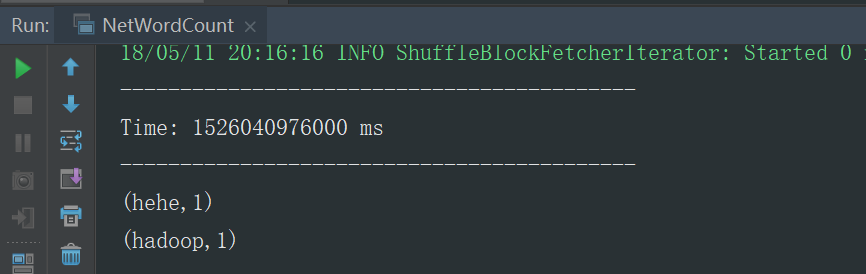
运行结果
5.2 监控HDFS上的一个目录
HDFS上的目录需要先创建
Scala代码
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext} object HDFSWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[2]").setAppName(this.getClass.getSimpleName)
val sc = new StreamingContext(conf,Seconds()) val inDStream: DStream[String] = sc.textFileStream("hdfs://hadoop1:9000/streaming")
val resultDStream: DStream[(String, Int)] = inDStream.flatMap(_.split(",")).map((_,)).reduceByKey(_+_)
resultDStream.print() sc.start()
sc.awaitTermination()
sc.stop()
}
}
Linux上的命令
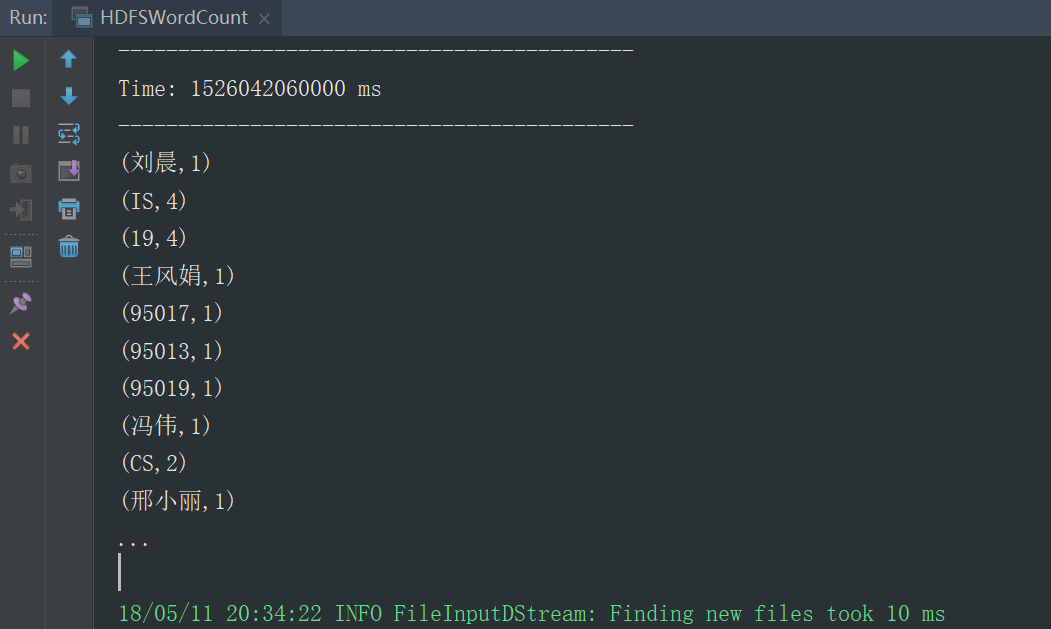
student.txt
,刘晨,女,,IS
,王风娟,女,,IS
,王一,女,,IS
,冯伟,男,,CS
,王小丽,女,,CS
,邢小丽,女,,IS
运行结果,默认展示的10条
5.3 第二次运行的时候更新原先的结果
Scala代码
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object UpdateWordCount {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[2]")
System.setProperty("HADOOP_USER_NAME","hadoop")
val sparkContext = new SparkContext(conf)
val sc = new StreamingContext(sparkContext,Seconds())
sc.checkpoint("hdfs://hadoop1:9000/streaming")
val inDStream: ReceiverInputDStream[String] = sc.socketTextStream("hadoop1",)
val resultDStream: DStream[(String, Int)] = inDStream.flatMap(_.split(","))
.map((_, ))
.updateStateByKey((values: Seq[Int], state: Option[Int]) => {
val currentCount: Int = values.sum
val lastCount: Int = state.getOrElse()
Some(currentCount + lastCount)
})
resultDStream.print()
sc.start()
sc.awaitTermination()
sc.stop()
}
}
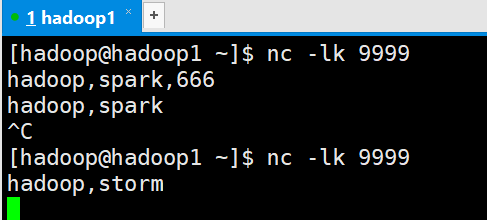
Linux运行命令
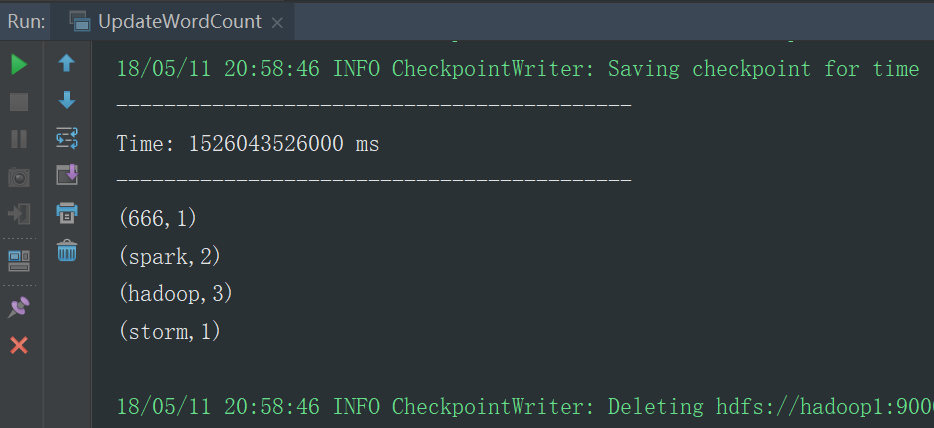
运行结果
5.4 DriverHA
5.3的代码一直运行,结果可以一直累加,但是代码一旦停止运行,再次运行时,结果会不会接着上一次进行计算,上一次的计算结果丢失了,主要原因上每次程序运行都会初始化一个程序入口,而2次运行的程序入口不是同一个入口,所以会导致第一次计算的结果丢失,第一次的运算结果状态保存在Driver里面,所以我们如果想用上一次的计算结果,我们需要将上一次的Driver里面的运行结果状态取出来,而5.3里面的代码有一个checkpoint方法,它会把上一次Driver里面的运算结果状态保存在checkpoint的目录里面,我们在第二次启动程序时,从checkpoint里面取出上一次的运行结果状态,把这次的Driver状态恢复成和上一次Driver一样的状态
Spark学习之路 (二十三)SparkStreaming的官方文档的更多相关文章
- Spark学习之路 (二十二)SparkStreaming的官方文档
官网地址:http://spark.apache.org/docs/latest/streaming-programming-guide.html 一.简介 1.1 概述 Spark Streamin ...
- Spark(十四)SparkStreaming的官方文档
一.SparkCore.SparkSQL和SparkStreaming的类似之处 二.SparkStreaming的运行流程 2.1 图解说明 2.2 文字解说 1.我们在集群中的其中一台机器上提交我 ...
- Spark学习之路 (二十三)SparkStreaming的官方文档[转]
SparkCore.SparkSQL和SparkStreaming的类似之处 SparkStreaming的运行流程 1.我们在集群中的其中一台机器上提交我们的Application Jar,然后就会 ...
- Spark学习之路(十三)—— Spark Streaming 与流处理
一.流处理 1.1 静态数据处理 在流处理之前,数据通常存储在数据库,文件系统或其他形式的存储系统中.应用程序根据需要查询数据或计算数据.这就是传统的静态数据处理架构.Hadoop采用HDFS进行数据 ...
- Spark学习之路 (十三)SparkCore的调优之资源调优JVM的基本架构
一.JVM的结构图 1.1 Java内存结构 JVM内存结构主要有三大块:堆内存.方法区和栈. 堆内存是JVM中最大的一块由年轻代和老年代组成,而年轻代内存又被分成三部分,Eden空间.From Su ...
- 嵌入式Linux驱动学习之路(二十三)NAND FLASH驱动程序
NAND FLASH是一个存储芯片. 在芯片上的DATA0-DATA7上既能传输数据也能传输地址. 当ALE为高电平时传输的是地址. 当CLE为高电平时传输的是命令. 当ALE和CLE都为低电平时传输 ...
- IOS学习之路二十三(EGOImageLoading异步加载图片开源框架使用)
EGOImageLoading 是一个用的比较多的异步加载图片的第三方类库,简化开发过程,我们直接传入图片的url,这个类库就会自动帮我们异步加载和缓存工作:当从网上获取图片时,如果网速慢图片短时间内 ...
- 流媒体技术学习笔记之(六)FFmpeg官方文档先进音频编码(AAC)
先进音频编码(AAC)的后继格式到MP3,和以MPEG-4部分3(ISO / IEC 14496-3)被定义.它通常用于MP4容器格式; 对于音乐,通常使用.m4a扩展名.第二最常见的用途是在MKV( ...
- 看官方文档学习springcloud搭建
很多java的朋友学习新知识时候去百度,看了之后一知半解,不知道怎么操作,不知道到底什么什么东西,那么作为java码农到底该怎么学习额 一 百度是对还是错呢? 百度是一个万能的工具,当然是对也是错的 ...
随机推荐
- kubernetes微服务部署
1.哪些服务适合单独成为一个pod?哪些服务适合在一个pod中? message消息服务被很多服务调用 单独一个pod dubbo服务和web服务交互很高放在同一个pod里 API网关调用很多服务 ...
- 【托业】【新托业TOEIC新题型真题】学习笔记8-题库五->P7
———————————————————单词———————————————————— minister 部长 construction contractor 施工方 commence 开始:着手 bac ...
- Spring事务管理详解_基本原理_事务管理方式
1. 事务的基本原理 Spring事务的本质其实就是数据库对事务的支持,使用JDBC的事务管理机制,就是利用java.sql.Connection对象完成对事务的提交,那在没有Spring帮我们管理事 ...
- Recover InnoDB dictionary
为什么我们需要恢复innodb的字典信息?当我们drop 一个表时,发现误操作,这时又没有备份,那么想恢复数据是非常困难的.所以我们想恢复被删除的表时,首先就需要恢复表结构,目前已经有了undrop- ...
- elasticsearch中文分词器ik-analyzer安装
前面我们介绍了Centos安装elasticsearch 6.4.2 教程,elasticsearch内置的分词器对中文不友好,只会一个字一个字的分,无法形成词语,别急,已经有大拿把中文分词器做好了, ...
- vue中filter的用法
test() { var arr1 = ["A", "B", "C","C","A"]; var r ...
- css中 ~的作用
这是 CSS3 element1~element2 选择器 定义和用法 element1~element2 选择器 element1 之后出现的所有 element2. 两种元素必须拥有相同的父元素, ...
- vue中$emit 和$on 和$set的用法
1.$set的用法:给 student对象新增 age 属性 data () { return { student: { name:"里斯'} } } 直接给student赋值不会触发视图更 ...
- PHP数字字符串左侧补0、字符串填充和自动补齐的几种方法
一.数字补0. 如果要自动生成学号,自动生成某某编号,就像这样的形式“d0000009”.“d0000027”时,那么就会面临一个问题,怎么把左边用0补齐成这样8位数的编码呢?我想到了两种方法实现这个 ...
- import Tkinter error, no module named tkinter: "Python may not be configured for Tk”
install required devel module in your linux: yum install tk-devel yum install tcl-devel then,reconfi ...