潭州课堂25班:Ph201805201 爬虫高级 第一课 pyspider框架 (课堂笔记)
利用wheel安装
S1: pip install wheel
S2: 进入www.lfd.uci.edu/~gohlke/pythonlibs/,Ctrl + F查找pycurl
这个包名是pycurl-版本-你下载的python版本(如python3.4,就是cp34)-win32/64操作系统),选择你所需要的进行下载
S4: 安装编译包,命令行输入 pip install 你下载的whl文件的位置如(d:\pycurl-7.43.1-cp34-cp34m-win_amd64.whl)
S5: 继续pip install pyspider
pip install 安装好后
在 cmd 中运行
有这出现,说明安装成功
浏览器中输入 http://127.0.0.1:5000/


js渲染的页面数据不容易抓取,因为 http 请求库是能直接运行 js 代码 的 如urlilb, requests
而 pyspider 是支持 js 的
当出现 SSL错误时,
我们在 requests 中添加 参数 verify = False
在pyspider中我没设置 validate_cert = False
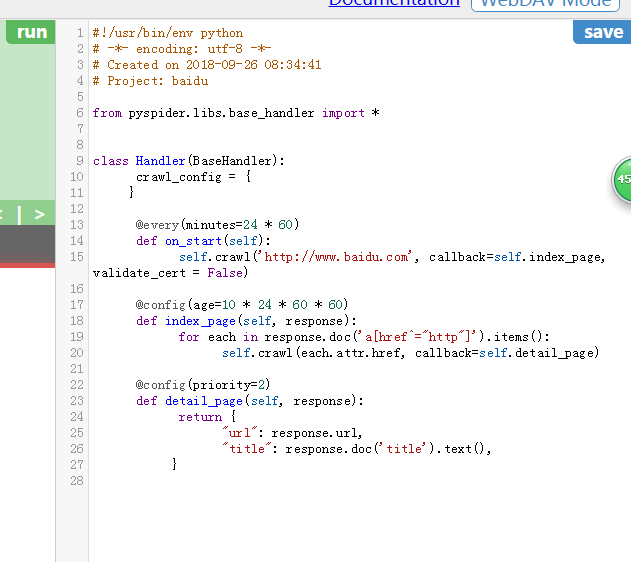
在这里,
on_start 是程序入口,当在web 页面点击 run 的时候调用
self.crawl 生成一个新的爬邓任务,
doc('a[href^="http"]')
匹配 a 标签中的 href 以 http 开头的内容
要在框架中显示js渲染后的页面
Phantomjs 无界面浏览器
在 win 下,下载后,添加环境变量
fetch_type =' js'
删除一个项目
把 name 改为: delete ,状态为 stop 24小时后自动删除
py操作数据库
# -*- coding:utf-8 -*-
# 斌彬电脑
# @Time : 2018/9/26 0026 下午 3:39
import pymysql
# import sclapy
class a():
def __init__(self):
self.db = pymysql.connect(
host = '127.0.0.1', # 远程 ip
port=3306, # mysql 端口
user='binbin', # 用户名
password = 'qwe123', # 密码
db = 'binbin', # 数据库
charset="utf8" # 编码
)
self.cur = self.db.cursor() # 定义游标 def add_items(self):
# def add_items(self,url,title,nr,h):
try:
# 往表格里写数据
sql ="insert into bb(url,title,内容,时间与点击次数) value(%s,%s,%s,%s)"
self.cur.execute(sql,['bindu','a','c','d'])
self.db.commit() # 提交事务
a = self.cur.execute( 'select * from bb' )
print(a)
except Exception as e:
self.db.rollback() # 数据回滚 a = a()
a.add_items()
# print(a)
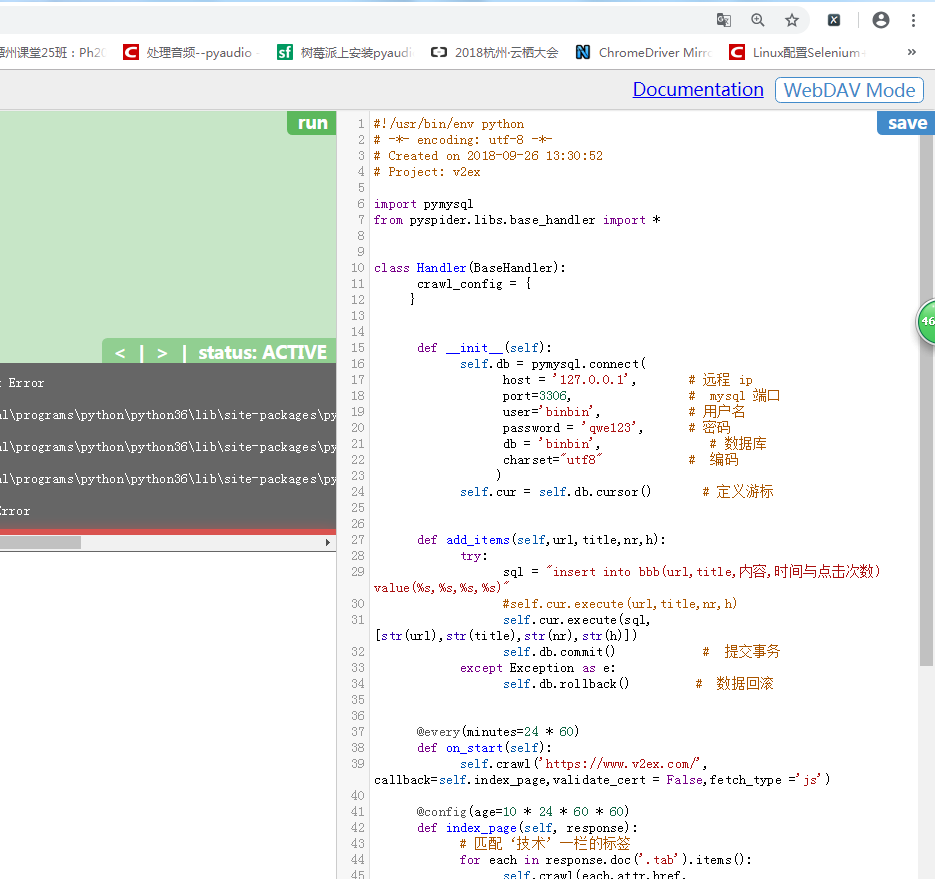
将爬到的数据写入数据库
潭州课堂25班:Ph201805201 爬虫高级 第一课 pyspider框架 (课堂笔记)的更多相关文章
- 潭州课堂25班:Ph201805201 爬虫高级 第二课 sclapy 框架 (课堂笔记)
win 下安装 sclapy 先安装 pip install wheel py 库下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 在这 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第九课 scrapyd 部署 (课堂笔记)
c rapyd是 scrapy 的部署, 是官方提供的一个爬虫管理工具, 通过他可以非常方便的上传控制爬虫的运行, 安装 : pip install scapyd 他提供了一个json ,web, s ...
- 潭州课堂25班:Ph201805201 爬虫基础 第一课 (课堂笔记)
爬虫的概念: 其实呢,爬虫更官方点的名字叫数据采集,英文一般称作spider,就是通过编程来全自动的从互联网上采集数据.比如说搜索引擎就是一种爬虫.爬虫需要做的就是模拟正常的网络请求,比如你在网站上点 ...
- 潭州课堂25班:Ph201805201 爬虫基础 第九课 图像处理- PIL (课堂笔记)
Python图像处理-Pillow 简介 Python传统的图像处理库PIL(Python Imaging Library ),可以说基本上是Python处理图像的标准库,功能强大,使用简单. 但是由 ...
- 潭州学院-JavaVIP的Javascript的高级进阶-KeKe老师
潭州学院-JavaVIP的Javascript的高级进阶-KeKe老师 讲的不错,可以学习 下面是教程的目录截图: 下载地址:http://www.fu83.cn/thread-283-1-1.htm ...
- 潭州课堂25班:Ph201805201 WEB 之 页面编写 第四课 登录注册 (课堂笔记)
index.html 首页 <!DOCTYPE html> <html lang="en"> <head> <meta charset=& ...
- 潭州课堂25班:Ph201805201 WEB 之 页面编写 第三课 (课堂笔记)
index.html <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- 潭州课堂25班:Ph201805201 WEB 之 页面编写 第二课 (课堂笔记)
index.html <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- 潭州课堂25班:Ph201805201 WEB 之 页面编写 第一课 (课堂笔记)
index.html <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
随机推荐
- python学习之argparse模块
python学习之argparse模块 一.简介: argparse是python用于解析命令行参数和选项的标准模块,用于代替已经过时的optparse模块.argparse模块的作用是用于解析命令行 ...
- mysql系列一、mysql数据库规范
一. 表设计 库名.表名.字段名必须使用小写字母,“_”分割. 库名.表名.字段名必须不超过12个字符. 库名.表名.字段名见名知意,建议使用名词而不是动词. 表必须使用InnoDB存储引擎. 表必须 ...
- 利用autocomplete.js实现仿百度搜索效果(ajax动态获取后端[C#]数据)
实现功能描述: 1.实现搜索框的智能提示 2.第二次浏览器缓存结果 3.实现仿百度搜索 <!DOCTYPE html> <html xmlns="http://www.w3 ...
- eclipse里访问tomcat首页出现404错误解决之法
首先,添加Tomcat.在菜单栏找到Window—Preferences—Server—Runtime Environments—Add—Apache—选择Tomcat版本—找到Tomcat文件的路径 ...
- php获取POST数据的三种方法
方法一,$_POST $_POST或$_REQUEST存放的是PHP以key=>value的形式格式化以后的数据. $_POST方式是通过 HTTP POST 方法传递的变量组成的数组,是自动全 ...
- XPATH语法(一)
Xpath简介 XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言.XPath基于XML的树状结构,有不同类型的节点,包括元素节点,属性节点和文本节点 ...
- js闭包实例汇总
本文是通过实例来帮助大家深刻理解js闭包,是篇非常不错的文章,这里推荐给大家,有需要的小伙伴可以参考下 Js闭包 闭包前要了解的知识 1. 函数作用域 (1).Js语言特殊之处在于函数内部可以直接读取 ...
- LeetCode(27): 移除元素
Easy! 题目描述: 给定一个数组 nums 和一个值 val,你需要原地移除所有数值等于 val 的元素,返回移除后数组的新长度. 不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1 ...
- python----多继承C3算法
https://blog.csdn.net/fmblzf/article/details/52512145
- Java字符串的操作
判断字符串是否存在 使用str.contains("values") public class one { /*判断某个字符串是否存在*/ public static void m ...