022 Spark shuffle过程
1.官网
http://spark.apache.org/docs/1.6.1/configuration.html#shuffle-behavior
Spark数据进行重新分区的操作就叫做shuffle过程

2.介绍
SparkStage划分的时候,将最后一个Stage称为ResultStage(ResultTask),其它Stage叫做ShuffleMapStage(ShuffleMapTask)

3.SparkShuffle实现
基于ShuffleManager来实现,1.6.1版本中存在两种实现:HashShuffleManager和SortShuffleManager(默认);
由参数spark.shuffle.manager决定(sort or hash)
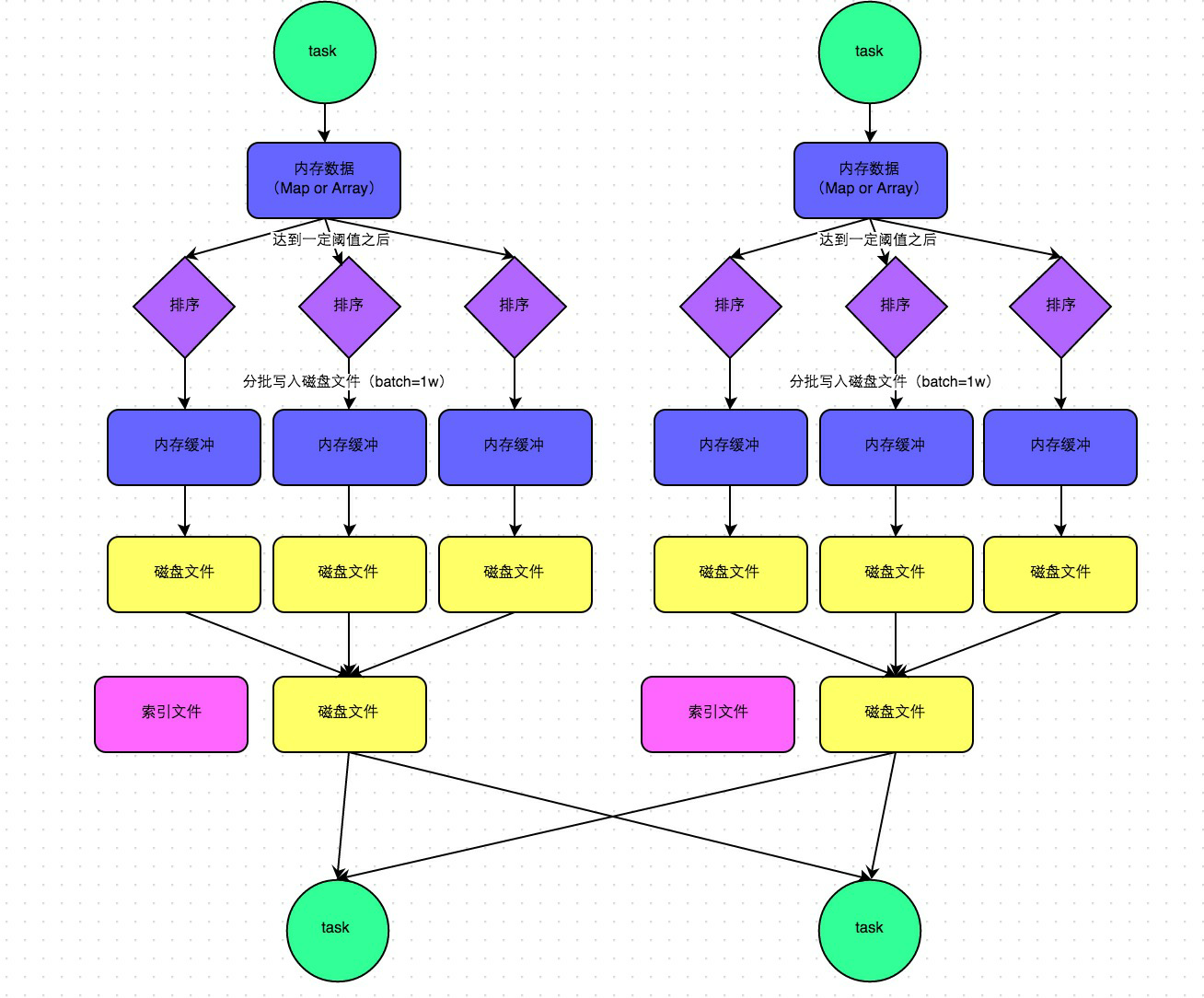
其中,sort:类似MR的shuffle,如下:
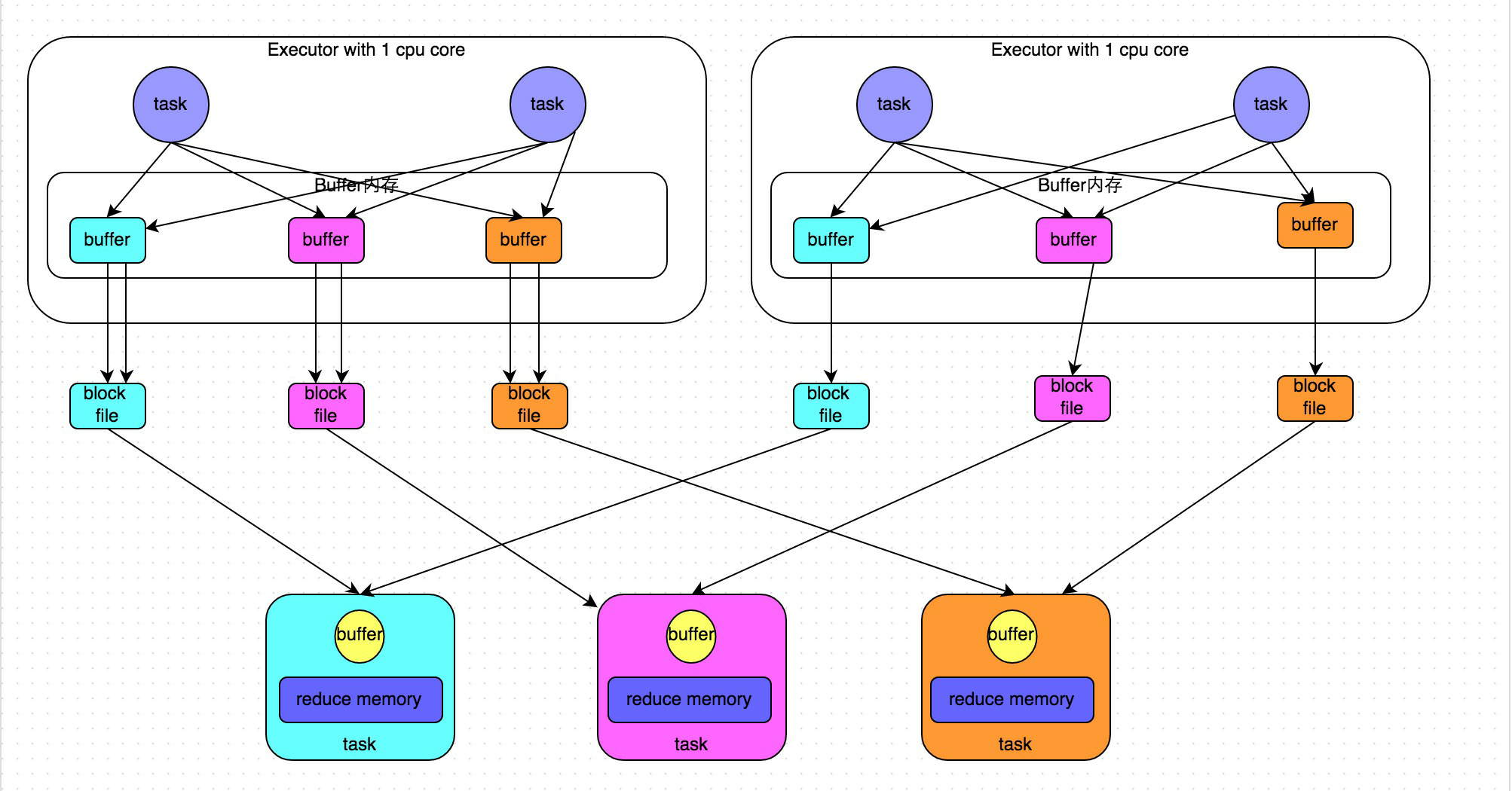
4.hash shuffle
在Spark1.2.x版本之前,只有一个ShuffleManager,就是hash
hash shuffle在以前的版本中存在一个问题:
会产生大量的磁盘问题
优化:
将一个Executor上的所有Task的执行结果合并到一起,减少文件的数量
spark.shuffle.consoldateFiles=true
原hash下的原理:

优化原理:
5.sort shuffle
在1.2版本之后,默认是SortManager,就是sort
小问题:所有的情况都进行排序(不管数据量的大小)<通过bypass运行模式可以解决>
两种运行:
普通运行模式:
中间会涉及到sort操作
bypass运行模式:
针对小数据量的情况下,不进行排序,类似于优化后的HashManager(性能没有HashManager<优化后>高)
下面是两个条件,就会走bypass模式,小数据量不排序:
-1. 当RDD的task数量小于spark.shuffle.sort.bypassMergeThreshold(默认200)的时候启用
-2. 不是聚合类shuffle算子(比如:不能是reduceByKey,可以是join)
二:shuffle与依赖的关系
1.说明
在后面补充一下知识点
2.关系

022 Spark shuffle过程的更多相关文章
- Spark Shuffle 过程
本文参考:http://www.cnblogs.com/cenyuhai/p/3826227.html 在数据流动的整个过程中,最复杂最影响性能的环节,就是 Shuffle 过程,本文将参考大神的博客 ...
- 浅析 Spark Shuffle 内存使用
在使用 Spark 进行计算时,我们经常会碰到作业 (Job) Out Of Memory(OOM) 的情况,而且很大一部分情况是发生在 Shuffle 阶段.那么在 Spark Shuffle 中具 ...
- Spark Shuffle数据处理过程与部分调优(源码阅读七)
shuffle...相当重要,为什么咩,因为shuffle的性能优劣直接决定了整个计算引擎的性能和吞吐量.相比于Hadoop的MapReduce,可以看到Spark提供多种计算结果处理方式,对shuf ...
- Spark shuffle详细过程
有许多场景下,我们需要进行跨服务器的数据整合,比如两个表之间,通过Id进行join操作,你必须确保所有具有相同id的数据整合到相同的块文件中.那么我们先说一下mapreduce的shuffle过程. ...
- 彻底搞懂spark的shuffle过程(shuffle write)
什么时候需要 shuffle writer 假如我们有个 spark job 依赖关系如下 我们抽象出来其中的rdd和依赖关系: E <-------n------, ...
- Spark 的 Shuffle过程介绍`
Spark的Shuffle过程介绍 Shuffle Writer Spark丰富了任务类型,有些任务之间数据流转不需要通过Shuffle,但是有些任务之间还是需要通过Shuffle来传递数据,比如wi ...
- 剖析Hadoop和Spark的Shuffle过程差异
一.前言 对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交.并.差.聚合.排序等过程.而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么 ...
- 剖析Hadoop和Spark的Shuffle过程差异(一)
一.前言 对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交.并.差.聚合.排序等过程.而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么 ...
- Spark的Shuffle过程介绍
Spark的Shuffle过程介绍 Shuffle Writer Spark丰富了任务类型,有些任务之间数据流转不需要通过Shuffle,但是有些任务之间还是需要通过Shuffle来传递数据,比如wi ...
随机推荐
- pyqt5的安装
第一步:需要安装:pip3 install pyqt5 安装工具:pip3 install pyqt5-tools 第二步:打开Pycharm,进入设置,添加外部工具 file-->sett ...
- Pyqt5自定义浏览器
from PyQt5.QtWebChannel import QWebChannel from PyQt5.QtWebEngineWidgets import QWebEngineView from ...
- 【Gradle】Gradle在IDEA中的使用
新建项目 . Import Module from Gradle窗口选择 类别 含义 Use auto-import 是否开启自动导入,若开启修改gradle脚本文件后会自动检测变化并对项目进行刷新 ...
- Centos7.5 防火墙设置
Centos7.5默认使用firewalld作为防火墙 1.查看firewalld服务状态 systemctl status firewalld 2.查看firewalld的状态 firewall-c ...
- ubuntu16.04安装opencv2.4.13
1.更新 sudo apt-get update sudo apt-get upgrade 2.安装关联库 2.1 搭建C/C++编译环境 sudo apt-get install build-ess ...
- MPI 在Windows10 上安装,使用VS2013编译生成可执行程序
原文地址:http://www.cnblogs.com/leijin0211/p/6851789.html 参考博客: http://www.cnblogs.com/shixiangwan/p/662 ...
- 解决Myeclipse启动Spring Boot项目报出莫名异常
有时候明明代码.配置都是正确的,但是一启动却报出莫名其妙的异常. 主要原因是resource包下的xml.yml文件或者其他配置文件路径不正确,解决方法如下: 第一步. 第二步.如果Excluded不 ...
- sysbench安装、对Mysql压力测试、结果解读及mysql数据库跟踪优化
sysbench是一款开源的多线程性能测试工具,可以执行CPU/内存/线程/IO/数据库等方面的性能测试. sysbench支持以下几种测试模式: 1.CPU运算性能 2.磁盘IO性能 3.调度程序性 ...
- centos6.5下编译安装mariadb-10.0.20
源码编译安装mariadb-10.0.20.tar.gz 一.安装cmake编译工具 跨平台编译器 # yum install -y gcc* # yum install -y cmake 解决依赖关 ...
- Android studio下将项目代码上传至github包括更新,同步,创建依赖
AS中设置GIT 一.开篇 本文讲如何使用Android Studio将项目上传到github,虽然讲上传github的文章很多,但是大部分都是使用Git Bash命令行,虽然效率高些,但是有点麻烦, ...