022 Spark shuffle过程
1.官网
http://spark.apache.org/docs/1.6.1/configuration.html#shuffle-behavior
Spark数据进行重新分区的操作就叫做shuffle过程

2.介绍
SparkStage划分的时候,将最后一个Stage称为ResultStage(ResultTask),其它Stage叫做ShuffleMapStage(ShuffleMapTask)

3.SparkShuffle实现
基于ShuffleManager来实现,1.6.1版本中存在两种实现:HashShuffleManager和SortShuffleManager(默认);
由参数spark.shuffle.manager决定(sort or hash)
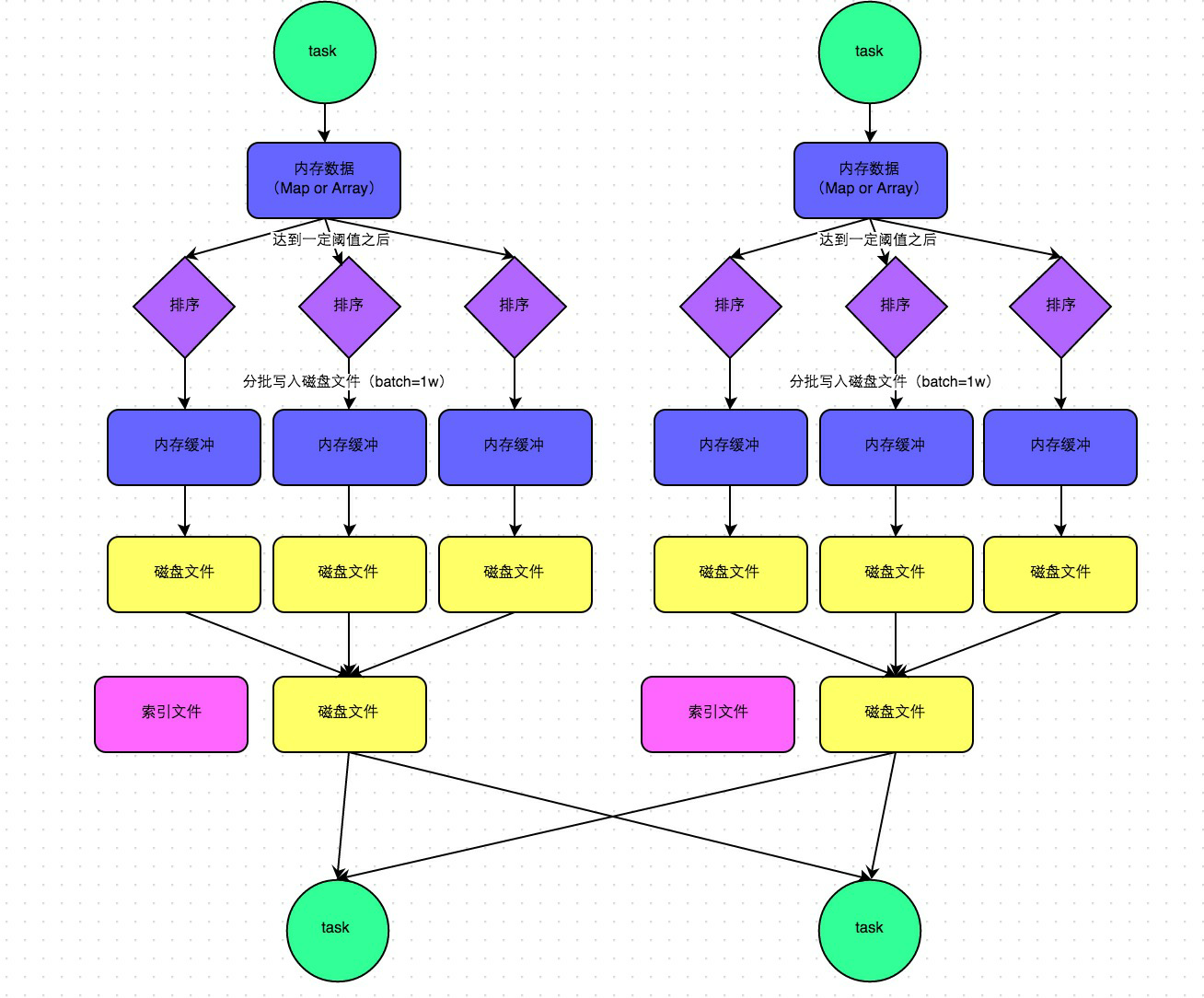
其中,sort:类似MR的shuffle,如下:
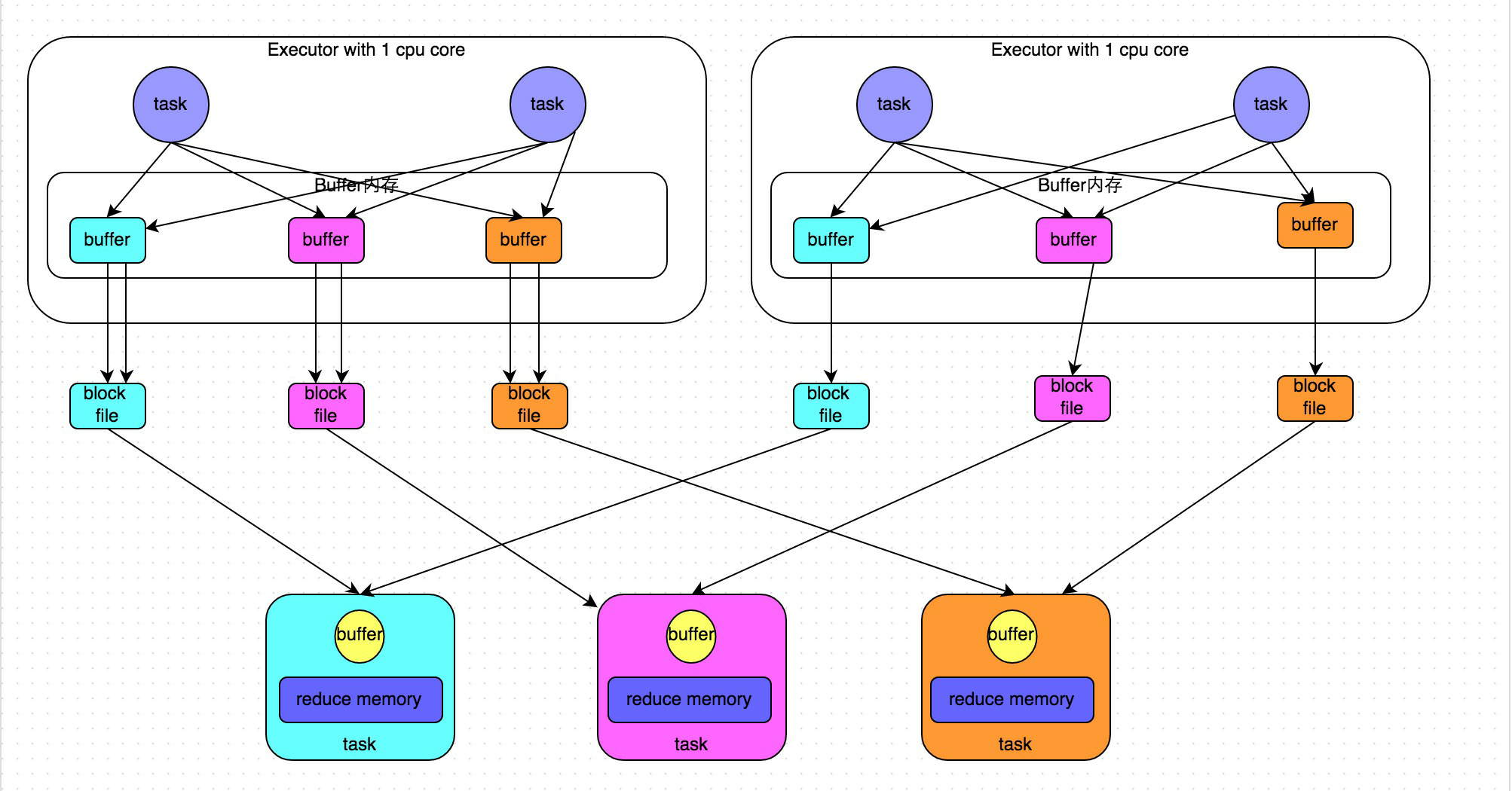
4.hash shuffle
在Spark1.2.x版本之前,只有一个ShuffleManager,就是hash
hash shuffle在以前的版本中存在一个问题:
会产生大量的磁盘问题
优化:
将一个Executor上的所有Task的执行结果合并到一起,减少文件的数量
spark.shuffle.consoldateFiles=true
原hash下的原理:

优化原理:
5.sort shuffle
在1.2版本之后,默认是SortManager,就是sort
小问题:所有的情况都进行排序(不管数据量的大小)<通过bypass运行模式可以解决>
两种运行:
普通运行模式:
中间会涉及到sort操作
bypass运行模式:
针对小数据量的情况下,不进行排序,类似于优化后的HashManager(性能没有HashManager<优化后>高)
下面是两个条件,就会走bypass模式,小数据量不排序:
-1. 当RDD的task数量小于spark.shuffle.sort.bypassMergeThreshold(默认200)的时候启用
-2. 不是聚合类shuffle算子(比如:不能是reduceByKey,可以是join)
二:shuffle与依赖的关系
1.说明
在后面补充一下知识点
2.关系

022 Spark shuffle过程的更多相关文章
- Spark Shuffle 过程
本文参考:http://www.cnblogs.com/cenyuhai/p/3826227.html 在数据流动的整个过程中,最复杂最影响性能的环节,就是 Shuffle 过程,本文将参考大神的博客 ...
- 浅析 Spark Shuffle 内存使用
在使用 Spark 进行计算时,我们经常会碰到作业 (Job) Out Of Memory(OOM) 的情况,而且很大一部分情况是发生在 Shuffle 阶段.那么在 Spark Shuffle 中具 ...
- Spark Shuffle数据处理过程与部分调优(源码阅读七)
shuffle...相当重要,为什么咩,因为shuffle的性能优劣直接决定了整个计算引擎的性能和吞吐量.相比于Hadoop的MapReduce,可以看到Spark提供多种计算结果处理方式,对shuf ...
- Spark shuffle详细过程
有许多场景下,我们需要进行跨服务器的数据整合,比如两个表之间,通过Id进行join操作,你必须确保所有具有相同id的数据整合到相同的块文件中.那么我们先说一下mapreduce的shuffle过程. ...
- 彻底搞懂spark的shuffle过程(shuffle write)
什么时候需要 shuffle writer 假如我们有个 spark job 依赖关系如下 我们抽象出来其中的rdd和依赖关系: E <-------n------, ...
- Spark 的 Shuffle过程介绍`
Spark的Shuffle过程介绍 Shuffle Writer Spark丰富了任务类型,有些任务之间数据流转不需要通过Shuffle,但是有些任务之间还是需要通过Shuffle来传递数据,比如wi ...
- 剖析Hadoop和Spark的Shuffle过程差异
一.前言 对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交.并.差.聚合.排序等过程.而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么 ...
- 剖析Hadoop和Spark的Shuffle过程差异(一)
一.前言 对于基于MapReduce编程范式的分布式计算来说,本质上而言,就是在计算数据的交.并.差.聚合.排序等过程.而分布式计算分而治之的思想,让每个节点只计算部分数据,也就是只处理一个分片,那么 ...
- Spark的Shuffle过程介绍
Spark的Shuffle过程介绍 Shuffle Writer Spark丰富了任务类型,有些任务之间数据流转不需要通过Shuffle,但是有些任务之间还是需要通过Shuffle来传递数据,比如wi ...
随机推荐
- javascript 回到顶部
<script type="text/javascript"> window.onload = function(){ var timer = null; //用于判断 ...
- Mongodb 副本集
mongodb主从模式就是一个 单副本的应用:没有很好的扩展性和容错性: 副本集的多个副本保证了容错性:主服务器负责整个副本集的读写,副本集定时同步数据:主节点挂掉:副本集会自动选举一个主的服务器: ...
- luogu P1600 天天爱跑步
传送门 1A此题暴祭 (下面记点\(x\)深度为\(de_x\),某个时间点记为\(w_x\)) 首先,每条路径是可以拆成往上和往下两条路径的 对于往上的路径,假设有个人往上跑,\(w_y\)在点\( ...
- Java 注解 (Annotation)你可以这样学
注解语法 因为平常开发少见,相信有不少的人员会认为注解的地位不高.其实同 classs 和 interface 一样,注解也属于一种类型.它是在 Java SE 5.0 版本中开始引入的概念. 注解的 ...
- shiroWeb项目-认证及MD5认证信息在页面显示(十)
realm设置完整认证信息 // realm的认证方法,从数据库查询用户信息 @Override protected AuthenticationInfo doGetAuthenticationInf ...
- 推荐系统之矩阵分解及C++实现
1.引言 矩阵分解(Matrix Factorization, MF)是传统推荐系统最为经典的算法,思想来源于数学中的奇异值分解(SVD), 但是与SVD 还是有些不同,形式就可以看出SVD将原始的评 ...
- npm 无法安装 ionic 解决办法
一般从 node.js官网下载安装完之后,npm也会同时安装完. 如果通过 $ npm install -g cordova ionic 去安装,往往会失败.这个是由于GFW,很多插件下载不下来,还好 ...
- Faster rcnn代码理解(4)
上一篇我们说完了AnchorTargetLayer层,然后我将Faster rcnn中的其他层看了,这里把ROIPoolingLayer层说一下: 我先说一下它的实现原理:RPN生成的roi区域大小是 ...
- shell-检测服务是否运行,并记日志
目的:每隔*分钟检测服务是否运行:若运行中,则记录执行的进程名称:若不运行,记录当前时间 shell: #!/bin/bash date=`date +%Y%m%d` log=/home/mono_$ ...
- Linux mmc framework2:基本组件之block
1.前言 本文主要block组件的主要流程,在介绍的过程中,将详细说明和block相关的流程,涉及到其它组件的详细流程再在相关文章中说明. 2.主要数据结构和API 2.1 struct mmc_ca ...