浅谈压缩感知(十九):MP、OMP与施密特正交化
关于MP、OMP的相关算法与收敛证明,可以参考:http://www.cnblogs.com/AndyJee/p/5047174.html,这里仅简单陈述算法流程及二者的不同之处。
主要内容:
- MP的算法流程及其MATLAB实现
- OMP的算法流程以及MATLAB实现
- MP与OMP的区别
- 施密特正交化与OMP的关系
一、MP(匹配追踪)的算法流程:

二、MP的MATLAB实现:
% MP:匹配追踪算法
% dictionary: 超完备字典
% x: 待表示信号
% M = ; N = ;
% Phi = randn(M,N); % 字典
% for nn = :N
% Phi(:,nn) = Phi(:,nn)/norm(Phi(:,nn));
% end
% b = randn(M,); % 信号
function x = MP(dictionary,x,iter)
[M,N] = size(dictionary);
residual = zeros(M,iter); %残差矩阵,保存每次迭代后的残差
residual(:,) = x; %初始化残差为x
L = size(residual,); %得到残差矩阵的列
pos_num = zeros(,L); %用来保存每次选择的列序号
resi_norm = zeros(,L); %用来保存每次迭代后的残差的2范数
resi_norm() = norm(x); %因为前面已初始化残差为x
iter_out = 1e-;
iter_count = ; for mm = :iter
%迭代退出条件
if resi_norm(mm) < iter_out
break;
end
%求出dictionary每列与上次残差的内积
scalarproducts = dictionary'*residual(:,mm);
%找到内积中最大的列及其内积值
[val,pos] = max(abs(scalarproducts));
%更新残差
residual(:,mm+) = residual(:,mm) - scalarproducts(pos)*dictionary(:,pos);
%计算残差的2范数(平方和再开根号)
resi_norm(mm+) = norm(residual(:,mm+));
%保存选择的列序号
pos_num(mm) = pos;
iter_count = iter_count + ;
end
%绘出残差的2范数曲线
resi_norm = resi_norm(:iter_count+);
plot(resi_norm);grid;
%显示选择的字典原子
pos_num = pos_num(:iter_count);
disp(pos_num);
%稀疏系数(稀疏表示)
dict = dictionary(:,pos_num);
y_vec = (dict'*dict)^(-1)*dict'*x;
disp(y_vec);
figure;plot(y_vec);
三、OMP(正交匹配追踪)的算法流程:

四、OMP的MATLAB实现:
% MP:匹配追踪算法
% dictionary: 超完备字典
% x: 待表示信号
% M = ; N = ;
% Phi = randn(M,N); % 字典
% for nn = :N
% Phi(:,nn) = Phi(:,nn)/norm(Phi(:,nn));
% end
% b = randn(M,); % 信号
function x = OMP(dictionary,x,iter)
[M,N] = size(dictionary);
residual = zeros(M,iter); %残差矩阵,保存每次迭代后的残差
residual(:,) = x; %初始化残差为x
L = size(residual,); %得到残差矩阵的列
pos_num = zeros(,L); %用来保存每次选择的列序号
resi_norm = zeros(,L); %用来保存每次迭代后的残差的2范数
resi_norm() = norm(x); %因为前面已初始化残差为x
iter_out = 1e-;
iter_count = ;
aug_mat = []; for mm = :iter
%迭代退出条件
if resi_norm(mm) < iter_out
break;
end
%求出dictionary每列与上次残差的内积
scalarproducts = dictionary'*residual(:,mm);
%找到内积中最大的列及其内积值
[val,pos] = max(abs(scalarproducts));
%最小二乘的增广矩阵
aug_mat = [aug_mat dictionary(:,pos)];
%最小二乘投影
proj_y = aug_mat*(aug_mat'*aug_mat)^(-1)*aug_mat'*x;
%更新残差
residual(:,mm+) = x - proj_y;
%计算残差的2范数(平方和再开根号)
resi_norm(mm+) = norm(residual(:,mm+));
%保存选择的列序号
pos_num(mm) = pos;
iter_count = iter_count + ;
end
%绘出残差的2范数曲线
resi_norm = resi_norm(:iter_count+);
plot(resi_norm);grid;
%显示选择的字典原子
pos_num = pos_num(:iter_count);
disp(pos_num);
%稀疏系数
dict = dictionary(:,pos_num);
y_vec = (dict'*dict)^(-1)*dict'*x;
disp(y_vec);
figure;plot(y_vec);
五、MP与OMP的区别:
OMP与MP的不同根本在于残差更新过程:OMP减去的Pem是em在所有被选择过的原子组成的矩阵Φt所张成空间上的正交投影,而MP减去的Pem是em在本次被选择的原子φm所张成空间上的正交投影。基于此,OMP可以保证已经选择过的原子不会再被选择。
六、施密特(Schimidt)正交化与OMP
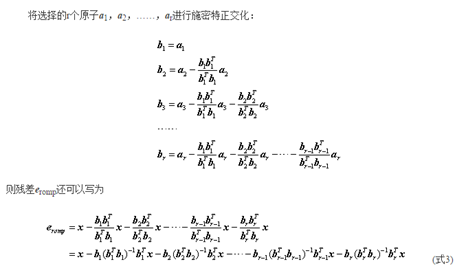
1、施密特(Schimidt)正交化的过程:

上面的的[x,y]表示向量内积,[x,y]=xTy=yTx=[x,y]。施密特正交化公式中的br实际上可写为:

分子之所以可以这么变化是由于[x,y]实际上为一个数,因此[x,y]x=x[x,y]= xxTy。
2、OMP与施密特(Schimidt)正交化的关系:
结论:OMP分解过程,实际上是将所选原子依次进行Schimidt正交化,然后将待分解信号减去在正交化后的原子上各自的分量即可得残差。其实(式3)求残差的过程也是在进行施密特正交化。

3、验证OMP残差求解过程与Schmidt正交化的关系
% 验证OMP残差求解过程与Schmidt正交化的关系
%
clc;clear;close all;
M = ; N = ;
Phi = randn(M,N); % 字典
for nn = :N
Phi(:,nn) = Phi(:,nn)/norm(Phi(:,nn));
end
b = randn(M,); % 信号
res0 = b; % 初始化残差为待稀疏信号b
% OMP
% 选择字典第一个原子
c1 = Phi'* res0; % 求矩阵Phi各列与b的内积
[val1,pos1] = max(abs(c1)); % 找到内积中最大的列及其内积值
phit = [Phi(:,pos1)]; % 由所有选出的列组合的矩阵
Pphi = phit*(phit'*phit)^(-1)*phit'; % 正交投影变换矩阵
omp_res1 = res0 - Pphi*res0; % OMP用上一次残差减去残差在phit列空间的正交投影
omp_resb = b - Pphi*b; % OMP用待稀疏信号b减去b在phit列空间的正交投影
% Schimidt
x = Phi(:,pos1); % Schimidt正交化第一个向量
Px = x*(x'*x)^(-1)*x';
smt_res1 = res0 - Px*b; % 实际上是b - Px*b
% test
norm(omp_res1-omp_resb)
norm(omp_resb-smt_res1) % OMP
% 选择字典第二列
c2 = Phi' * omp_res1;
[val2,pos2] = max(abs(c2));
phit = [Phi(:,pos1) Phi(:,pos2)];
Pphi = phit*(phit'*phit)^(-1)*phit';
omp_res2 = omp_res1 - Pphi*omp_res1;
omp_resb = b - Pphi*b;
% Schimidt
y = Phi(:,pos2) - Px*Phi(:,pos2); % Schimidt正交化第二个向量
Py = y*(y'*y)^(-1)*y';
smt_res2 = smt_res1 - Py*b; % 实际上是b - Px*b - Py*b,上一次残差减去b在第2列正交化所得z上的投影
% test
norm(omp_res2-omp_resb)
norm(omp_resb-smt_res2) % OMP
% 选择字典第三列
c3 = Phi' * omp_res2;
[val3,pos3] = max(abs(c3));
phit = [Phi(:,pos1) Phi(:,pos2) Phi(:,pos3)];
Pphi = phit*(phit'*phit)^(-1)*phit';
omp_res3 = omp_res2 - Pphi*omp_res2;
omp_resb = b - Pphi*b;
% Schimidt
z = Phi(:,pos3) - Px*Phi(:,pos3) - Py*Phi(:,pos3); % Schimidt正交化第三个向量
Pz = z*(z'*z)^(-1)*z';
smt_res3 = smt_res2 - Pz*b; % 实际上是b - Px*b - Py*b - Pz*b,上一次残差减去b在第3列正交化所得z上的投影
% test
norm(omp_res3-omp_resb)
norm(omp_resb-smt_res3)
参考文章:
http://blog.csdn.net/jbb0523/article/details/45099655
http://blog.csdn.net/jbb0523/article/details/45100351
浅谈压缩感知(十九):MP、OMP与施密特正交化的更多相关文章
- 浅谈压缩感知(九):正交匹配追踪算法OMP
主要内容: OMP算法介绍 OMP的MATLAB实现 OMP中的数学知识 一.OMP算法介绍 来源:http://blog.csdn.net/scucj/article/details/7467955 ...
- 浅谈压缩感知(二十一):压缩感知重构算法之正交匹配追踪(OMP)
主要内容: OMP的算法流程 OMP的MATLAB实现 一维信号的实验与结果 测量数M与重构成功概率关系的实验与结果 稀疏度K与重构成功概率关系的实验与结果 一.OMP的算法流程 二.OMP的MATL ...
- 浅谈压缩感知(二十):OMP与压缩感知
主要内容: OMP在稀疏分解与压缩感知中的异同 压缩感知通过OMP重构信号的唯一性 一.OMP在稀疏分解与压缩感知中的异同 .稀疏分解要解决的问题是在冗余字典(超完备字典)A中选出k列,用这k列的线性 ...
- 浅谈压缩感知(二十四):压缩感知重构算法之子空间追踪(SP)
主要内容: SP的算法流程 SP的MATLAB实现 一维信号的实验与结果 测量数M与重构成功概率关系的实验与结果 SP与CoSaMP的性能比较 一.SP的算法流程 压缩采样匹配追踪(CoSaMP)与子 ...
- 浅谈压缩感知(三十):压缩感知重构算法之L1最小二乘
主要内容: l1_ls的算法流程 l1_ls的MATLAB实现 一维信号的实验与结果 前言 前面所介绍的算法都是在匹配追踪算法MP基础上延伸的贪心算法,从本节开始,介绍基于凸优化的压缩感知重构算法. ...
- 浅谈压缩感知(二十八):压缩感知重构算法之广义正交匹配追踪(gOMP)
主要内容: gOMP的算法流程 gOMP的MATLAB实现 一维信号的实验与结果 稀疏度K与重构成功概率关系的实验与结果 一.gOMP的算法流程 广义正交匹配追踪(Generalized OMP, g ...
- 浅谈压缩感知(二十六):压缩感知重构算法之分段弱正交匹配追踪(SWOMP)
主要内容: SWOMP的算法流程 SWOMP的MATLAB实现 一维信号的实验与结果 门限参数a.测量数M与重构成功概率关系的实验与结果 SWOMP与StOMP性能比较 一.SWOMP的算法流程 分段 ...
- 浅谈压缩感知(二十五):压缩感知重构算法之分段正交匹配追踪(StOMP)
主要内容: StOMP的算法流程 StOMP的MATLAB实现 一维信号的实验与结果 门限参数Ts.测量数M与重构成功概率关系的实验与结果 一.StOMP的算法流程 分段正交匹配追踪(Stagewis ...
- 浅谈压缩感知(二十二):压缩感知重构算法之正则化正交匹配追踪(ROMP)
主要内容: ROMP的算法流程 ROMP的MATLAB实现 一维信号的实验与结果 测量数M与重构成功概率关系的实验与结果 一.ROMP的算法流程 正则化正交匹配追踪ROMP算法流程与OMP的最大不同之 ...
随机推荐
- wpf 自定义属性的默认值
public int MaxSelectCount { get { return (int)GetValue(MaxSelectCountProperty); } set { SetValue(Max ...
- 自己理解Java中的lambda
lambda是什么 "Lambda 表达式"(lambda expression)是一个匿名函数,Lambda表达式基于数学中的λ演算得名,直接对应于其中的lambda抽象(lam ...
- hdu1024线性dp
/* dp[i][j]表示取第i个数时分成了j块 要么是将第i个数加入j块中的最后一块,要么是自成一块,加上前面j-1块的和 状态转移方程: dp[i][j]=max(dp[i-1][j]+a[i], ...
- tyvj1051 选课
/* 分组背包+树形dp:以树的深度作为阶段,以节点编号作为一维状态, 思路:首先dp[u][t]表示选择以第u门课为根,选了t门课的最大值, 状态转移方程dp[u][t]=max(所有儿子中凑出t- ...
- 性能测试十六:liunx下jmete配置环境变量
修改环境变量后就不用每次手动输入路径,省时省事,减少命令长度和出错率 按Ctrl+L可进行翻页,翻页到最后一行,此处有java的环境变量 添加jmeter的目录和bin目录 此时,虽修改成功,但是并未 ...
- web中切图、快速切图与web雪碧图制作的方法
声明: web小白的笔记,欢迎大神指点,联系QQ:1522025433. 工具:Photoshop 1.复制文字:点击文章工具后选择文字. 2.矩形选框工具 看信息 f8, 取消矩形选框 Ctrl+D ...
- python 全栈开发,Day5(字典,增删改查,其他操作方法)
一.字典 字典是python中唯一的映射类型,采用键值对(key-value)的形式存储数据.存储大量的数据,是关系型数据,查询数据快. 列表是从头遍历到尾字典使用二分查找 二分查找也称折半查找(Bi ...
- bind函数详解(转)
var name = "The Window"; var object = { name: "My Object", getNameFunc: function ...
- [转] Optimizely:在线网站A/B测试平台
Optimizely:在线网站A/B测试平台是一家提供 A/B 测试服务的公司.A/B 测试能够对比不同版本的设计,选取更吸引用户眼球的那一款,从而带来更为优化的个人体验.让网站所有者易于对不同版本的 ...
- [APIO2011]方格染色
题解: 挺不错的一道题目 首先4个里面只有1个1或者3个1 那么有一个特性就是4个数xor为1 为什么要用xor呢? 在于xor能把相同的数消去 然后用一般的套路 看看确定哪些值能确定全部 yy一下就 ...