微软BI 之SSAS 系列 - 多维数据集维度用法之二 事实维度(退化维度 Degenerate Dimension)
这篇文章是基于上一篇 SSAS 系列 - 多维数据集维度用法之一 引用维度 Referenced Dimension 继续讲解多维数据集维度用法中的事实维度。
事实维度,顾名思义就是把事实表 Fact*** 中的某一个或多个属性抽取出来形成一个维度,而不像以前直接通过维度表 Dim*** 来创建一个维度。
先来了解一下为什么不通过维度表来创建维度,而非要从一个事实表中抽取某个属性形成一个单独的维度,这是我们的疑问。
下面是从 FactResellerSales 表中抽取的一些记录,主要包括订单编号,订单明细,承运人跟踪号,采购订单号以及其它的一些信息。
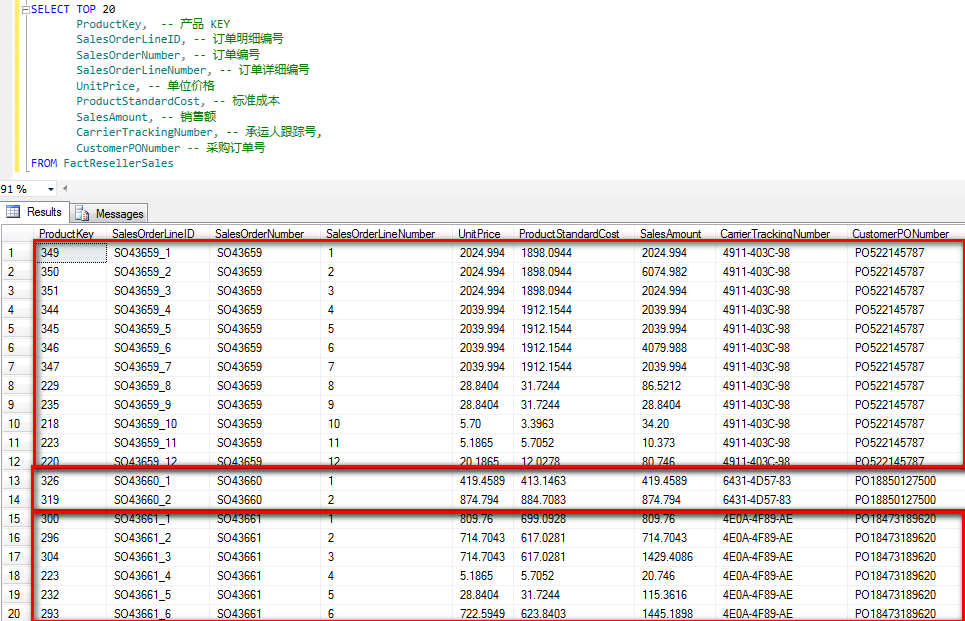
在实际业务系统中我们可能需要根据订单号去查看明细信息。
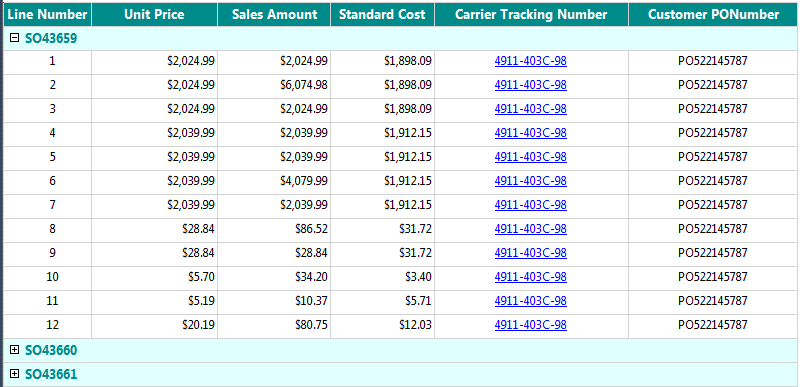
但是在分析系统中,我们往往会根据地域,销售部门,时间等各种角度来查看订单中的各种汇总记录,这些角度被称为维度。同样,也存在一种分析需求,用户可能也需要通过像 Carrier Tracking Number 承运人单号或者 Customer PO Number 采购订单号这两种角度来查看一下关于所有订单的产品总成本等聚合数据。那么问题就是 Carrier Tracking Number 和 Customer PO Number 都是属于事实表的属性,并不是传统意义上的维度表中的维度属性,所以没有办法通过它们来查看或者聚合类似于产品总成本等度量值。(当然也存在直接需求通过 Sales Order Number 本身来聚合和查看数据,在后面也会通过 Sales Order Number 去查看数据)
既然如此,肯定也会考虑到那为什么不讲 Carrier Tracking Number 或 Customer PO Number 单独抽取出来形成一个维度表,这样不就解决问题了吗?
我们可以从这么几个原因来考虑为什么不行?
第一,观察一下我们从数据库中查询出来的数据。会发现我们在事实表中的粒度应该是由 Sales Order Number 和 Sales Order Line Number 共同组成 SalesOrderLineID:SO43659_1,SO43659_2 这样的粒度来唯一标识每一行数据。虽然 Sales Order Number 并不是唯一的,但是可以想一想它在整个维度表占据的比例也是非常高的,那么这个基数会非常的大。同样在这个查询结果中,会发现 Carrier Tracking Number 和 Customer PO Number 与 Sales Order Number 完全是对等的,也就是说 Carrier Tracking Number 和 Customer PO Number 在事实表中占据的基数和比例也非常的大。 当某一列数据在整个事实信息中占据的比例非常大的时候,我们已经可以认定这样的数据列是不适合用于分组的。如果还是需要考虑将这两列数据放到维度表中,可以想象我们将需要复制大量的数据到维度表中,并且每次当事实表数据新增时,新增到维度表的维度记录也将会是非常多的。对比一下产品维度,地理纬度,维度中的数据量较之事实表非常少,同时改动也非常少。
第二,分析服务仅仅允许从一个维度或者一个事实也就是度量值组中钻取到数据。假设需要钻取事实表数据,那么需要显示的事实数据信息必须包含在一个维度中。也就是说当使用其它维度钻取这些事实数据的时候,将看不到 Carrier Tracking Number 和 Customer PO Number 这样的事实属性信息,因为它们已经从事实表中抽取到一个新的维度表了(假设这个动作我们已经操作了)。
所以从上面两点设计上的考虑,这两个列不适合单独抽取出来形成一个新的维度表,而只能在事实表基础之上将它们变成一个事实维度。那么当一个事实表属性从一个表示事实的角度慢慢退化成表示维度属性,我们就说这些属性退化了,于是就形成了退化维度。所以通常来讲,我们提到事实维度,指的就是退化维度,是事实表中的属性因为占据事实表基数大,但又需要从它们的角度去查看和分析聚合数据而造成的。
注意到,在 SSAS 多维数据集设计过程中,是没有任何的配置能够标识什么样的维度就是退化维度的。但是有一点我们可以确定,即如果维度的数据是来源于事实表,那么这个新创建的维度就是退化维度,即事实维度。
在上一篇的例子之上继续创建事实维度,新建一个维度。并且这个维度选择的事实表,那么这个从事实表创建出去的维度就是事实维度,即退化维度。当然我们有时把这个事实表本身叫做事实维度,其实本质上没有什么区别,因为维度属性列确实是从事实表中定义的。
我们假设需要从 Sales Order Number, Carrier Tracking Number 和 Customer PO Number 这几个"角度" 来看数据。
Key Columns 是事实表的主键列由 SalesOrderLineNumber 和 SalesOrderNumber 共同组成, NameColumn 由 SalesOrderLineID 表示。
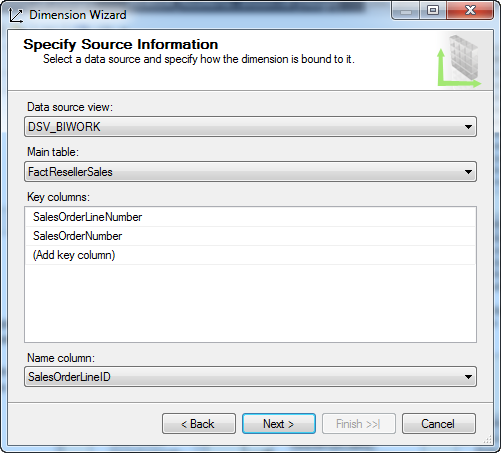
由于本身是事实表因此会关联很多维度表,这里不选择任何维度表。
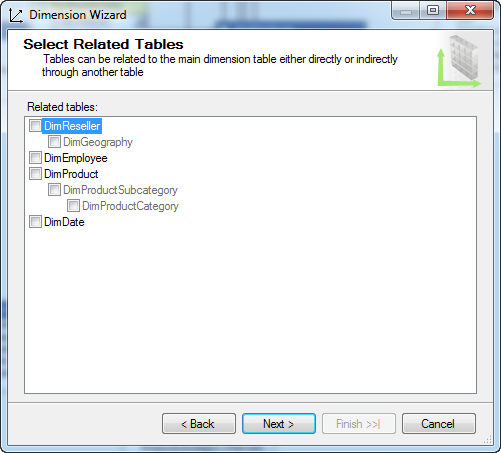
选择维度属性 - Carrier Tracking Number 和 Customer PO Number
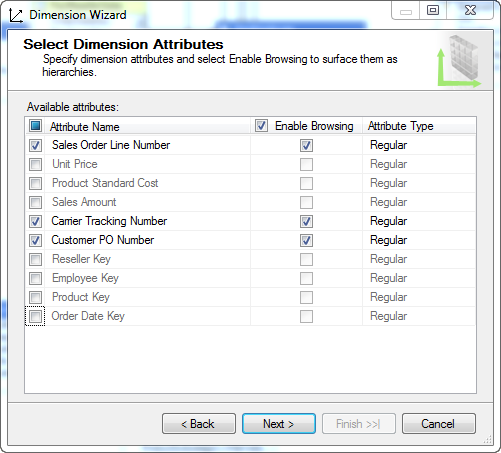
命名为 ResellerOrder
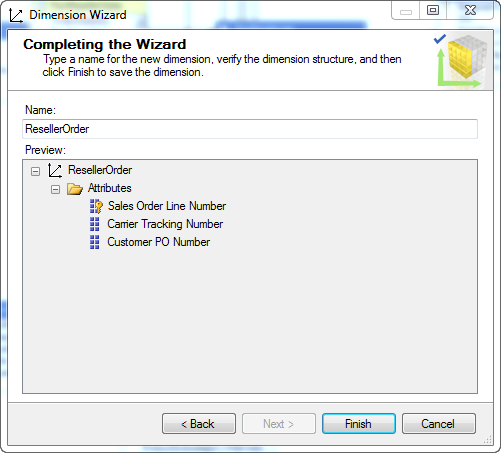
由于 Sales Order Number 和 Sales Order Line Number 作为 KEY 存在于事实维度中,因此需要重新将 Sales Order Number 拖放过来作为一个普通的维度属性。
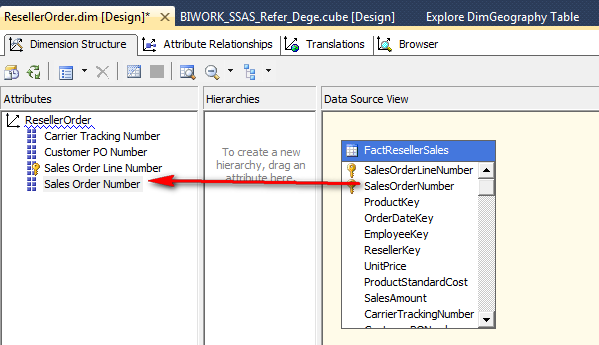
部署并修改 Cube, 在 Cube 中添加这个事实维度。
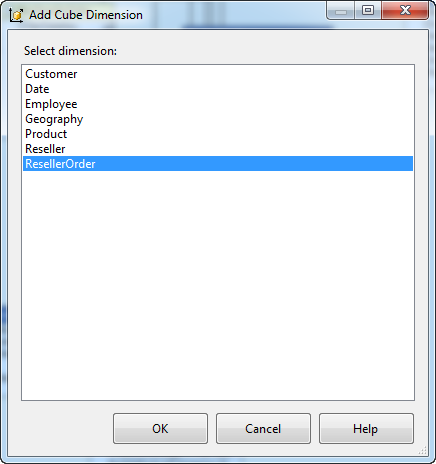
添加完成后查看维度用户 - Dimension Usage ,可以看到 ResellerOrder 事实维度与 Fact Reseller Sales 度量值组通过 Sales Order Line Number 建立了关联。
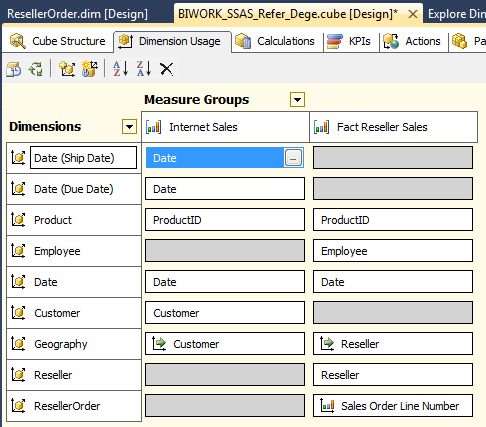
通过点击编辑 Sales Order Line Number 关联关系可以看到 Dimension Table 和 Measure Group Table 都是事实表 FactResellerSales,而维度用法中的关系也指明了是属于 Fact 事实类型。关联的粒度 Granularity Attribute 即事实表的粒度 - Sales Order Number 和 Sales Order Line Number 构成的订单明细 ID。
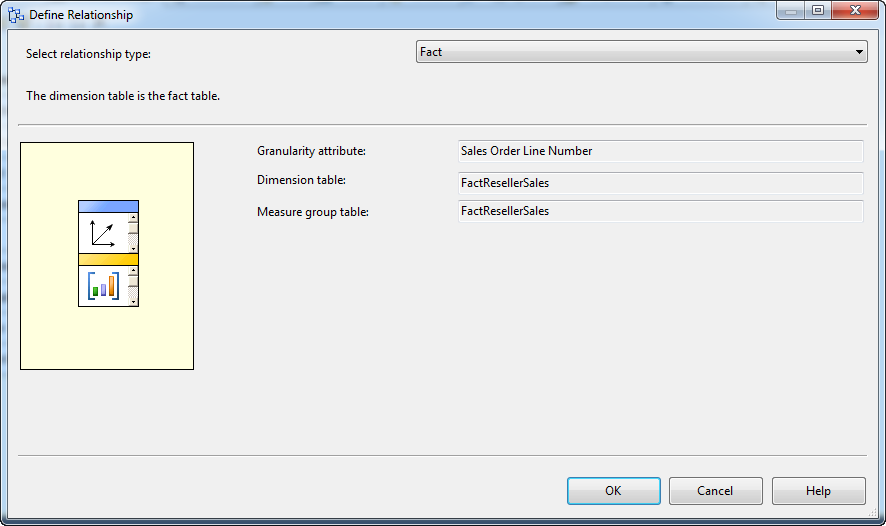
部署并通过 Tracking Number 查看数据 -
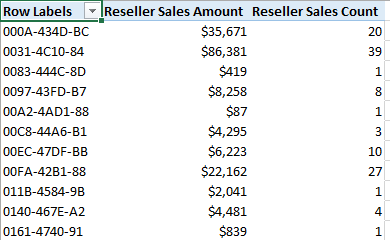
那么之前我们也解释过,对于事实维度或者叫退化维度,它的成员数量在事实表中占据的比例应该是非常大的,甚至是与事实表主键一对一并完全可以代替主键。因此基于这些属性创建的事实维度,维度成员也是非常庞大的。那么在实际浏览数据的时候,通常应该先选择好必要的过滤条件,比如选择某些层次结构作为过滤,这样可以降低返回数据的数量来达到提高查询效率的目的。
更多 BI 文章请参看 BI 系列随笔列表 (SSIS, SSRS, SSAS, MDX, SQL Server) 如果觉得这篇文章看了对您有帮助,请帮助推荐,以方便他人在 BIWORK 博客推荐栏中快速看到这些文章。
微软BI 之SSAS 系列 - 多维数据集维度用法之二 事实维度(退化维度 Degenerate Dimension)的更多相关文章
- 微软BI 之SSAS 系列 - 多维数据集维度用法之三 多对多维度 Many to Many
开篇介绍 对于维度成员和事实数据直接的关系看到更多的可能还是一对一,一对多的关系.比方在事实维度(或退化维度)中一个订单和明细号组合而成的ID,对应的就是事实表中的一条数据,这就是一对一的关系.比方说 ...
- 微软BI 之SSAS 系列 - 多维数据集维度用法之一 引用维度 Referenced Dimension
在 CUBE 设计过程中有一个非常重要的点就是定义维度与度量值组关系,维度的创建一般在前,而度量值组一般来源于一个事实表.当维度和度量值组在 CUBE 中定义完成之后,下一个最重要的动作就是定义两者之 ...
- 微软BI 之SSAS 系列 - 多维数据集中度量值设计时的聚合函数 (累加性_半累加性和非累加性)
在 SSAS 系列 - 实现第一个 Cube 以及角色扮演维度,度量值格式化和计算成员的创建 中主要是通过已存在的维度和事实数据创建了一个多维数据集,并同时解释了 Role-Playing Dimen ...
- 微软BI 之SSAS 系列 - 在SQL Server 2012 中开发 Analysis Services Multidimensional Project
SQL Server 2012 中提供了开发 SSAS 项目的两种模型,一种是新增加的 Tabular Model 表格模型,另一种就是原始的 Multidimensional Model 多维模型. ...
- 微软BI 之SSAS 系列 - 实现Cube 以及角色扮演维度,度量值格式化和计算成员的创建
在熟悉完下面这三种维度的创建方式之后,就可以开始创建我们的第一个 Cube 了. SSAS 系列 - 自定义的日期维度设计 SSAS 系列 - 基于雪花模型的维度设计 SSAS系列 - 关于父子维度的 ...
- 微软BI 之SSAS 系列 - 在 SQL Server 2012 下查看 SSAS 分析服务的模型以及几个模型的简单介绍
在SSDT中部署一个 SSAS 项目到本地服务器上出现错误. You cannot deploy the model because the localhost deployment server i ...
- 微软BI 之SSAS 系列 - 自定义的日期维度设计
SSAS Date 维度基本上在所有的 Cube 设计过程中都存在,很难见到没有时间维度的 OLAP 数据库.但是根据不同的项目需求, Date 维度的设计可能不大相同,所以在设计时间维度的时候需要搞 ...
- 微软BI 之SSAS 系列 - 基于雪花模型的维度设计
基于雪花模型的维度以下面的 Product 产品与产品子类别,产品类别为例. DimProduct 表和 DimProductSubcategory 表有外键关系,而 DimProductSubcat ...
- 微软BI 之SSAS 系列 - 维度的优化,灌木丛属性关系,以及自然层次结构与非自然层次结构的概念
维度的优化 在 SSAS 开发设计过程中,维度的优化非常重要,因为它在 SSAS 分析服务性能调优的过程中往往能起到一个非常重要的作用. 一般来说,对于 Cube 的性能优化第一步可能考虑的就是查看维 ...
随机推荐
- JavaScript脚本的两种放置方式
JavaScript脚本的两种放置方式 1在body里用 script标签引用 2 直接写在<script></script>标签之中
- Chakra TypedArray代码实现笔记
ArrayBuffer.cpp阅读 对象继承关系 JavascriptArrayBuffer: ArrayBuffer: ArrayBufferBase: DynamicObject: Recycla ...
- 国内最火5款Java微服务开源项目
目录 1.pig 2.zheng 3.Cloud-Platform 4.SpringBlade 5.Guns 1.pig 开源地址:https://gitee.com/log4j/pig 基于Spri ...
- 多线程中实现ApplicationContextAware接口获取需要的bean,applicationContext.getBea未返回也未报错
唉,面试失败了有点难过. https://q.cnblogs.com/q/95168/#a_208239
- AOJ 2200 Mr. Rito Post Office (floyd+DP)
题意: 快递到了:你是某个岛国(ACM-ICPC Japan)上的一个苦逼程序员,你有一个当邮递员的好基友利腾桑遇到麻烦了:全岛有一些镇子通过水路和旱路相连,走水路必须要用船,在X处下船了船就停在X处 ...
- ES6精简要点
没想到ES7都出来了(虽然并不大),想到自己ES6还没学完 现在就补补吧,记录下重点部分 Let的用法 用来声明块级变量 f1();function f1() { let n = 5; if (tru ...
- Codeforces Round #319 (Div. 2) D - Invariance of Tree
Invariance of Tree 题目大意:给你一个有1-n组成的序列p,让你构造一棵树,如果节点a和b之间有一条边,则p[a]和p[b]之间也有一条边. 思路:没啥思路,看了题解菜爆. 我们可以 ...
- Color the ball HDU1556
这题整整debug了两个小时 不同组居然要初始化 本以为built函数里面已经初始化好了!!!!! 其他无需注意 #include<cstdio> #include<cstring ...
- Python 调试器之pdb
使用PDB的方式有两种: 1. 单步执行代码,通过命令 python -m pdb xxx.py 启动脚本,进入单步执行模式 pdb命令行: 1)进入命令行Debug模式,python -m pdb ...
- 使用tortoisegit简化命令
1. 如果希望git保存用户名和密码,后续操作都无需输入密码: git命令: git config --global credential.helper store 或者通过tortoisegit ...