kmeans聚类理论篇
前言
kmeans是最简单的聚类算法之一,但是运用十分广泛。最近在工作中也经常遇到这个算法。kmeans一般在数据分析前期使用,选取适当的k,将数据分类后,然后分类研究不同聚类下数据的特点。
本文记录学习kmeans算法相关的内容,包括算法原理,收敛性,效果评估聚,最后带上R语言的例子,作为备忘。
算法原理
kmeans的计算方法如下:
1 随机选取k个中心点
2 遍历所有数据,将每个数据划分到最近的中心点中
3 计算每个聚类的平均值,并作为新的中心点
4 重复2-3,直到这k个中线点不再变化(收敛了),或执行了足够多的迭代
时间复杂度:O(I*n*k*m)
空间复杂度:O(n*m)
其中m为每个元素字段个数,n为数据量,I为跌打个数。一般I,k,m均可认为是常量,所以时间和空间复杂度可以简化为O(n),即线性的。
算法收敛
从kmeans的算法可以发现,SSE其实是一个严格的坐标下降(Coordinate Decendet)过程。设目标函数SSE如下:
SSE(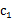 ,
,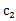 ,…,
,…,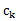 ) =
) = 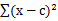
采用欧式距离作为变量之间的聚类函数。每次朝一个变量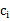 的方向找到最优解,也就是求偏倒数,然后等于0,可得
的方向找到最优解,也就是求偏倒数,然后等于0,可得
c_i=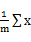 其中m是c_i所在的簇的元素的个数
其中m是c_i所在的簇的元素的个数
也就是当前聚类的均值就是当前方向的最优解(最小值),这与kmeans的每一次迭代过程一样。所以,这样保证SSE每一次迭代时,都会减小,最终使SSE收敛。
由于SSE是一个非凸函数(non-convex function),所以SSE不能保证找到全局最优解,只能确保局部最优解。但是可以重复执行几次kmeans,选取SSE最小的一次作为最终的聚类结果。
0-1规格化
由于数据之间量纲的不相同,不方便比较。举个例子,比如游戏用户的在线时长和活跃天数,前者单位是秒,数值一般都是几千,而后者单位是天,数值一般在个位或十位,如果用这两个变量来表征用户的活跃情况,显然活跃天数的作用基本上可以忽略。所以,需要将数据统一放到0~1的范围,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。具体计算方法如下:
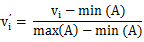
其中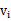 属于A。
属于A。
轮廓系数
轮廓系数(Silhouette Coefficient)结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类的效果。该值处于-1~1之间,值越大,表示聚类效果越好。具体计算方法如下:
- 对于第i个元素x_i,计算x_i与其同一个簇内的所有其他元素距离的平均值,记作a_i,用于量化簇内的凝聚度。
- 选取x_i外的一个簇b,计算x_i与b中所有点的平均距离,遍历所有其他簇,找到最近的这个平均距离,记作b_i,用于量化簇之间分离度。
- 对于元素x_i,轮廓系数s_i = (b_i – a_i)/max(a_i,b_i)
- 计算所有x的轮廓系数,求出平均值即为当前聚类的整体轮廓系数
从上面的公式,不难发现若s_i小于0,说明x_i与其簇内元素的平均距离小于最近的其他簇,表示聚类效果不好。如果a_i趋于0,或者b_i足够大,那么s_i趋近与1,说明聚类效果比较好。
K值选取
在实际应用中,由于Kmean一般作为数据预处理,或者用于辅助分类贴标签。所以k一般不会设置很大。可以通过枚举,令k从2到一个固定值如10,在每个k值上重复运行数次kmeans(避免局部最优解),并计算当前k的平均轮廓系数,最后选取轮廓系数最大的值对应的k作为最终的集群数目。
实际应用
下面通过例子(R实现,完整代码见附件)讲解kmeans使用方法,会将上面提到的内容全部串起来
library(fpc) # install.packages("fpc")
data(iris)
head(iris)
加载实验数据iris,这个数据在机器学习领域使用比较频繁,主要是通过画的几个部分的大小,对花的品种分类,实验中需要使用fpc库估计轮廓系数,如果没有可以通过install.packages安装。
# 0-1 正规化数据
min.max.norm <- function(x){
(x-min(x))/(max(x)-min(x))
}
raw.data <- iris[,1:4]
norm.data <- data.frame(sl = min.max.norm(raw.data[,1]),
sw = min.max.norm(raw.data[,2]),
pl = min.max.norm(raw.data[,3]),
pw = min.max.norm(raw.data[,4]))
对iris的4个feature做数据正规化,每个feature均是花的某个不为的尺寸。
# k取2到8,评估K
K <- 2:8
round <- 30 # 每次迭代30次,避免局部最优
rst <- sapply(K, function(i){
print(paste("K=",i))
mean(sapply(1:round,function(r){
print(paste("Round",r))
result <- kmeans(norm.data, i)
stats <- cluster.stats(dist(norm.data), result$cluster)
stats$avg.silwidth
}))
})
plot(K,rst,type='l',main='轮廓系数与K的关系', ylab='轮廓系数')
评估k,由于一般K不会太大,太大了也不易于理解,所以遍历K为2到8。由于kmeans具有一定随机性,并不是每次都收敛到全局最小,所以针对每一个k值,重复执行30次,取并计算轮廓系数,最终取平均作为最终评价标准,可以看到如下的示意图,
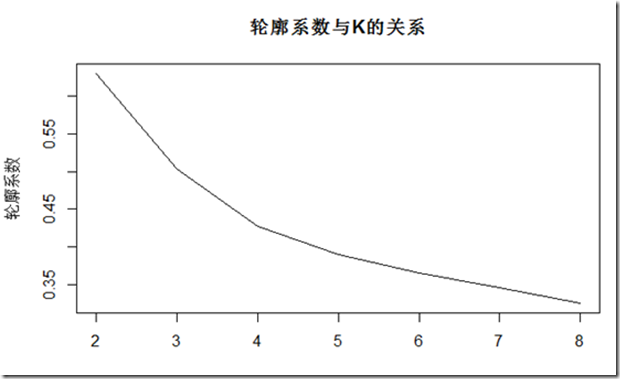
当k取2时,有最大的轮廓系数,虽然实际上有3个种类。
# 降纬度观察
old.par <- par(mfrow = c(1,2))
k = 2 # 根据上面的评估 k=2最优
clu <- kmeans(norm.data,k)
mds = cmdscale(dist(norm.data,method="euclidean"))
plot(mds, col=clu$cluster, main='kmeans聚类 k=2', pch = 19)
plot(mds, col=iris$Species, main='原始聚类', pch = 19)
par(old.par)
聚类完成后,有源原始数据是4纬,无法可视化,所以通过多维定标(Multidimensional scaling)将纬度将至2为,查看聚类效果,如下
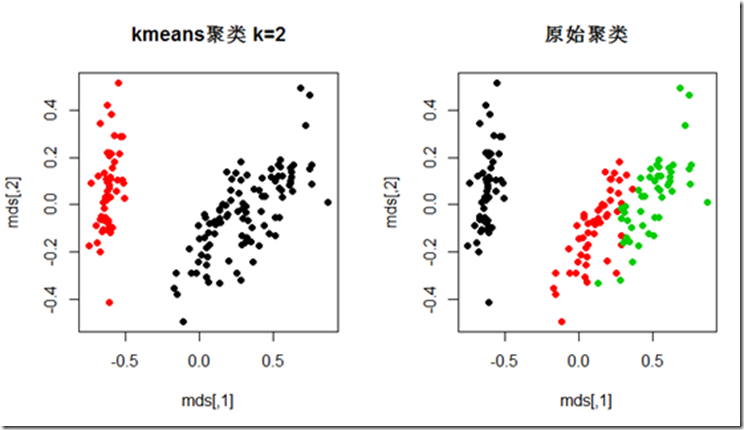
可以发现原始分类中和聚类中左边那一簇的效果还是拟合的很好的,右测原始数据就连在一起,kmeans无法很好的区分,需要寻求其他方法。
kmeans最佳实践
1. 随机选取训练数据中的k个点作为起始点
2. 当k值选定后,随机计算n次,取得到最小开销函数值的k作为最终聚类结果,避免随机引起的局部最优解
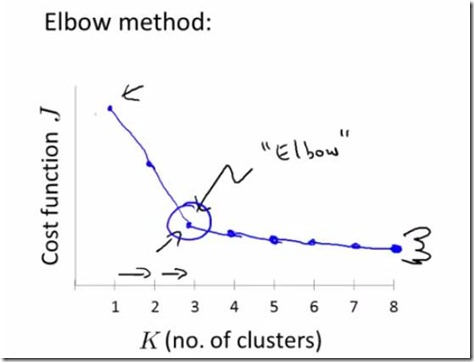
3. 手肘法选取k值:绘制出k--开销函数闪点图,看到有明显拐点(如下)的地方,设为k值,可以结合轮廓系数。
4. k值有时候需要根据应用场景选取,而不能完全的依据评估参数选取。
参考
[2] 坐标下降法(Coordinate Decendent)
[3] 数据规格化
[4] 维基百科--轮廓系数
[5] kmeans算法介绍
[6] 降为方法—多维定标
[7] Week 8 in Machine Learning, by Andrew NG, Coursera
kmeans聚类理论篇的更多相关文章
- 小白学数据分析--聚类分析理论之K-means理论篇
小白学数据分析--聚类分析理论之K-means理论篇 聚类分析是一类广泛被应用的分析方法,其算法众多,目前像SAS.Splus.SPSS.SPSS Modeler等分析工具均以支持聚类分析,但是如何使 ...
- 第十三篇:K-Means 聚类算法原理分析与代码实现
前言 在前面的文章中,涉及到的机器学习算法均为监督学习算法. 所谓监督学习,就是有训练过程的学习.再确切点,就是有 "分类标签集" 的学习. 现在开始,将进入到非监督学习领域.从经 ...
- 一步步教你轻松学支持向量机SVM算法之理论篇1
一步步教你轻松学支持向量机SVM算法之理论篇1 (白宁超 2018年10月22日10:03:35) 摘要:支持向量机即SVM(Support Vector Machine) ,是一种监督学习算法,属于 ...
- 一步步教你轻松学K-means聚类算法
一步步教你轻松学K-means聚类算法(白宁超 2018年9月13日09:10:33) 导读:k-均值算法(英文:k-means clustering),属于比较常用的算法之一,文本首先介绍聚类的理 ...
- k-means+python︱scikit-learn中的KMeans聚类实现( + MiniBatchKMeans)
来源:, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, ...
- Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解
Hadoop平台K-Means聚类算法分布式实现+MapReduce通俗讲解 在Hadoop分布式环境下实现K-Means聚类算法的伪代码如下: 输入:参数0--存储样本数据的文本文件inpu ...
- OpenCV计算机视觉学习(12)——图像量化处理&图像采样处理(K-Means聚类量化,局部马赛克处理)
如果需要处理的原图及代码,请移步小编的GitHub地址 传送门:请点击我 如果点击有误:https://github.com/LeBron-Jian/ComputerVisionPractice 准备 ...
- K-Means 聚类算法
K-Means 概念定义: K-Means 是一种基于距离的排他的聚类划分方法. 上面的 K-Means 描述中包含了几个概念: 聚类(Clustering):K-Means 是一种聚类分析(Clus ...
- 用scikit-learn学习K-Means聚类
在K-Means聚类算法原理中,我们对K-Means的原理做了总结,本文我们就来讨论用scikit-learn来学习K-Means聚类.重点讲述如何选择合适的k值. 1. K-Means类概述 在sc ...
随机推荐
- mac 苹果多版本jdk自由切换
场景 手头上的工具有时候依赖低版本jdk,有时候需要高版本jdk, 如何在不同版本jdk之间来回自由的切换? 安装 首选需要去官网下载dmg安装包,地址:https://www.oracle.com/ ...
- Android 7.0 fiddler代理抓不到https请求的解决办法
解决方法: 1.在源码res目录下新建xml目录,增加network_security_config.xml文件 (工程名/app/src/main/res/xml/network_security ...
- 原型模式ProtoType
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2019/3/4 21:49 # @Author : ChenAdong # @emai ...
- LeetCode题解之Clone Graph
1.题目描述 2.问题分析 要遍历图,然后标记没有被复制的节点. 3.代码 class Solution { private: unordered_map<Node*, Node*> m; ...
- java----JSTL学习笔记(转)
Java容器类包含List.ArrayList.Vector及map.HashTable.HashMap.Hashset ArrayList和HashMap是异步的,Vector和HashTable是 ...
- Elasticsearch-精确查找
转译:(https://www.elastic.co/guide/en/elasticsearch/guide/current/_finding_exact_values.html#_finding_ ...
- Django基础笔记
1.准备工作 .虚拟环境设置 python3 pip install virtualenv python -m venv env(虚拟环境文件名) env\Scripts\activate pip i ...
- Microsoft.AspNet.Identity 重置密码
重置密码:先生成重置密码的Token,然后调用ResetPassword方法重置密码,密码要符合规则.. ApplicationUserManager UserManager => _userM ...
- c/c++ 智能指针 unique_ptr 使用
智能指针 unique_ptr 使用 和shared_ptr不同,可以有多个shared_ptr指向同一个内存,只能有1个unique_ptr指向某个内存.因此unique_ptr不支持普通的拷贝和赋 ...
- c/c++ 通用的(泛型)算法 generic algorithm 总览
通用的(泛型)算法 generic algorithm 总览 特性: 1,标准库的顺序容器定义了很少的操作,比如添加,删除等. 2,问题:其实还有很多操作,比如排序,查找特定的元素,替换或删除一个特定 ...