Scrapy项目创建以及目录详情
Scrapy项目创建已经目录详情
一、新建项目(scrapy startproject)
- 在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
PS C:\scrapy> scrapy startproject sp1
You can start your first spider with:
cd sp1
scrapy genspider example example.com
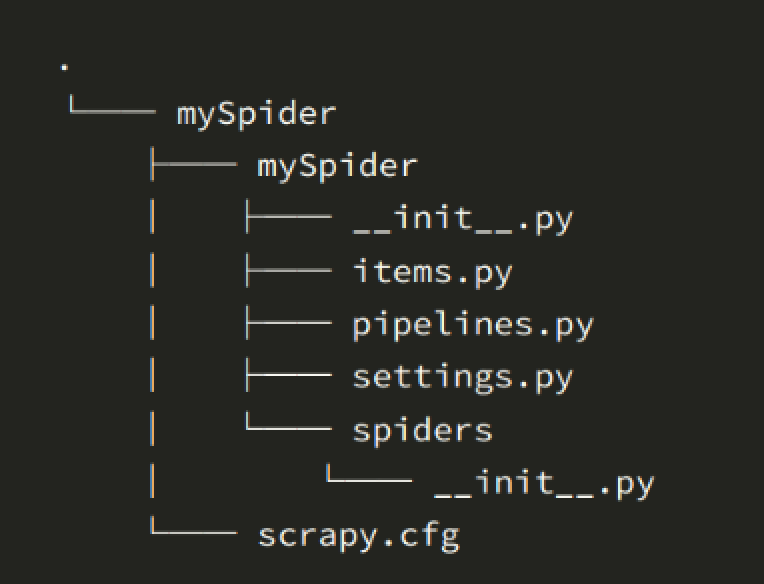
- scrapy.cfg # 项目的配置文件
- sp1/ # 项目的Python模块,将会从这里引用代码
- sp1/items.py # 项目的目标文件
- sp1/pipelines.py # 项目的管道文件用于文件持久化
- sp1/settings.py # 项目的设置文件
- sp1/middlewares.py # 中间件
- sp1/spiders/ # 存储爬虫代码目录
settings.py内容详情
settings.py
# 项目名
BOT_NAME = 'sp1'
# 爬虫所在的位置
SPIDER_MODULES = ['sp1.spiders']
NEWSPIDER_MODULE = 'sp1.spiders'
# 爬虫是否遵循 robots 协议
ROBOTSTXT_OBEY = False
# 爬虫的并发量 默认 16 个
# CONCURRENT_REQUESTS = 32
# 下载延时 3 s
#DOWNLOAD_DELAY = 3
# 是否禁用cookies 默认不禁用
#COOKIES_ENABLED = False # 表示为禁用
# 请求包头
DEFAULT_REQUEST_HEADERS = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 语言可以关闭,按照服务器返回值为准
# 'Accept-Language': 'en',
}
# 下载中间件,值越小优先级越高
DOWNLOADER_MIDDLEWARES = {
'sp1.middlewares.Sp1DownloaderMiddleware': 543,
}
# 下载后的数据如何处理,存储过程
ITEM_PIPELINES = {
'sp1.pipelines.FilePipeline': 300,
}
创建一个爬虫文件
在当前目录下输入命令,将在sp1/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
PS C:\scrapy> cd sp1
# scrapy genspider关键字 chouti 爬虫名 chouti.com 一般指定站点域名
PS C:\scrapy\sp1> scrapy genspider chouti chouti.com
Created spider 'chouti' using template 'basic' in module:
sp1.spiders.chouti
通过pycharm调试scrapy项目
1.使用pycharm打开项目
2.在项目等级目录创建main.py
from scrapy.cmdline import execute
import sys
import os
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
print(BASE_DIR)
execute(["scrapy","crawl","chouti"])
Scrapy项目创建以及目录详情的更多相关文章
- Python Scrapy项目创建(基础普及篇)
在使用Scrapy开发爬虫时,通常需要创建一个Scrapy项目.通过如下命令即可创建 Scrapy 项目: scrapy startproject ZhipinSpider 在上面命令中,scrapy ...
- IDEA中Java项目创建lib目录并生成依赖
首先介绍说明一下idea在创建普通的Java项目,是没有lib文件夹的,下面我来带大家来创建一下1.右键点击项目,创建一个普通的文件夹 2.取名为lib 3.把项目所需的jar包复制到lib文件夹下 ...
- 创建第一个Scrapy项目
d:进入D盘 scrapy startproject tutorial建立一个新的Scrapy项目 工程的目录结构: tutorial/ scrapy.cfg # 部署配置文件 tutorial/ # ...
- Scrapy项目结构分析和工作流程
新建的空Scrapy项目: spiders目录: 负责存放继承自scrapy的爬虫类.里面主要是用于分析response并提取返回的item或者是下一个URL信息,每个Spider负责处理特定的网站或 ...
- 【pycharm基本操作】项目创建、切换、运行、字体颜色设置,常见包的安装步骤
创建新项目 退出项目 怎样区别虚拟环境和系统环境? 虚拟环境和系统环境切换:进入项目切换解释器 切换项目 创建python目录和文件 代码运行方式一: 还可以这样执行代码方式二: 文件的剪切.复制.删 ...
- pycharm创建scrapy项目教程及遇到的坑
最近学习scrapy爬虫框架,在使用pycharm安装scrapy类库及创建scrapy项目时花费了好长的时间,遇到各种坑,根据网上的各种教程,花费了一晚上的时间,终于成功,其中也踩了一些坑,现在整理 ...
- eclipse创建scrapy项目
1. 您必须创建一个新的Scrapy项目. 进入您打算存储代码的目录中(比如否F:/demo),运行下列命令: scrapy startproject tutorial 2.在eclipse中创建一个 ...
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- Scrapy库安装和项目创建
Scrapy是一个流行的网络爬虫框架,从现在起将陆续记录Python3.6下Scrapy整个学习过程,方便后续补充和学习.本文主要介绍scrapy安装.项目创建和测试基本命令操作 scrapy库安装 ...
随机推荐
- P4126 [AHOI2009]最小割
题目地址:P4126 [AHOI2009]最小割 最小割的可行边与必须边 首先求最大流,那么最小割的可行边与必须边都必须是满流. 可行边:在残量网络中不存在 \(x\) 到 \(y\) 的路径(强连通 ...
- [转]Python中的eval()、exec()及其相关函数
Python中的eval().exec()及其相关函数 刚好前些天有人提到eval()与exec()这两个函数,所以就翻了下Python的文档.这里就来简单说一下这两个函数以及与它们相关的几个函数 ...
- vim块编辑删除、插入、替换【转】
删除列 1.光标定位到要操作的地方. 2.CTRL+v 进入“可视 块”模式,选取这一列操作多少行. 3.d 删除. 插入列 插入操作的话知识稍有区别.例如我们在每一行前都插入"() & ...
- requests库入门01-环境安装
最近在项目中写了一个接口自动化测试的脚本,想要写一些文章来一下,方便自己回头来温习,感兴趣的可以跟着看,先写关于requests库的一些基本操作,然后再写整个框架的搭建.使用的是Python3+req ...
- linux系统快捷键
tab 补全命令 两次tab 列出所有以字符前缀开头的命令 ctrl A 把光标移到命令行开头 ctrl E 把光标移到命令行结尾 ctrl C 强制终止当前的命令 ct ...
- Laravel 自定义分页、可以调整、显示数目
{{-- 增加输入框,跳转任意页码和显示任意条数 --}} <ul class="pagination pagination-sm"> <li> <s ...
- 【原创】大叔经验分享(30)CM开启kerberos
kerberos安装详见:https://www.cnblogs.com/barneywill/p/10394164.html 一 为CM创建用户 # kadmin.local -q "ad ...
- Json 文件中value的基本类型
在Json中,value的类型只能是以下几种: 1.字符串 2.数字 3.true 或者 false (注意,和字符串不同,没有双引号包裹) 4.null
- tcpdump详解
tcpdump -i eth1 'host 121.14.84.221 and greater 76' -Ap -v -s10000 抓取 eth1 和 121.14.84.221 上的所有长度大于7 ...
- Linux more和less
一.more命令 more功能类似 cat ,cat命令是整个文件的内容从上到下显示在屏幕上. more会以一页一页的显示方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示,按 ...