Scrapy项目创建以及目录详情
Scrapy项目创建已经目录详情
一、新建项目(scrapy startproject)
- 在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
PS C:\scrapy> scrapy startproject sp1
You can start your first spider with:
cd sp1
scrapy genspider example example.com
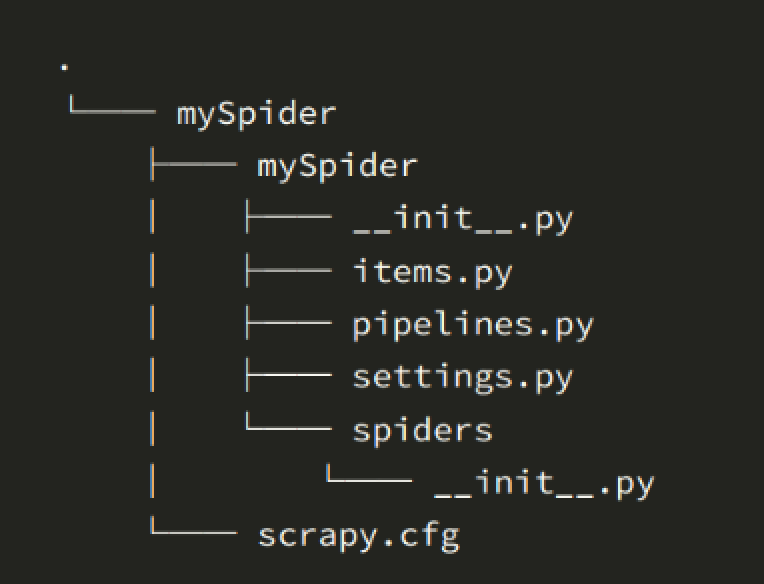
- scrapy.cfg # 项目的配置文件
- sp1/ # 项目的Python模块,将会从这里引用代码
- sp1/items.py # 项目的目标文件
- sp1/pipelines.py # 项目的管道文件用于文件持久化
- sp1/settings.py # 项目的设置文件
- sp1/middlewares.py # 中间件
- sp1/spiders/ # 存储爬虫代码目录
settings.py内容详情
settings.py
# 项目名
BOT_NAME = 'sp1'
# 爬虫所在的位置
SPIDER_MODULES = ['sp1.spiders']
NEWSPIDER_MODULE = 'sp1.spiders'
# 爬虫是否遵循 robots 协议
ROBOTSTXT_OBEY = False
# 爬虫的并发量 默认 16 个
# CONCURRENT_REQUESTS = 32
# 下载延时 3 s
#DOWNLOAD_DELAY = 3
# 是否禁用cookies 默认不禁用
#COOKIES_ENABLED = False # 表示为禁用
# 请求包头
DEFAULT_REQUEST_HEADERS = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 语言可以关闭,按照服务器返回值为准
# 'Accept-Language': 'en',
}
# 下载中间件,值越小优先级越高
DOWNLOADER_MIDDLEWARES = {
'sp1.middlewares.Sp1DownloaderMiddleware': 543,
}
# 下载后的数据如何处理,存储过程
ITEM_PIPELINES = {
'sp1.pipelines.FilePipeline': 300,
}
创建一个爬虫文件
在当前目录下输入命令,将在sp1/spider目录下创建一个名为itcast的爬虫,并指定爬取域的范围:
PS C:\scrapy> cd sp1
# scrapy genspider关键字 chouti 爬虫名 chouti.com 一般指定站点域名
PS C:\scrapy\sp1> scrapy genspider chouti chouti.com
Created spider 'chouti' using template 'basic' in module:
sp1.spiders.chouti
通过pycharm调试scrapy项目
1.使用pycharm打开项目
2.在项目等级目录创建main.py
from scrapy.cmdline import execute
import sys
import os
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
print(BASE_DIR)
execute(["scrapy","crawl","chouti"])
Scrapy项目创建以及目录详情的更多相关文章
- Python Scrapy项目创建(基础普及篇)
在使用Scrapy开发爬虫时,通常需要创建一个Scrapy项目.通过如下命令即可创建 Scrapy 项目: scrapy startproject ZhipinSpider 在上面命令中,scrapy ...
- IDEA中Java项目创建lib目录并生成依赖
首先介绍说明一下idea在创建普通的Java项目,是没有lib文件夹的,下面我来带大家来创建一下1.右键点击项目,创建一个普通的文件夹 2.取名为lib 3.把项目所需的jar包复制到lib文件夹下 ...
- 创建第一个Scrapy项目
d:进入D盘 scrapy startproject tutorial建立一个新的Scrapy项目 工程的目录结构: tutorial/ scrapy.cfg # 部署配置文件 tutorial/ # ...
- Scrapy项目结构分析和工作流程
新建的空Scrapy项目: spiders目录: 负责存放继承自scrapy的爬虫类.里面主要是用于分析response并提取返回的item或者是下一个URL信息,每个Spider负责处理特定的网站或 ...
- 【pycharm基本操作】项目创建、切换、运行、字体颜色设置,常见包的安装步骤
创建新项目 退出项目 怎样区别虚拟环境和系统环境? 虚拟环境和系统环境切换:进入项目切换解释器 切换项目 创建python目录和文件 代码运行方式一: 还可以这样执行代码方式二: 文件的剪切.复制.删 ...
- pycharm创建scrapy项目教程及遇到的坑
最近学习scrapy爬虫框架,在使用pycharm安装scrapy类库及创建scrapy项目时花费了好长的时间,遇到各种坑,根据网上的各种教程,花费了一晚上的时间,终于成功,其中也踩了一些坑,现在整理 ...
- eclipse创建scrapy项目
1. 您必须创建一个新的Scrapy项目. 进入您打算存储代码的目录中(比如否F:/demo),运行下列命令: scrapy startproject tutorial 2.在eclipse中创建一个 ...
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- Scrapy库安装和项目创建
Scrapy是一个流行的网络爬虫框架,从现在起将陆续记录Python3.6下Scrapy整个学习过程,方便后续补充和学习.本文主要介绍scrapy安装.项目创建和测试基本命令操作 scrapy库安装 ...
随机推荐
- macbook install mysql
安装Homebrew,详细步骤参见Homebrew官网. brew doctor确认brew在正常工作. brew update更新包. brew install mysql 安装mysql.log如 ...
- iris数据集(鸢尾花)
包含三个花的品种(Iris setosa(山鸢尾),Iris virginica(北美鸢尾),Iris versicolor(变色鸢尾)) 每个品种各50个样 每个样本四个特征参数(萼片长度和宽度.花 ...
- 基于ATT和CK™框架的开放式方法评估网络安全产品
场景 提供有关如何使用特定商业安全产品来检测已知对手行为的客观见解 提供有关安全产品和服务真实功能的透明度以检测已知的对手行为 推动安全供应商社区增强其检测已知对手行为的能力 地址 https://a ...
- 【转】PEP8 规范
[转]PEP8 规范 Python PEP8 编码规范中文版 原文链接:http://legacy.python.org/dev/peps/pep-0008/ item detail PEP 8 ...
- 【转】python操作excel表格(xlrd/xlwt)
[转]python操作excel表格(xlrd/xlwt) 最近遇到一个情景,就是定期生成并发送服务器使用情况报表,按照不同维度统计,涉及python对excel的操作,上网搜罗了一番,大多大同小异, ...
- 如何操控DevExpress的 SpreadSheet 控件 并与 XAF 结合应用
DevExpress的XAF 框架通常使用 GridControl 控件来操作数据库表中的数据,但导入导出.非结构化数据的管理可以使用SpreadSheet 控件. SpreadSheet 控件模拟微 ...
- 【转】Java的接口和抽象类
对于面向对象编程来说,抽象是它的一大特征.在Java中,可以通过两种形式来体现OOP的抽象:接口和抽象类.这两者有很多相似的地方,又有很多不同的地方. 一.抽象类 在了解抽象类之前,先来了解一下抽象方 ...
- 利用URLConnection http协议实现webservice接口功能(附HttpUtil.java)
URL的openConnection()方法将返回一个URLConnection对象,该对象表示应用程序和 URL 之间的通信链接.程序可以通过URLConnection实例向该URL发送请求.读取U ...
- Unity3D RTS游戏中帧同步实现
帧同步技术是早期RTS游戏常用的一种同步技术,本篇文章要给大家介绍的是RTX游戏中帧同步实现,帧同步是一种前后端数据同步的方式,一般应用于对实时性要求很高的网络游戏,想要了解更多帧同步的知识,继续往下 ...
- 函数-->指定函数--->默认函数--->动态函数--> 动态参数实现字符串格式化-->lambda表达式,简单函数的表示
#一个函数何以接受多个参数#无参数#show(): ---> 执行:show() #传入一个参数 def show(arg): print(arg) #执行 show(123) #传入两个参数 ...