HBase读写数据的详细流程及ROOT表/META表介绍
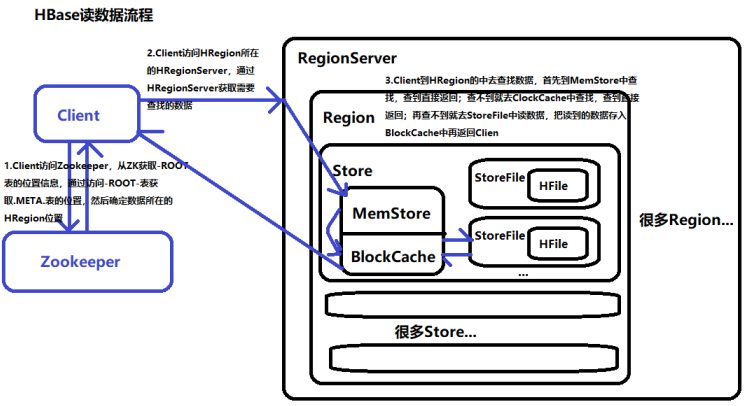
一、HBase读数据流程
1.Client访问Zookeeper,从ZK获取-ROOT-表的位置信息,通过访问-ROOT-表获取.META.表的位置,然后确定数据所在的HRegion位置;
2.Client访问HRegion所在的HRegionServer,通过HRegionServer获取需要查找的数据;
3.Client到HRegion的中去查找数据,首先到MemStore中查找,查到直接返回;查不到就去ClockCache中查找,查到直接返回;再查不到就去StoreFile中读数据,把读到的数据存入BlockCache中再返回Client。
如图:
二、HBase写数据流程
1.Client通过Zookeeper调度获取表的元数据信息;
2.Cilent通过rpc协议与RegionServer交互,通过-ROOT-表与.META.表找到对应的对应的Region;
3.将数据写入HLog日志中,如出现意外可以同通过HLog恢复信息;
4.将数据写入Region的MemStore中,当MemStore达到阈值开始溢写,将其中的数据Flush成一个StoreFile;
5.MemStore不断生成新的StoreFile,当StoreFile的数量到达阈值后会出发Compact合并操作,将多个StoreFile合并成一个StoreFile;
6.StoreFile文件会不断增大,当达到阈值后会出发Split操作,把当前的Region且分为两个新的Region。父Region会下线,两个子Region会被HMaster分配到相应的RegionServer。
图略、自己脑补一哈把~~
*********************************************************************************************
补充:1.由读写数据的流程可以发现,Region中的内存分为两块:MemStore(负责写数据)、BlockCache(负责读数据),这是HBase的一大特点——读写分离,这也是HBase读写速度极快的原因之一;
2.在HBase中,可以看出只有增添操作,所有的更新和删除都是在后续的Compact合并历程中进行的,这使得用户的写操作只有进入内存就可以立刻返回,实现了I/O的高性能。
*********************************************************************************************
三、-ROOT-表和.META.表的介绍
HBase用-ROOT-表记录.META.表的位置信息(即元数据信息),而.META.表记录了用户表Region的位置信息。
为了定位.META.表中各个Region的位置信息,把.META.表中所有Region的元数据保存在-ROOT-表中,最后由Zookeeper记录-Root-表的位置信息。
所以客户端Client要先访问ZK获取-ROOT-表的位置,然后访问-ROOT-表获取.META.表的位置,最后根据.META.表中的信息确定用户数据存放的位置。
HBase读写数据的详细流程及ROOT表/META表介绍的更多相关文章
- MapReduce从HBase读写数据简单示例
就用单词计数这个例子,需要统计的单词存在HBase中的word表,MapReduce执行的时候从word表读取数据,统计结束后将结果写入到HBase的stat表中. 1.在eclipse中建立一个ha ...
- 一条数据的HBase之旅,简明HBase入门教程-Write全流程
如果将上篇内容理解为一个冗长的"铺垫",那么,从本文开始,剧情才开始正式展开.本文基于提供的样例数据,介绍了写数据的接口,RowKey定义,数据在客户端的组装,数据路由,打包分发, ...
- 大数据学习路线分享-Hbase shell的基本操作完整流程
HBase的命令行工具,最简单的接口,适合HBase管理使用,可以使用shell命令来查询HBase中数据的详细情况.安装完HBase之后,启动hadoop集群(利用hdfs存储),启动zookeep ...
- HBase丢失数据的故障和原因分析
hbase的稳定性是近期社区的重要关注点,毕竟稳定的系统才能被推广开来,这里有几次稳定性故障和大家分享. 第一次生产故障的现象及原因 现象: 1 hbase发现无法写入 2 通过hbc ...
- HBase读写的几种方式(二)spark篇
1. HBase读写的方式概况 主要分为: 纯Java API读写HBase的方式: Spark读写HBase的方式: Flink读写HBase的方式: HBase通过Phoenix读写的方式: 第一 ...
- 【转帖】HBase读写的几种方式(二)spark篇
HBase读写的几种方式(二)spark篇 https://www.cnblogs.com/swordfall/p/10517177.html 分类: HBase undefined 1. HBase ...
- <HBase><读写><LSM>
Overview HBase中的一个big table,首先会按行划分成一些region(这些region之间是有序的,由startkey保证),每个region分配到不同的节点进行存储.因此,reg ...
- Hbase写数据,存数据,读数据的详细过程
Client写入 -> 存入MemStore,一直到MemStore满 -> Flush成一个StoreFile,直至增长到一定阈值 -> 出发Compact合并操作 -> 多 ...
- 大数据查询——HBase读写设计与实践
导语:本文介绍的项目主要解决 check 和 opinion2 张历史数据表(历史数据是指当业务发生过程中的完整中间流程和结果数据)的在线查询.原实现基于 Oracle 提供存储查询服务,随着数据量的 ...
随机推荐
- js——类型转换
总述 类型转换:显式.隐式(自动) 隐式转换是由编译器自动进行的,基本主要抽象操作有ToPrimitive, ToNumber, ToString, ToBoo ...
- 修改html中button显示的文字
1. <input type="button"> 实现密码输入框的可见和隐藏 直接修改value属性即可 <script type="text/jav ...
- SpringMvc + Jsp+ 富文本 kindeditor 进行 图片ftp上传nginx服务器 实现
一:html 原生态的附件上传 二:实现逻辑分析: 1.1.1 需求分析 Common.js 1.绑定事件 2.初始化参数 3.上传图片的url: /pic/upload 4.上图片参数名称: upl ...
- 【kafka】设置指定topic和group_id消耗的offset
该博文方法有问题,正确方案在http://www.cnblogs.com/dplearning/p/7992994.html 背景: 搭建了一个kafka集群,建立了topic test,用group ...
- cf1051d 简单的状态压缩dp
/* 给定一个二行n列的格子,在里面填黑白色,要求通过黑白色将格子分为k块 请问有多少种填色方式 dp[j][k][0,1,2,3] 填到第j列,有k块,第j列的颜色, */ #include< ...
- Spring声明式事务@Transactional 详解,事务隔离级别和传播行为
@Transactional注解支持9个属性的设置,这里只讲解其中使用较多的三个属性:readOnly.propagation.isolation.其中propagation属性用来枚举事务的传播行为 ...
- Django将默认的SQLite更换为MySQL
1.注释默认的SQLite3配置: blogproject/settings.py ''' DATABASES = { 'default': { 'ENGINE': 'django.db.backen ...
- 判断三次URL可用性脚本
#!/bin/bash check_url() { HTTP_CODE=$(curl -o /dev/ -s -) ];then continue fi } URL_LIST="www.ba ...
- python2.7 (x64) 调用 java 代码实践
背景:公司实施接口自动化测试,使用的框架python+unittest:因为开发使用的架构师SpringBoot,在测试过程中难免需要使用到python调用JAVA的一些接口,所以需要用到python ...
- bat 直接编译vs项目
直接项目.sln拖到bat上: @ECHO OFFset path=%~dp1%~nx1 C:\Windows\Microsoft.NET\Framework\v4.0.30319\MSBuild.e ...