运维告诉我CPU飙升300%,为什么我的程序上线就奔溃了
线上服务CPU飙升
前言
- 功能开发完成仅仅是项目周期中的第一步,一个完美的项目是在运行期体现的
- 今天我们就来看看笔者之前遇到的一个问题CPU飙升的问题。 代码层面从功能上看没有任何问题但是投入使用后却让我头大
问题描述
- 系统上点击数据录入功能在全局监控中会受到相关消息的通知。此时服务器CPU飙升300%
问题定位
- 首先我们先梳理下
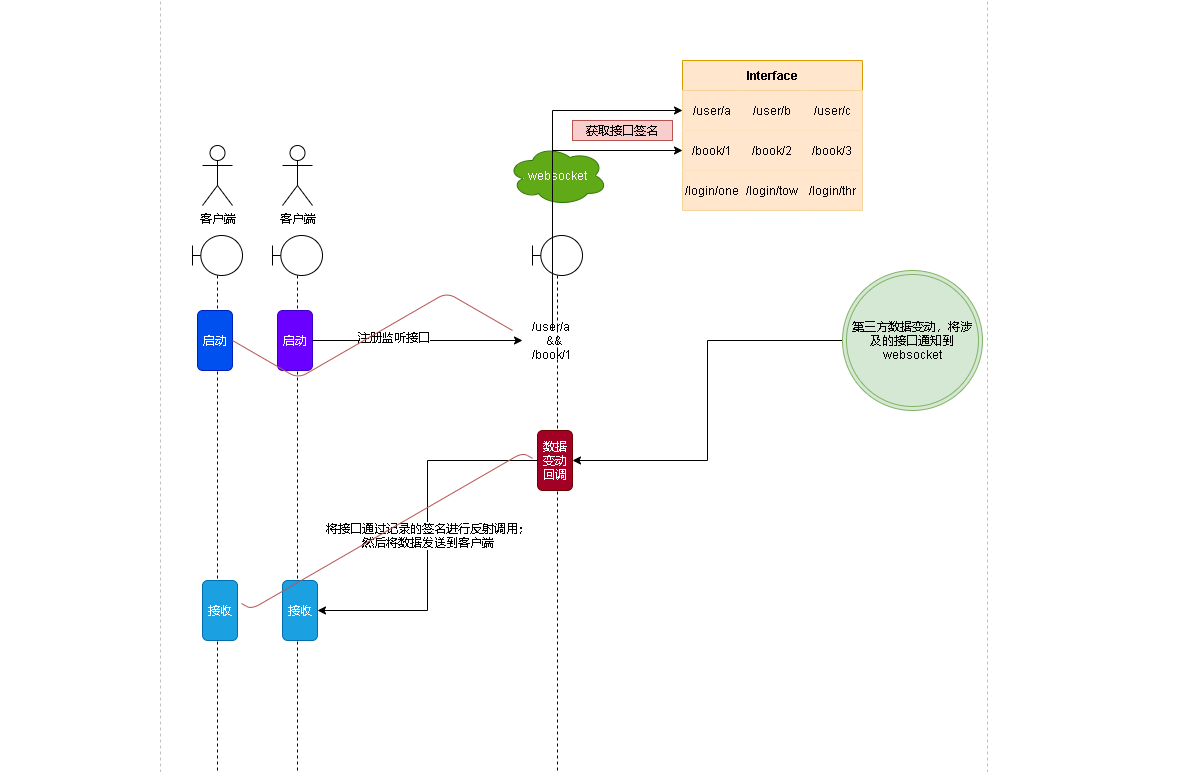
Websocket的数据发送的简单原理示意图。往往定位问题得清楚我们的逻辑是什么 - 当一个客户端启动时除了和
Websocket建立连接之外,我们还需要向Websocket服务注册当前客户端需要哪些接口的实时数据 - 我在代码内部是通过一个Map来存储这些接口签名信息的。然后客户注册时候将这些接口和客户端绑定在一起
- 当我们监听程序坚挺到数据变动就会对绑定到相关接口的客户端发送最新数据
业务定位
- 业务上很好定位,问题就是出现在我们的监听程序中。当监听到数据给
websocket客户端发送订阅的最新变动接口时就会出现CPU飙升。持续时间还很长,稍等一会就会降下来 - 这很明显是我们推送消息的时候出现了问题
隔离业务看本质
- 作为一个合格的程序员呢,必须摆脱业务才能有所收获 。业务是我们代码的外壳所有的问题基本上都是我们本质的问题。我们线上使用用户1W内。在这种的并发场景下应该是不会出问题的。现在出了问题肯定我们的程序逻辑有缺陷
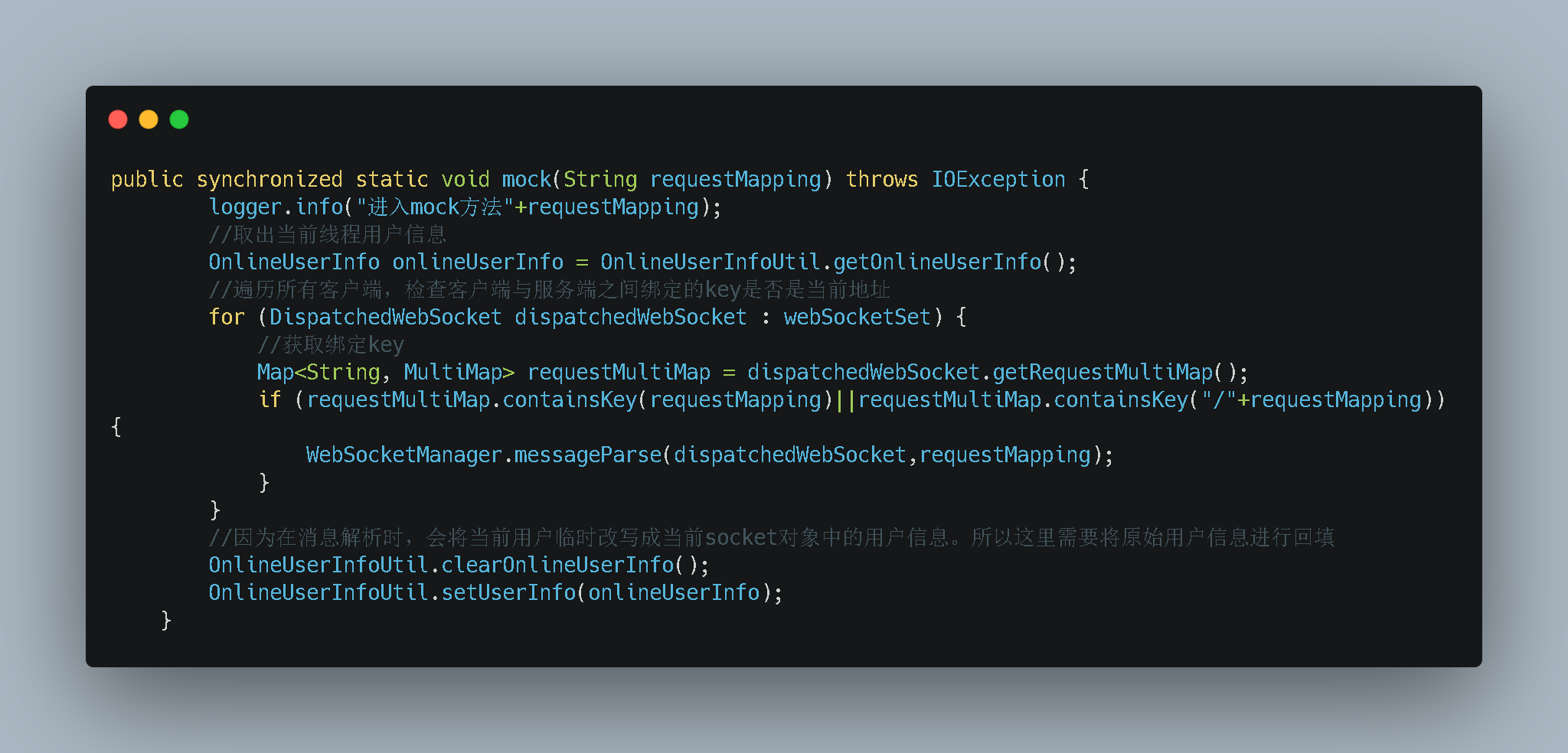
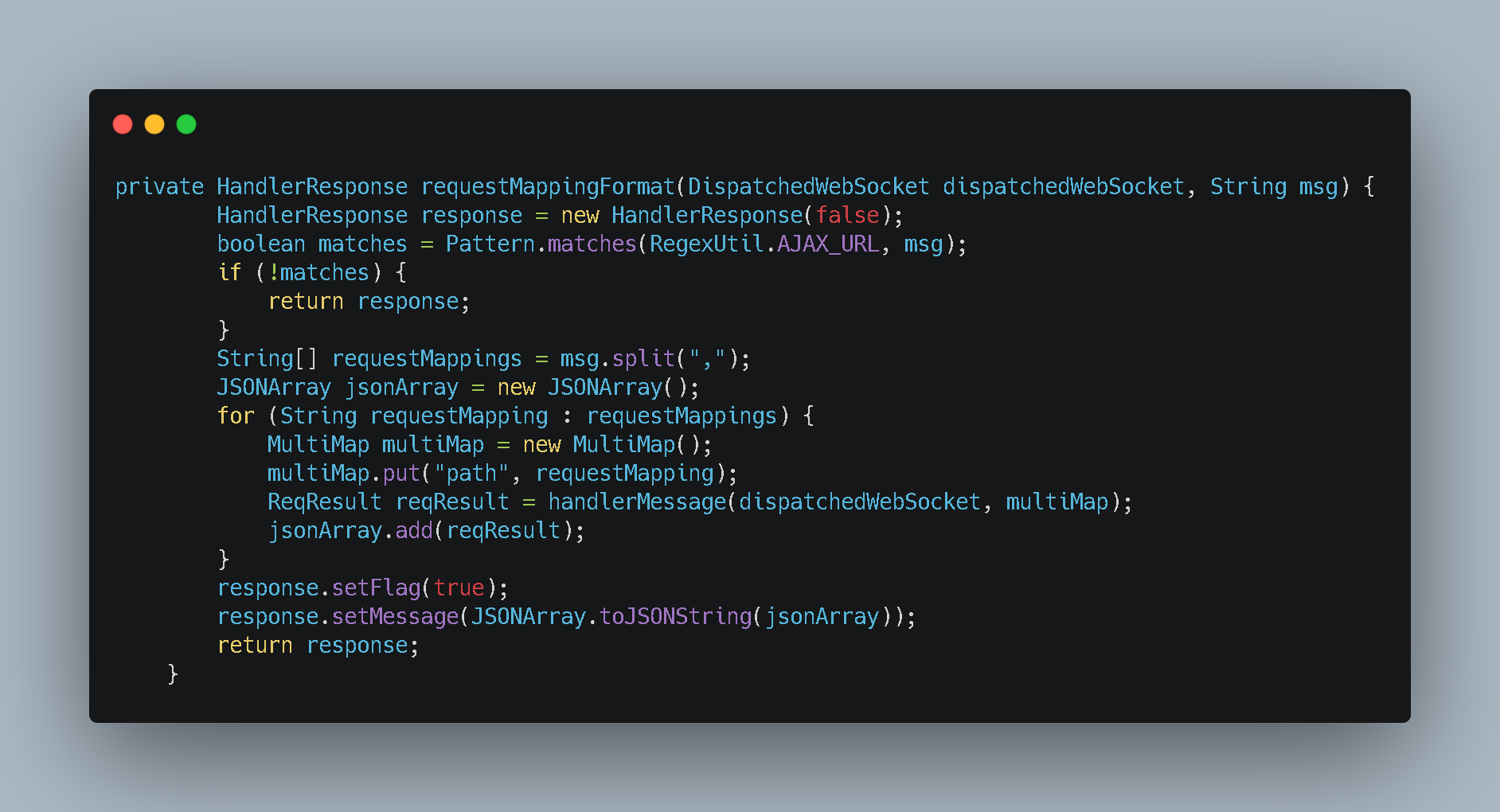
- 上面是我们的发送消息的代码。代码也很简单。先获取所有符合发送条件的客户端 。然后通过客户端内部提供的
sendMessage方法进行推送。 - 但是这个时候的
message是我们的接口信息。在内部会基于客户端保存的方法签名进行反射调用从而获取最新数据。在推送给客户端的 - 在上面的代码中核心的是
WebsocketManager.messageParse。这段是获取消息然后发送。里面获取消息是基于resultful格式解析的
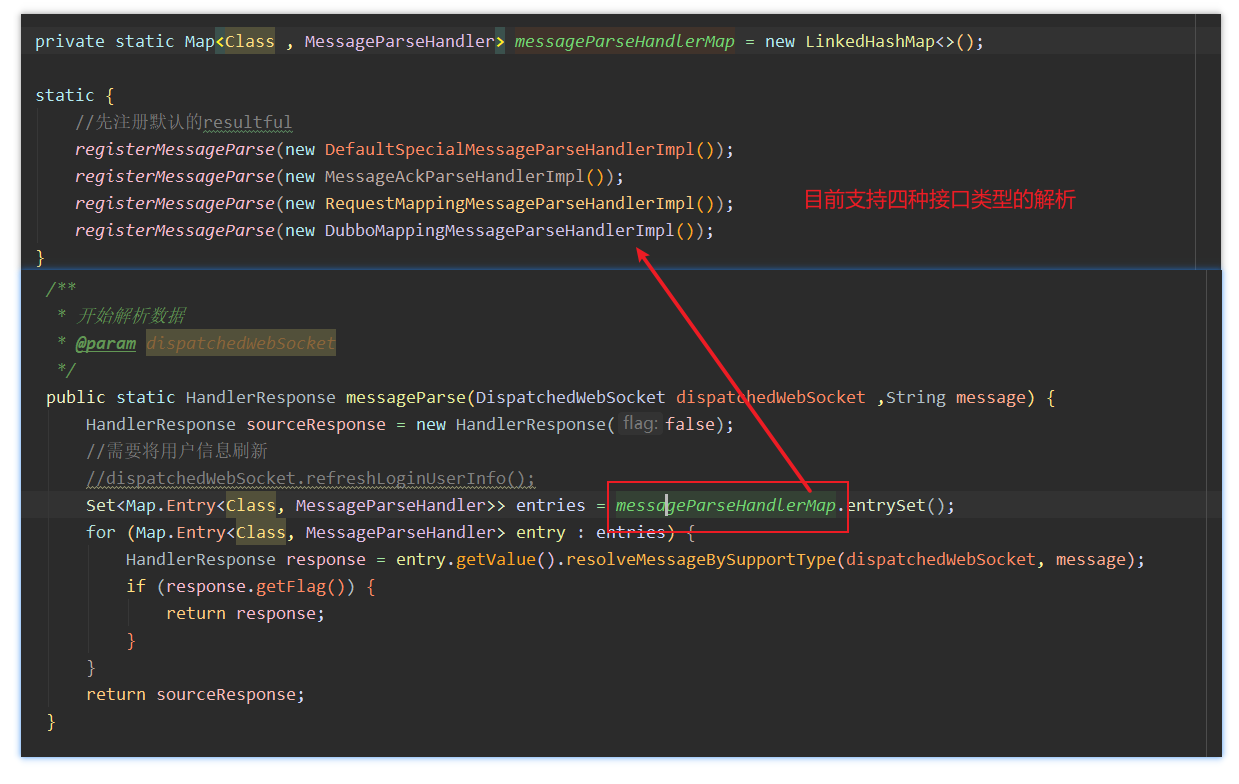
- 这个方法内部我们有内置了我们的四种解析方式。这里我们只需要关心
RequestMappingMessageParseHandlerImpl这个协议。
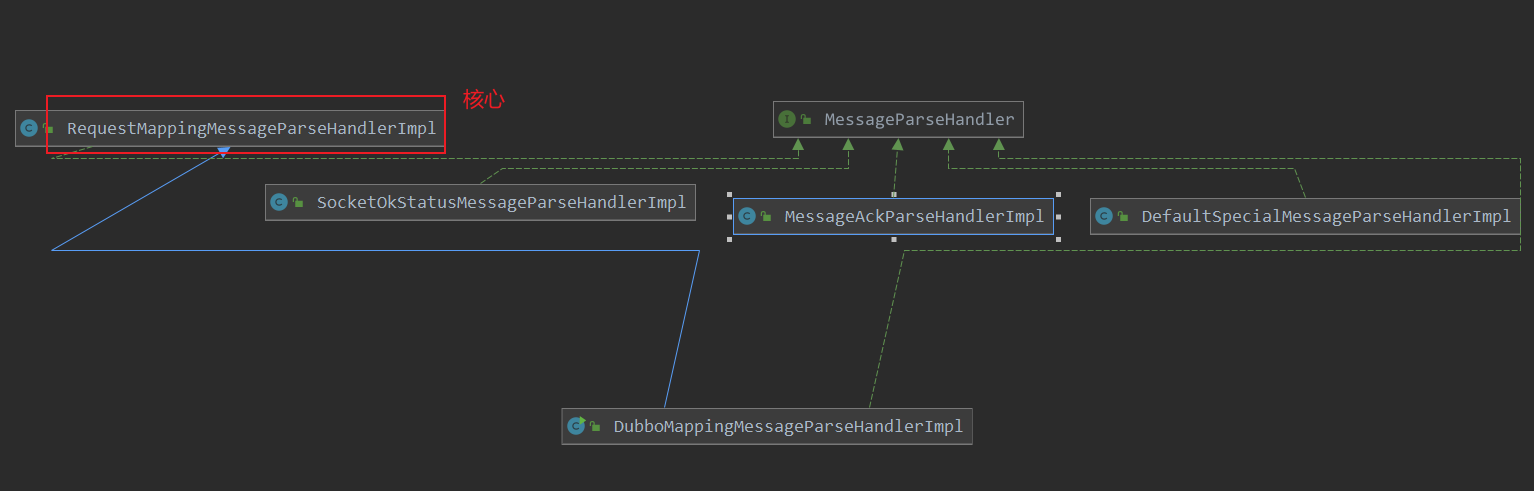
- 关于我们内部的协议这里也不需要太在意。这是我们自己的一个设计。根据上面的图示我们也能看的出来里面
RequestMappingMessageParseHandlerImpl是核心
产生原因
- 上面我们简单的梳理了下代码的逻辑。
- 仔细分析下我们是遍历所有客户端然后在反射调用接口数据进行返回的。实际上在消息推送时我们没必要在每个客户端内部调用数据。我们完全可以先调用数据然后在遍历客户端进行发送。
- 这也是导致CPU过高的问题。我们1W个用户同事在线的可能有5000+ 。 那么我们需要5000次以上的反射着肯定是吃不消的。这也是为什么本文开头说功能正常不代表业务正常。
解决方案
- 这就是量变引起质变。在多客户的情况下我们的设计弊端就暴露出来。这里也是笔者自己给自己挖坑。既然找到问题我们就好解决了。下面我们对代码做了一下改动
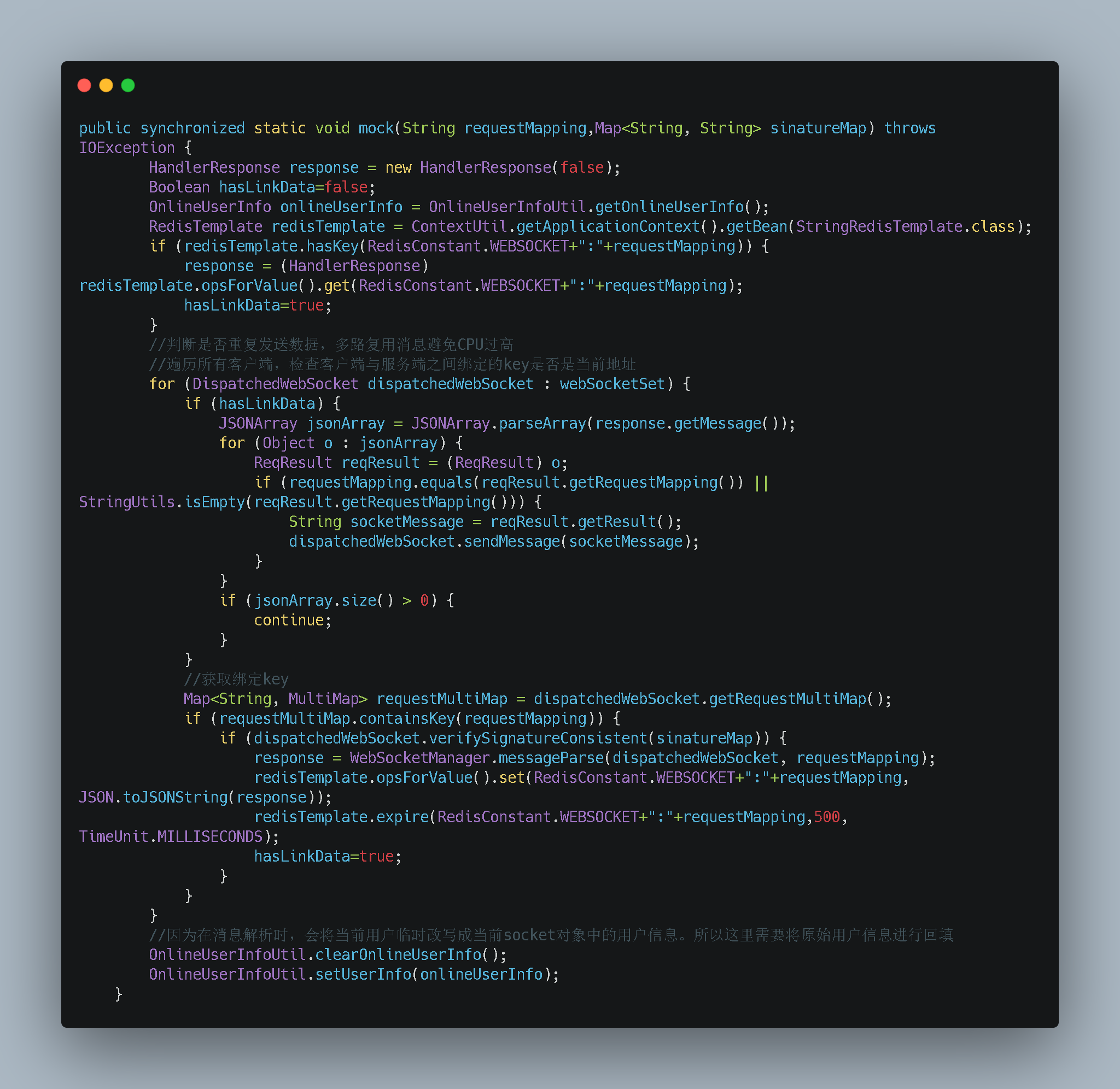
我将数据缓存起来。因为在同一批次推送时本来也应该保证数据一致性。而且我们系统对数据实时性也是可以接受一定时间延迟的。我在这里又加上缓存这样就解决了我们循环的问题
经过测试本次改动在CPU上大概优化了100倍。
总结
- 功能开发完成仅仅代表功能的实验没有问题
- 单用户和多用户完全是两种不同的用户形态。我们功能设计初期就应该尽量考虑数据量的问题
- 唯一做的好的地方是我通过责任链模式将数据解析隔离出来。否则这样的问题定位将会更加麻烦
运维告诉我CPU飙升300%,为什么我的程序上线就奔溃了的更多相关文章
- Linux系统运维常见面试简答题(36题)
1.请描述下linux 系统的开机启动过程开机加电BIOS自检———–>MBR引导———–>grub引导菜单———–>加载内核———–>启动init进程———–>读取in ...
- 【实战小项目】python开发自动化运维工具--批量操作主机
有很多开源自动化运维工具都很好用如ansible/salt stack等,完全不用重复造轮子.只不过,很多运维同学学习Python之后,苦于没小项目训练.本篇就演示用Python写一个批量操作主机的工 ...
- Linux运维三:系统目录结构
Linux系统目录结构官方参考:http://www.pathname.com/fhs/ 1:Linux树状目录结构图 下面目录中标红的是必须要掌握的! 2:根目录 目录 描述 / 第一层次结构的根 ...
- 自动化运维利器Ansible要点汇总
由于大部分互联网公司服务器环境复杂,线上线下环境.测试正式环境.分区环境.客户项目环境等造成每个应用都要重新部署,而且服务器数量少则几十台,多则千台,若手工一台台部署效率低下,且容易出错,不利后期运维 ...
- sql server 运维时CPU,内存,操作系统等信息查询(用sql语句)
我们只要用到数据库,一般会遇到数据库运维方面的事情,需要我们寻找原因,有很多是关乎处理器(CPU).内存(Memory).磁盘(Disk)以及操作系统的,这时我们就需要查询他们的一些设置和内容,下面讲 ...
- 运维笔记--postgresql占用CPU问题定位
运维笔记--postgresql占用CPU问题定位 场景描述: 业务系统访问变慢,登陆服务器查看系统负载并不高,然后查看占用CPU较高的进程,发现是连接数据库的几个进程占用系统资源较多. 处理方式: ...
- Linux运维入门到高级全套常用要点
Linux运维入门到高级全套常用要点 目 录 1. Linux 入门篇................................................................. ...
- Linux云计算运维-MySQL
0.建初心 优秀DBA的素质 1.人品,不做某些事情2.严谨,运行命令前深思熟虑,三思而后行,即使是依据select3.细心,严格按照步骤一步一步执行,减少出错4.心态,遇到灾难,首先要稳住,不慌张, ...
- saltstack高效运维
saltstack高效运维 salt介绍 saltstack是由thomas Hatch于2011年创建的一个开源项目,设计初衷是为了实现一个快速的远程执行系统. salt强大吗 系统管理员日常会 ...
随机推荐
- TIOBE 编程语言排行榜
https://www.tiobe.com/tiobe-index/ TIOBE 编程语言排行榜是编程语言流行趋势的一个指标
- Min25筛求1-n内的素数和
1 //#include <bits/stdc++.h> 2 #include<cstdio> 3 #include<cstring> 4 #include< ...
- 攻防世界 reverse Guess-the-Number
Guess-the-Number su-ctf-quals-2014 使用jd-gui 反编译jar import java.math.BigInteger; public class guess ...
- Android学习之Layoutinflater的用法
•她的第一次 话说,那是一个风雪交加的夜晚,看着她独自一个人走在漆黑的小道上,我抓紧跟了过去: 那晚,我们...... 记得第一次接触这个 Layoutinflater 应该是在学习 ListView ...
- 前端使用bcrypt对密码加密,服务器对密码进行校验
以前为了防止前端密码安全问题,都是对密码进行md5(password + salt). 有些也会用别的加密方式,但还是会存在撞库,彩虹表等破解常规密码. 因此使用bcrypt加密是一个不错的选择,因为 ...
- linux日志文件说明
/var/log/message 系统启动后的信息和错误日志,是Red Hat Linux中最常用的日志之一 /var/log/secure 与安全相关的日志信息 /var/log/maillog 与 ...
- 复制文件--cp
cp file1 file2 将文件拷贝到指定路径下 cp -r dir1 dir2 将文件夹拷贝到指定路径下
- 带你全面认识CMMI V2.0(二)
CMMI V2.0成熟度等级 CMMI V2.0的一大变化是,所有实践领域均适用于成熟度三级(ML3),并具有特定的附加必需实践水平. 例如,在ML3上需要进行因果分析和解决,但在CMMI成熟度四级( ...
- SpringBoot(九篇)
(一) SpringBootCLI安装 (二)SpringBoot开发第一个应用 (三)SpringBoot pom.xml配置文件详解 (四)SpringBoot起步依赖Starters详解 (五) ...
- kali 2019-4中文乱码解决方法
1.更换阿里源 编辑源,apt-get update && apt-get upgrade && apt-get clean ,更新好源和更新软件 #阿里云deb ht ...