后缀树的建立-Ukkonen算法
Ukkonen算法,以字符串abcabxabcd为例,先介绍一下运算过程,最后讨论一些我自己的理解。
需要维护以下三个变量:
- 当前扫描位置
# - 三元组
活动节点(AN),活动边(AE),活动长度(AL) - 剩余后缀数:表示还有多少个潜在后缀应该被插入还没有插入
每多扫描一个后缀,其实是增加了一个新的后缀,从#=0-2的过程可以看出。
举个例子:
ab的后缀有ab和b,可以表示成[0,],[1,]abc的后缀有abc,bc和c,可以表示成[0,],[1,]和[2,]
增加了c之后,前两个后缀事实上可以使用相同的表示法,这样只有一个新的c后缀需要被增加
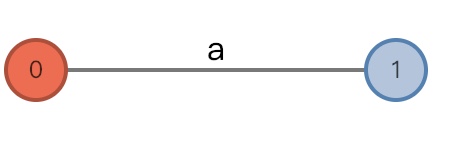
#=0, char='a'
- 增加前:
(root, "", 0), remainder = 1 - 为根节点增加一条边:
[0,],由于确实增加了条边,所以remainder会减少 - 增加后:
(root, "", 0), remainder = 0
#=1, char='b'
- 增加前:
(root, "", 0), remainder = 1 - 为根节点增加一条边:
[1,],由于确实增加了条边,所以remainder会减少 - 增加后:
(root, "", 0), remainder = 0
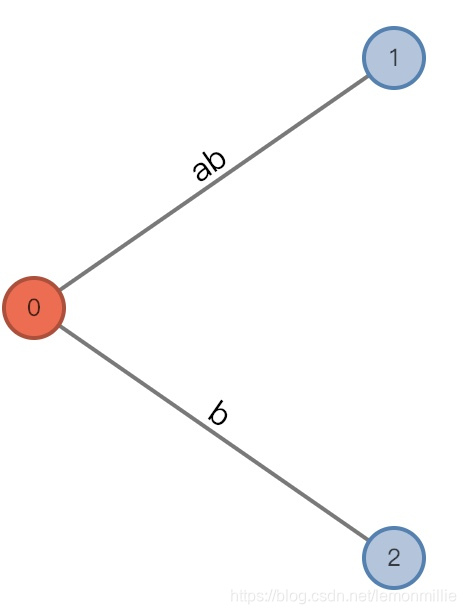
#=2, char='c'
- 增加前:
(root, "", 0), remainder = 1 - 为根节点增加一条边:
[2,],由于确实增加了条边,所以remainder会减少 - 增加后:
(root, "", 0), remainder = 0
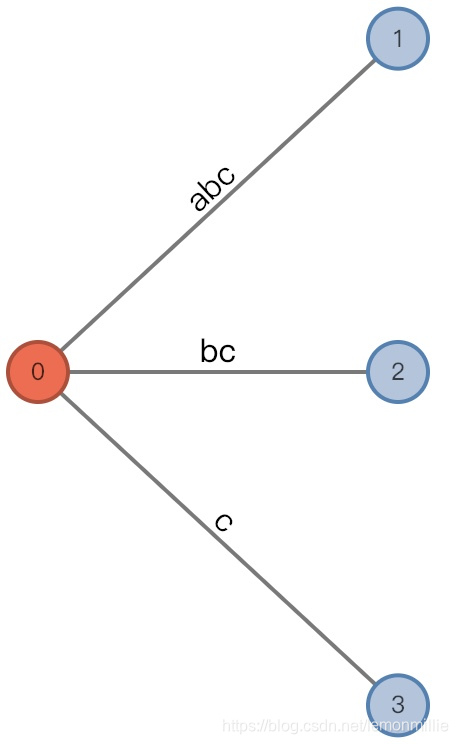
#=3, char='a'
- 增加前:
(root, "", 0), remainder = 1 - 由于新增加的后缀
a已经在根结点(活动节点)处伸了一个边出去了,所以这回不增加,只是修改三元组
现在我们知道了,三元组
(AN,AE,AL)的意思是,活动边为从AN伸出的以AE开头的边的第AL个字符后。
并且由于这条边表示为[i,],所以它的总长度应为#-i+1,分界线前最后一个字符为str[i+AL-1],分界线后第一个字符为i+AL - 增加后:
(root,"a"/[0,], 1), remainder = 1
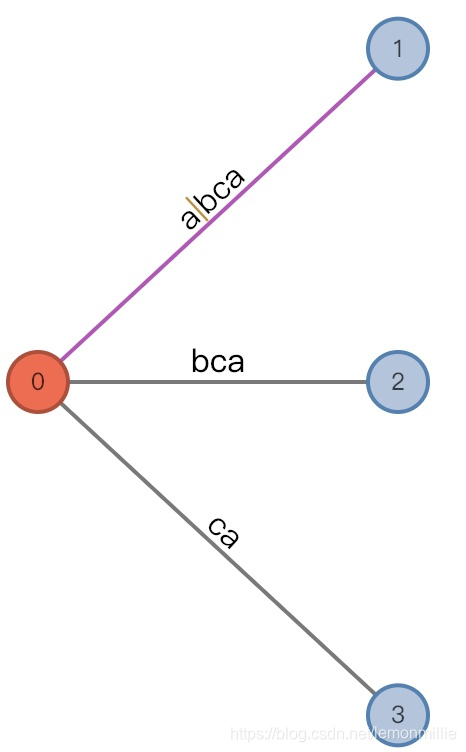
#=4, char='b'
- 增加前:
(root,"a"/[0,], 1), remainder = 2 - 发生的事情跟上一步一样
- 增加后:
(root,"a"/[0,], 2), remainder = 2
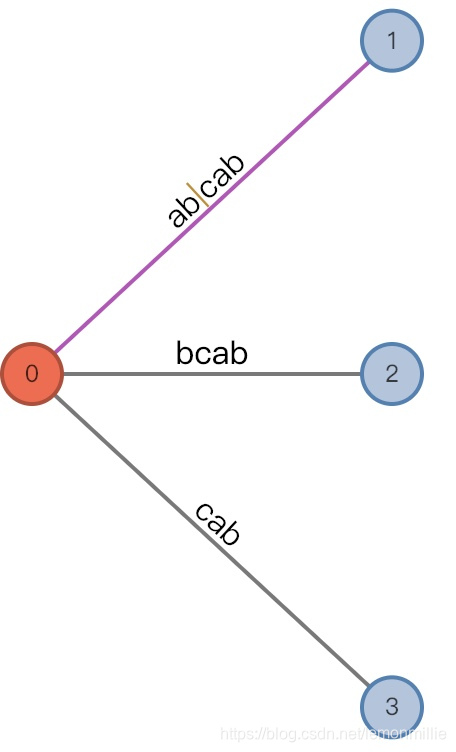
#=5, char='x'
增加前:
(root,"a"/[0,], 2), remainder = 3这一步发生了复杂的事情,现在有待增加的后缀已经有3个了,分别是
abx,bx和x可以看出,有待增加的后缀为
str[#-remainder+1:#]中的remainder个后缀由于
c和x不同,之前的偷懒现在要偿还了:第一个添加
abx,它必然在三元组指示的地方分裂,分裂一个新节点ab【其实也可以用下标, 后面再说】,原来的叶子边修改为[2,]【显然是因为[i+AL,]】,新增加的叶子结点一定为[5,]注意这里分裂的新结点是非叶结点!!! 因为相当于竖线的地方有个隐藏节点, 把它变成真实节点了
从另一个方面想, 为什么增加非叶结点呢? 是因为要保留原来1后面的子树 由于插入了一条边,remainder减少为2
由于插入了一条边,remainder减少为2然后执行向插入
bx。注意,原来三元组为(root, "a"/[0,], 2),匹配的是abx,那么显然,从root开始匹配bx的话,会从[1,]开始匹配,AL也减少一位。所以,插入b的时候三元组变成(root,"b"/[1, ], 1)(如上图)
插入x的时候新增中间节点"b",原来的[1,]变成[2,],新增叶子节点[5,]
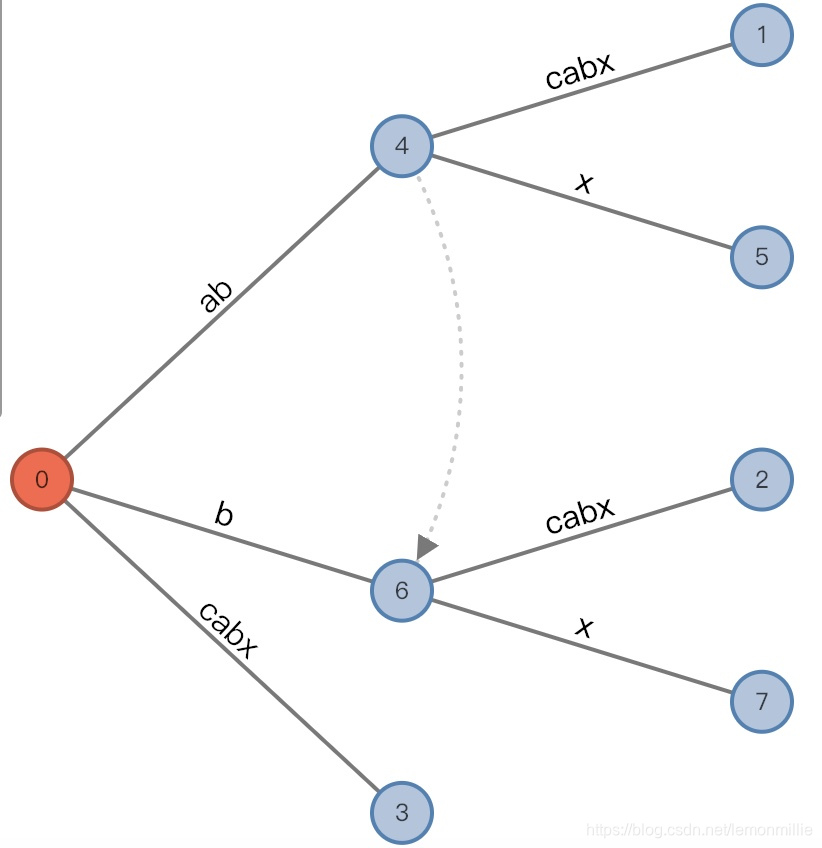
这里有一个新的规则:
在#相等的同一次扫描里,分裂的结点之间要有链接,由先分裂的指向后分裂的,如图现在remainder减少为1,因为
c和x不匹配,从root开始匹配x是找不到合适的边的,所以没办法将三元组变成(root,"c"/[2, ], 0),而既然活动长度为0了,三元组还是回到初始的(root,"", 0)状态,在这个状态下插入x,将直接插入新边[5,]
增加后:
(root,"", 0), remainder = 0
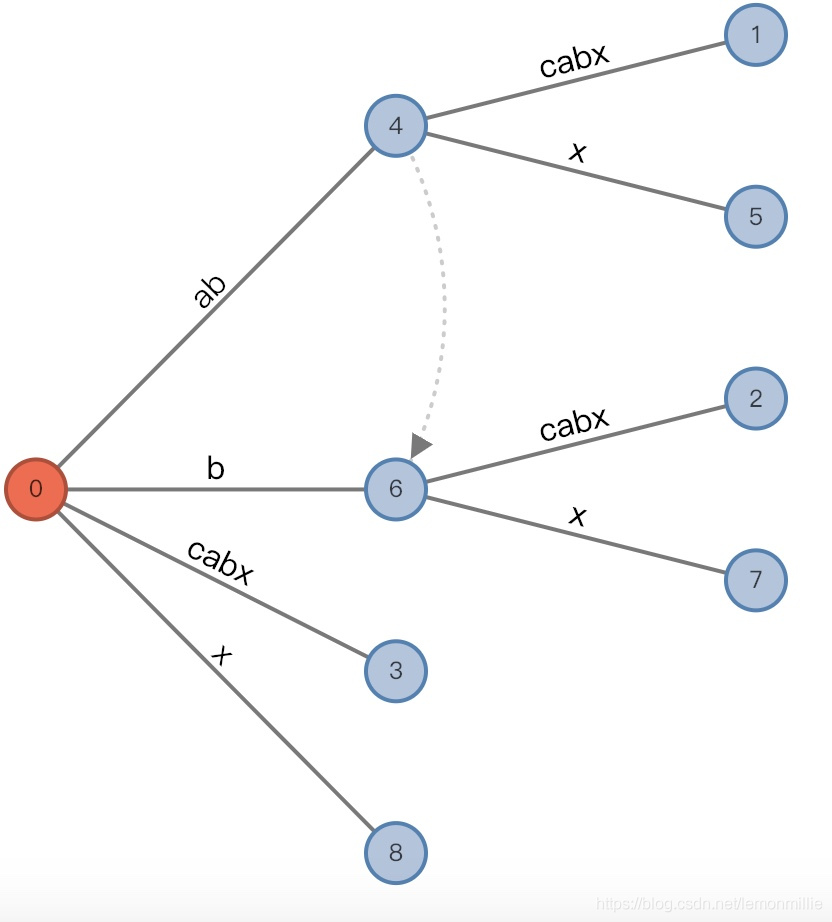
#=6, char='a'
- 增加前:
(root,"", 0), remainder = 1 - 发生的事情与
#=3时相似 - 增加后:
(root,"a"/"ab", 1), remainder = 1
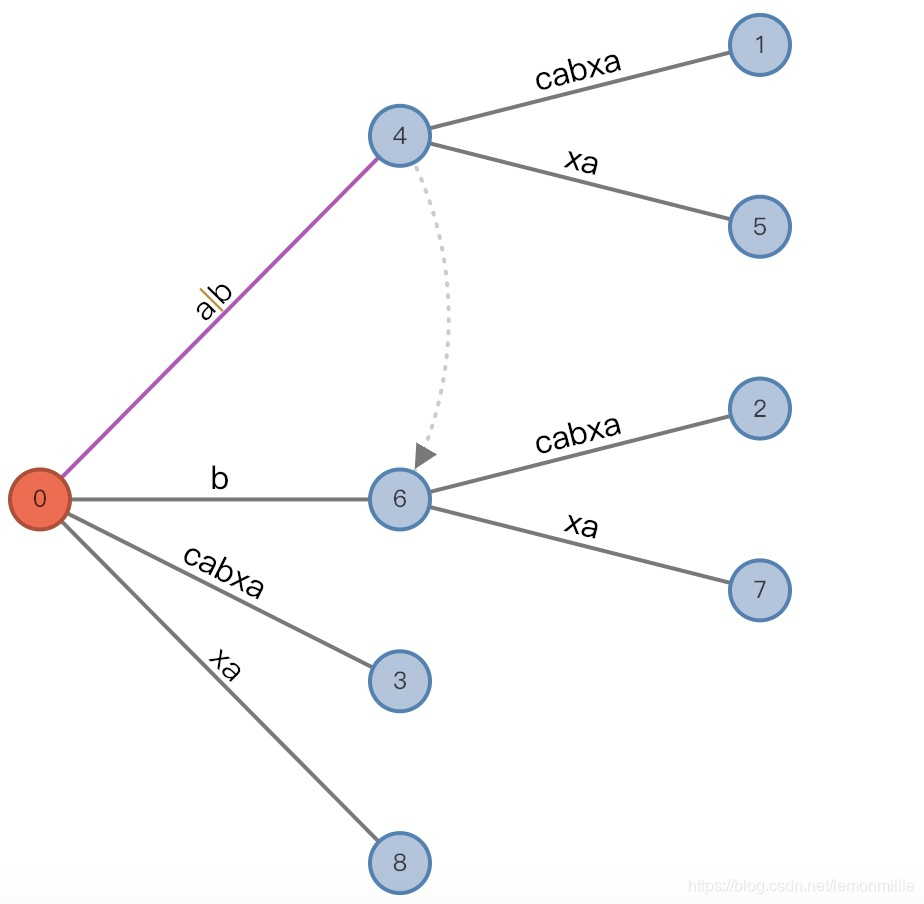
#=7, char='b'
- 增加前:
(root,"a"/"ab", 1), remainder = 2 - 发生的事情与
#=4时相似,不过这个时候我们发现中间结点"ab"已经遍历完成了,emmm那就要发生活动节点的转移:
(4,"", 0), remainder = 2 - 增加后:
(4,"", 0), remainder = 2

#=8, char='c'
- 增加前:
(4,"", 0), remainder = 3 - 推迟后缀的插入
- 增加后:
(4,"c"/[2,], 1), remainder = 3
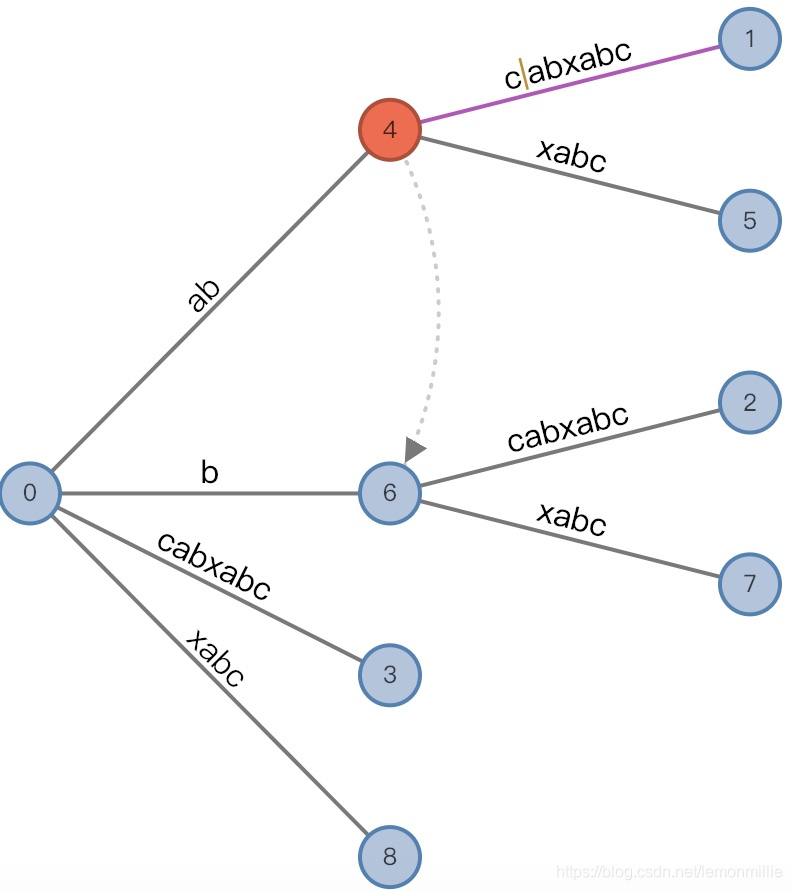
#=9, char='d'
- 增加前:
(4,"c"/[2,], 1), remainder = 4 - 这里发生的事情也很复杂:
首先按照之前说的,分裂活动节点
4,得到中间节点"c"和两个叶子节点[3,],[9,]。
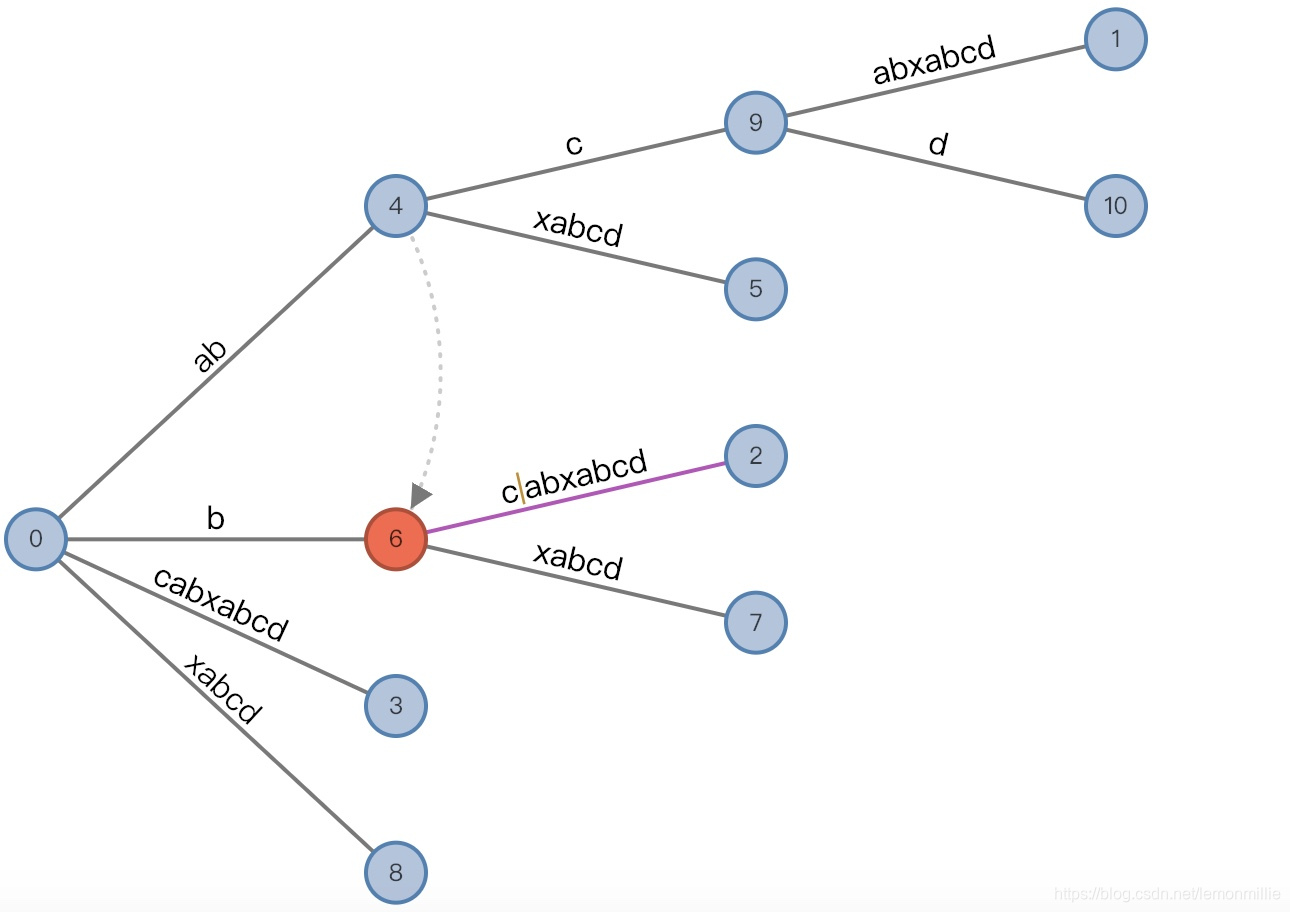
按照我们之前学习的规则,本来是要把状态改成:
(4,"", 0), remainder = 3然后再向活动节点4增加新后缀bcd的。
但是4不是根节点,所以它适用于一条新规则:向
(AN,AE,AL)添加完后缀,还要再添加新后缀时,如果节点不是根节点,则要将活动节点转移到链接的下一个节点(设为AN’,如果没有下一个节点,那就转移到root),并保持AE和AL不变。
这是因为下一个节点和这个节点有相同的边,所以AE和AL都不需要改变! 后面我们详细讨论这个链接所以状态变成
(6,"c"/[2,], 1), remainder = 3,然后再分裂,得到如图状态:
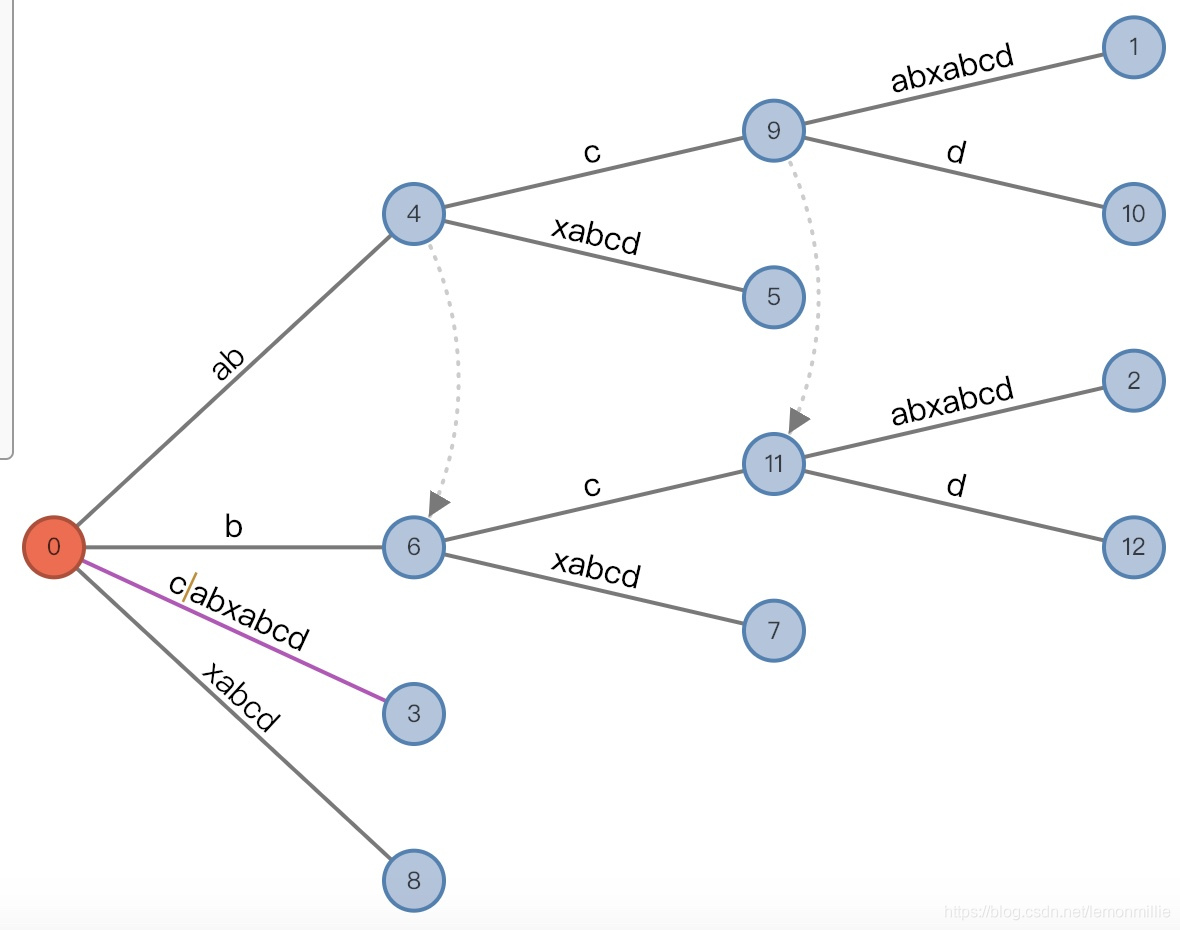
和(root,"c"/[2,], 1), remainder = 2,同时,由于发生了连续分裂,需要记录链接接下来的事情不用说了:
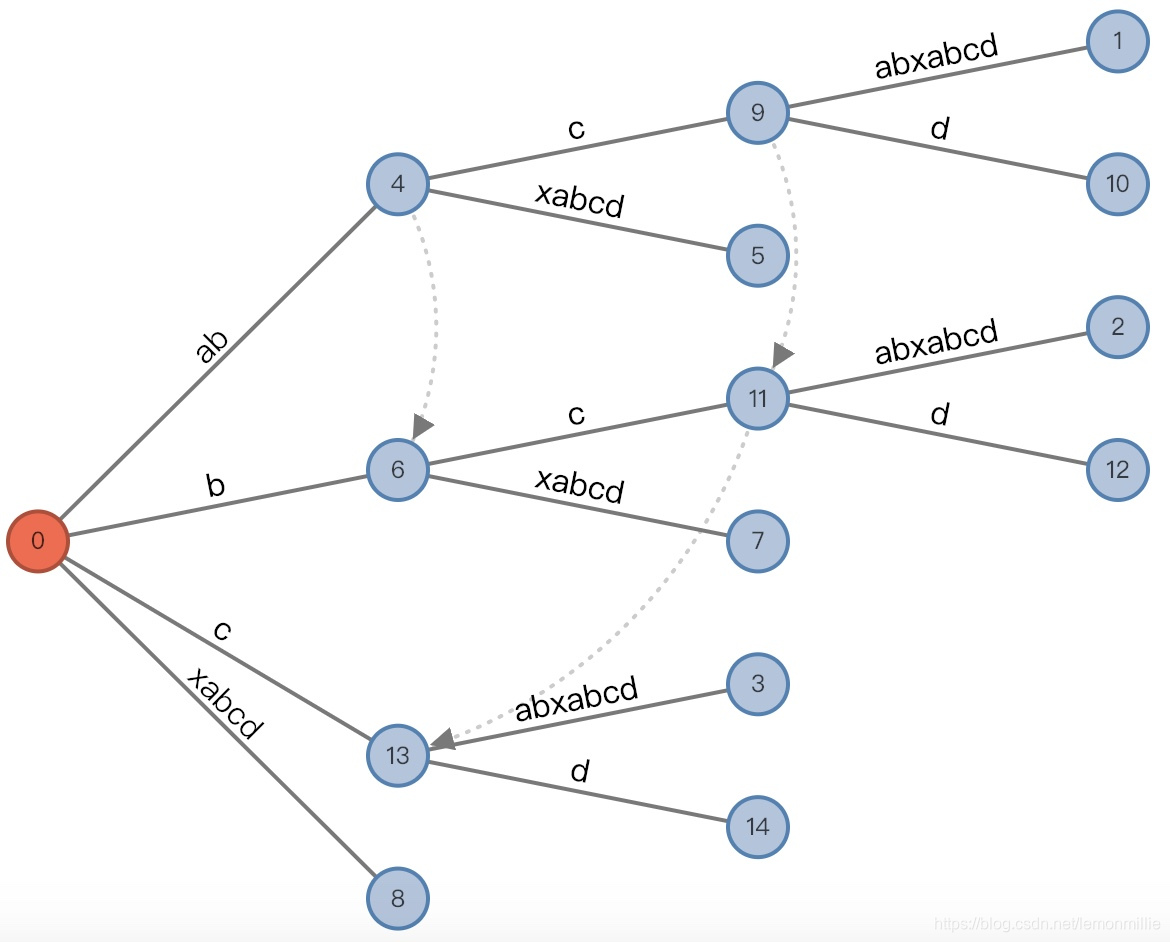
(root,"", 0), remainder = 1,记录链接最后再添加后缀
d
- 增加后:
(root,"", 0), remainder = 0
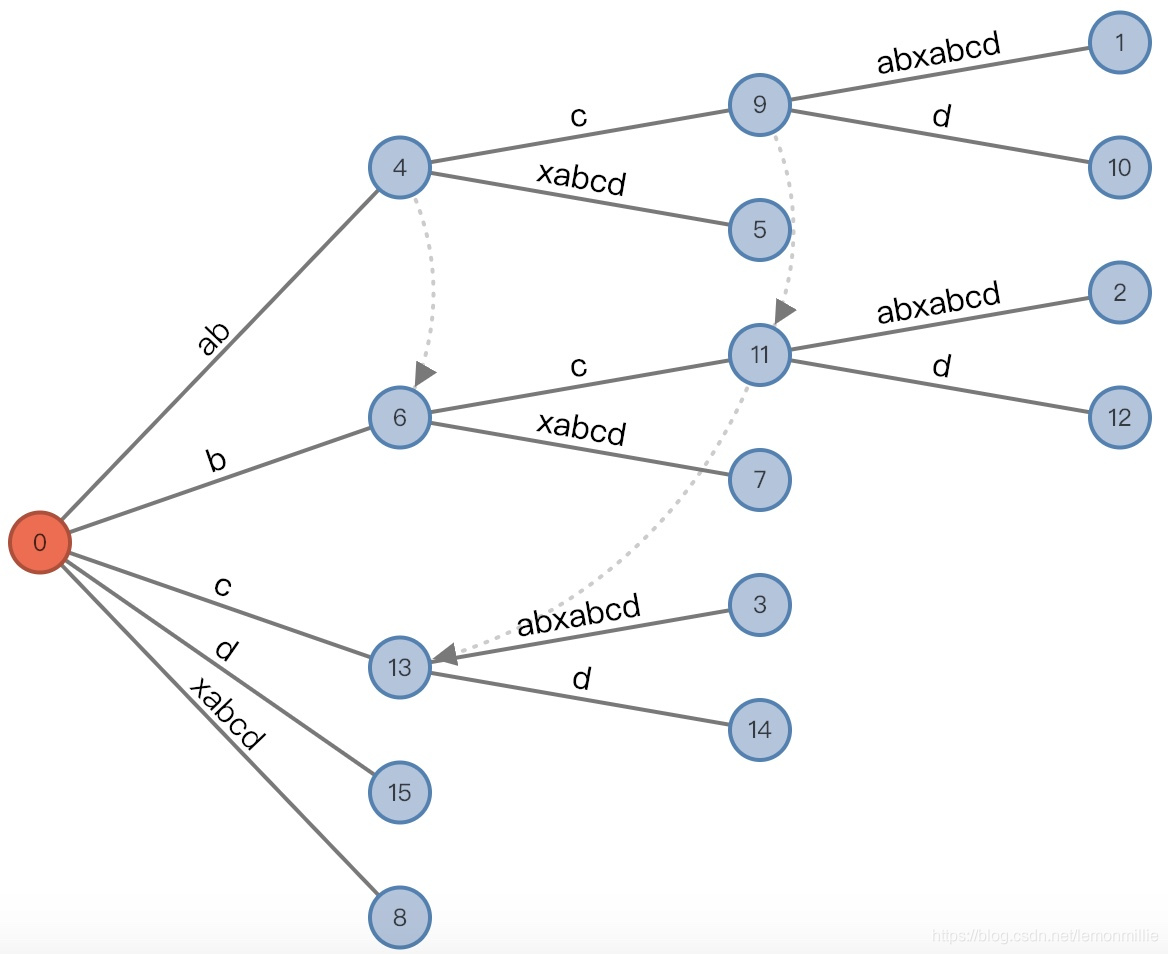
#=10, char='$'
最后还要假设添加一个虚拟结尾$,这是因为假如结束的时候remainer不为0,有一些后缀被隐藏在了活动节点里,这样得到的后缀树是隐式后缀树,不好用,我们需要保证后缀一定结束在叶子节点。
- 增加前:
(root,"", 0), remainder = 1 - root加了一个新边
- 增加后:
(root,"", 0), remainder = 0
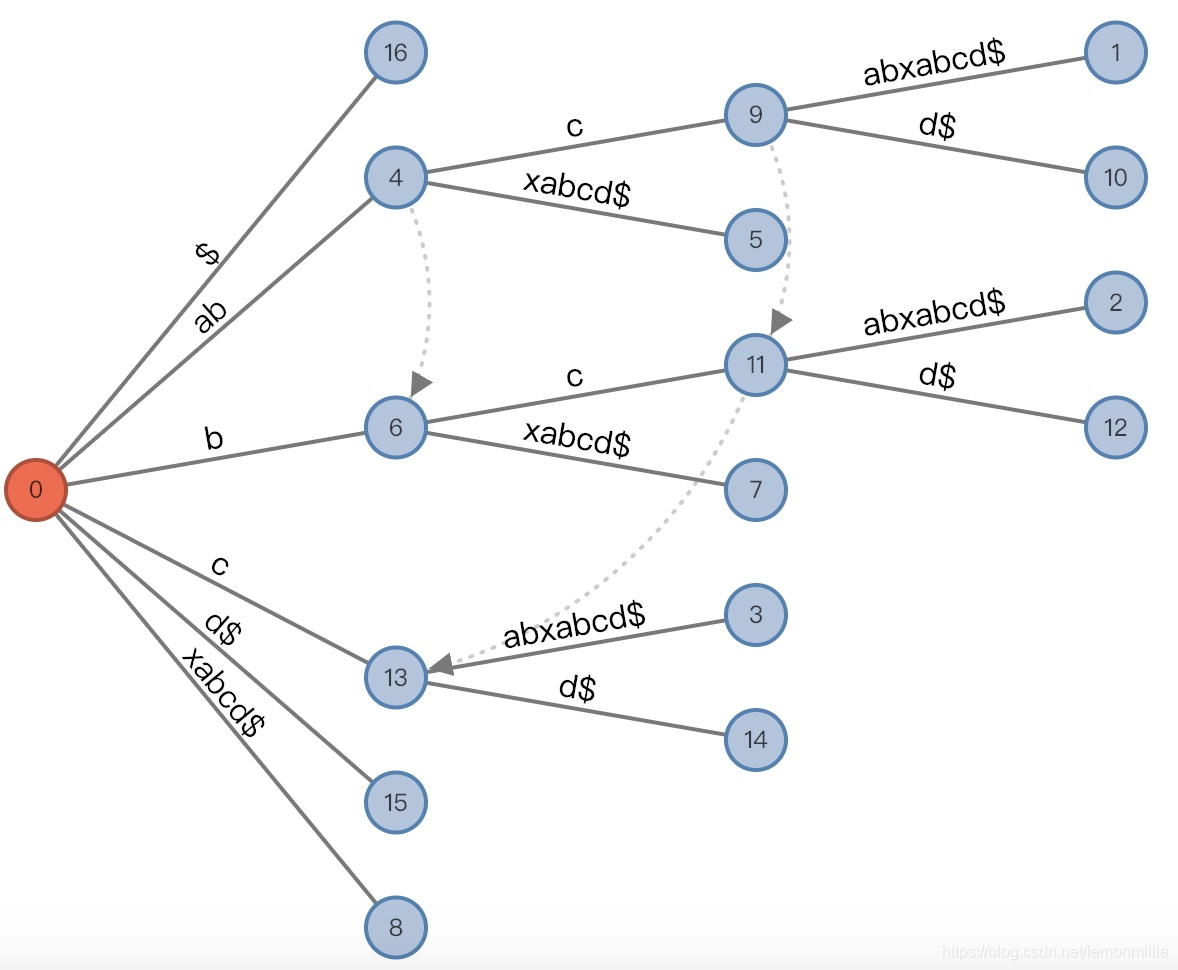
总结
而另一方面,竖线的位置又可以通过AL来计算,前面我们说过了,是i+AL。
此外,由于相等关系,还有一个等式:
str[i+j]==str[#−AL+j],∀0≤j<ALstr[i+j]==str[\#-AL+j], \forall 0\le j< ALstr[i+j]==str[#−AL+j],∀0≤j<AL
总之结论就是,在中间节点通过下标来记录的时候,这些相等关系可以减少我们需要保持的变量,实际使用的过程中根据自己代码的不同考虑清楚它们之间的关系即可。
链接的意义
从上面的图示明显可以看出,链接到一起的节点都伸出了相同的边,而分裂都发生在这些边上。
这是因为,某个位置#处发生的分裂都一定产生一条[#,]的边,所以链接到一起的节点一定有相同的边。
所以链接是为了快速地找到下一个分裂的节点,而不需要再从头开始匹配。
链接的最后一定是root,因为root一定存过所有的边
整理代码
状态变量:(AN,AL)
AE也不需要存,用#和AL返推出AE的首字母再从AN里查就可以了
树结构需求
叶子结点:
begin非叶子节点:
beginend- 边列表,按首字母存
- 链接
根结点:
- 边列表,按首字母存
综上,树节点可以定义为:
class SuffixNode(object):
def __init__(index, end=None, suffix=None):
self.begin = index
self.end = end
self.edge = {}
self.suffix = suffix
广义后缀树建立代码
写了一个,还没用题目测试过
class SuffixTree(object):
class SuffixTreeNode(object):
def __init__(self, index, end=None, suffix=None, isleaf = True):
self.begin = index
self.end = end
self.edge = {}
self.suffix = suffix
def __init__(self):
self.al = 0
self.s = ""
self.now = self.SuffixTreeNode(-1)
self.root = self.now
self.words = []
def add(self, string):
beg = len(self.s)
self.s += string+'$'
self.words.append(len(self.s))
end = len(self.s)
for ptr in xrange(beg,len(self.s)):
char = self.s[ptr]
self.al += 1 # 多一个等待存的后缀
last = None
while self.al:
ae = self.s[ptr - self.al+1]
if ae in self.now.edge:
# 有边, 开始匹配字符
sc = self.s[self.now.edge[ae].begin + self.al-1]
if sc == char:
# 如果匹配, 不增加边
# 如果有前驱节点, 存链接
if last!=None:
last.suffix = self.now
last = self.now
# 匹配满的时候转移活动节点
if self.al >= self.now.edge[ae].end-self.now.edge[ae].begin:
self.now = self.now.edge[ae]
self.al -= (self.now.end-self.now.begin)
break # 如果隐含了, 就不再分裂, 直接往下一个位置走
else:
# 如果不匹配, 开始分裂
new = self.SuffixTreeNode(self.now.edge[ae].begin, self.now.edge[ae].begin + self.al -1, self.root, False)
self.now.edge[ae].begin = self.now.edge[ae].begin + self.al -1
new.edge[char] = self.SuffixTreeNode(ptr, end)
new.edge[sc] = self.now.edge[ae]
self.now.edge[ae] = new
# 如果有前驱节点, 存链接
if last != None:
last.suffix = new # 因为new添加了新叶子节点
last = new
else:
# 没边, 添加一个新边
self.now.edge[ae] = self.SuffixTreeNode(ptr, end)
# 如果有前驱节点, 存链接
if last != None:
last.suffix = self.now # 因为new添加了新叶子节点
last = self.now
if self.now.begin != -1:
self.now = self.now.suffix
# 活动长度不用变
else:
self.al -= 1
后缀树的建立-Ukkonen算法的更多相关文章
- 广义后缀树(GST)算法的简介
导言 最近软件安全课上,讲病毒特征码的提取时,老师讲了一下GST算法.这里就做个小总结. 简介 基本信息 广义后缀树的英文为Generalized Suffix Tree,简称GST. 算法目的 ...
- [算法]从Trie树(字典树)谈到后缀树
我是好文章的搬运工,原文来自博客园,博主July_,地址:http://www.cnblogs.com/v-July-v/archive/2011/10/22/2316412.html 从Trie树( ...
- 从Trie树(字典树)谈到后缀树
转:http://blog.csdn.net/v_july_v/article/details/6897097 引言 常关注本blog的读者朋友想必看过此篇文章:从B树.B+树.B*树谈到R 树,这次 ...
- 后缀树 & 后缀数组
后缀树: 字符串匹配算法一般都分为两个步骤,一预处理,二匹配. KMP和AC自动机都是对模式串进行预处理,后缀树和后缀数组则是对文本串进行预处理. 后缀树的性质: 存储所有 n(n-1)/2 个后缀需 ...
- 012-数据结构-树形结构-哈希树[hashtree]、字典树[trietree]、后缀树
一.哈希树概述 1.1..其他树背景 二叉排序树,平衡二叉树,红黑树等二叉排序树.在大数据量时树高很深,我们不断向下找寻值时会比较很多次.二叉排序树自身是有顺序结构的,每个结点除最小结点和最大结点外都 ...
- 后缀树(Suffix Tree)
问题描述: 后缀树(Suffix Tree) 参考资料: http://www.cppblog.com/yuyang7/archive/2009/03/29 ...
- 后缀树的线性在线构建-Ukkonen算法
Ukkonen算法是一个非常直观的算法,其思想精妙之处在于不断加字符的过程中,用字符串上的一段区间来表示一条边,并且自动扩展,在需要的时候把边分裂.使用这个算法的好处在于它非常好写,代码很短,并且它是 ...
- 后缀树系列一:概念以及实现原理( the Ukkonen algorithm)
首先说明一下后缀树系列一共会有三篇文章,本文先介绍基本概念以及如何线性时间内构件后缀树,第二篇文章会详细介绍怎么实现后缀树(包含实现代码),第三篇会着重谈一谈后缀树的应用. 本文分为三个部分, 首先介 ...
- 笔试算法题(40):后缀数组 & 后缀树(Suffix Array & Suffix Tree)
议题:后缀数组(Suffix Array) 分析: 后缀树和后缀数组都是处理字符串的有效工具,前者较为常见,但后者更容易编程实现,空间耗用更少:后缀数组可用于解决最长公共子串问题,多模式匹配问题,最长 ...
随机推荐
- R语言学习记录(二)
4.对象改值 4.1.就地改值 比如: vec <- c(0,0,0,0,0,0,0) vec[1]<-100 #vec向量的第一个值就变为100 ####对于数据框的改值的方法,如下面的 ...
- Redis(一)【基础入门】
目录 一.大型网站的系统特点 二.大型网站架构发展历程 三.从NoSQL说起 四.Redis简介 五.Redis安装 1.上传并解压 2.安装C语言编译环境 3.修改安装位置 4.编译安装 5.启动R ...
- 面试一定会问到的-js事件循环
这篇文章讲讲浏览器的事件循环(nodejs中的事件循环稍有不同),事件循环是js的核心之一,因为js是单线程,所以异步事件实现就是依赖于事件循环机制,理解事件循环可让我们更清晰的处理js异步事件和应对 ...
- linux 6.5 网卡
启动网卡 ifup eth0 eth0:网卡名称 设置网卡开机启动 vi /etc/sysconfig/network-scripts/ifcfg-eth0 ONBOOT=yes
- show processlist命令详解
1.show processlist; SHOW PROCESSLIST显示哪些线程正在运行.您也可以使用mysqladmin processlist语句得到此信息.如果您有SUPER权限,您可以看到 ...
- tomcat 之 session服务器 (memcache)
#: 在tomcat各节点安装memcached [root@node1 ~]# yum install memcached -y #: 下载tomcat所需的jar包(此处在视频中找软件) [roo ...
- javascript将平行的拥有上下级关系的数据转换成树形结构
转换函数 var Littlehow = {}; /** * littlehow 2019-05-15 * 平行数据树形转换器 * @type {{format: tree.format, sort: ...
- 关于ssh-keygen 生成的key以“BEGIN OPENSSH PRIVATE KEY”开头
现在使用命令 ssh-keygen -t rsa 生成ssh,默认是以新的格式生成,id_rsa的第一行变成了"BEGIN OPENSSH PRIVATE KEY" 而不在是&q ...
- 使用buffered流结合byte数组,读入文件中的内容,包括中文字符
package com.itcast.demo05.Buffered;import java.io.BufferedInputStream;import java.io.FileInputStream ...
- 了解LINQ
本文主要的是泛谈LINQ是啥?以及常见的用法大纲如下: LINQ的那些根基 LINQ的一些基本用法 LINQ的根基 IEnumerable和IEnumerator 为啥能够被foreach? 实际上, ...