A100 GPU硬件架构
A100 GPU硬件架构
NVIDIA GA100 GPU由多个GPU处理群集(GPC),纹理处理群集(TPC),流式多处理器(SM)和HBM2内存控制器组成。
GA100 GPU的完整实现包括以下单元:
- 每个完整GPU 8个GPC,8个TPC / GPC,2个SM / TPC,16个SM / GPC,128个SM
- 每个完整GPU 64个FP32 CUDA内核/ SM,8192个FP32 CUDA内核
- 每个完整GPU 4个第三代Tensor核心/ SM,512个第三代Tensor核心
- 6个HBM2堆栈,12个512位内存控制器
GA100 GPU的A100 Tensor Core GPU实现包括以下单元:
- 7个GPC,7个或8个TPC / GPC,2个SM / TPC,最多16个SM / GPC,108个SM
- 每个GPU 64个FP32 CUDA内核/ SM,6912个FP32 CUDA内核
- 每个GPU 4个第三代Tensor内核/ SM,432个第三代Tensor内核
- 5个HBM2堆栈,10个512位内存控制器
显示了具有128个SM的完整GA100 GPU。A100基于GA100,具有108个SM。
GA100具有128个SM的完整GPU。A100 Tensor Core GPU具有108个SM。
A100 SM架构
新的A100 SM大大提高了性能,建立在Volta和Turing SM体系结构中引入的功能的基础上,并增加了许多新功能和增强功能。
A100 SM。Volta和Turing每个SM具有八个Tensor核心,每个Tensor核心每个时钟执行64个FP16 / FP32混合精度融合乘加(FMA)操作。A100 SM包括新的第三代Tensor内核,每个内核每个时钟执行256个FP16 / FP32 FMA操作。A100每个SM有四个Tensor核心,每个时钟总共可提供1024个密集的FP16 / FP32 FMA操作,与Volta和Turing相比,每个SM的计算能力提高了2倍。
SM的主要功能在此简要介绍,并在本文的后面部分进行详细描述:
- 第三代Tensor核心:
- 加速所有数据类型,包括FP16,BF16,TF32,FP64,INT8,INT4和二进制。
- 新的Tensor Core稀疏功能利用深度学习网络中的细粒度结构稀疏性,使标准Tensor Core操作的性能提高了一倍。
- A100中的TF32 Tensor Core操作提供了一条简单的路径来加速DL框架和HPC中的FP32输入/输出数据,其运行速度比V100 FP32 FMA操作快10倍,而具有稀疏性时则快20倍。
- FP16 / FP32混合精度Tensor Core操作为DL提供了空前的处理能力,运行速度比V100 Tensor Core操作快2.5倍,而稀疏性提高到5倍。
- BF16 / FP32混合精度Tensor Core操作以与FP16 / FP32混合精度相同的速率运行。
- FP64 Tensor Core操作为HPC提供了前所未有的双精度处理能力,运行速度是V100 FP64 DFMA操作的2.5倍。
- 具有稀疏性的INT8 Tensor Core操作为DL推理提供了空前的处理能力,运行速度比V100 INT8操作快20倍。
- 192 KB的组合共享内存和L1数据缓存,比V100 SM大1.5倍。
- 新的异步复制指令将数据直接从全局内存加载到共享内存中,可以选择绕过L1缓存,并且不需要使用中间寄存器文件(RF)。
- 与新的异步复制指令一起使用的新的基于共享内存的屏障单元(异步屏障)。
- L2缓存管理和驻留控制的新说明。
- CUDA合作小组支持新的经纱级减少指令。
- 进行了许多可编程性改进,以降低软件复杂性。
比较了V100和A100 FP16 Tensor Core操作,还比较了V100 FP32,FP64和INT8标准操作与相应的A100 TF32,FP64和INT8 Tensor Core操作。吞吐量是每个GPU的总和,其中A100使用针对FP16,TF32和INT8的稀疏Tensor Core操作。左上方的图显示了两个V100 FP16 Tensor核心,因为一个V100 SM每个SM分区有两个Tensor核心,而A100 SM一个。
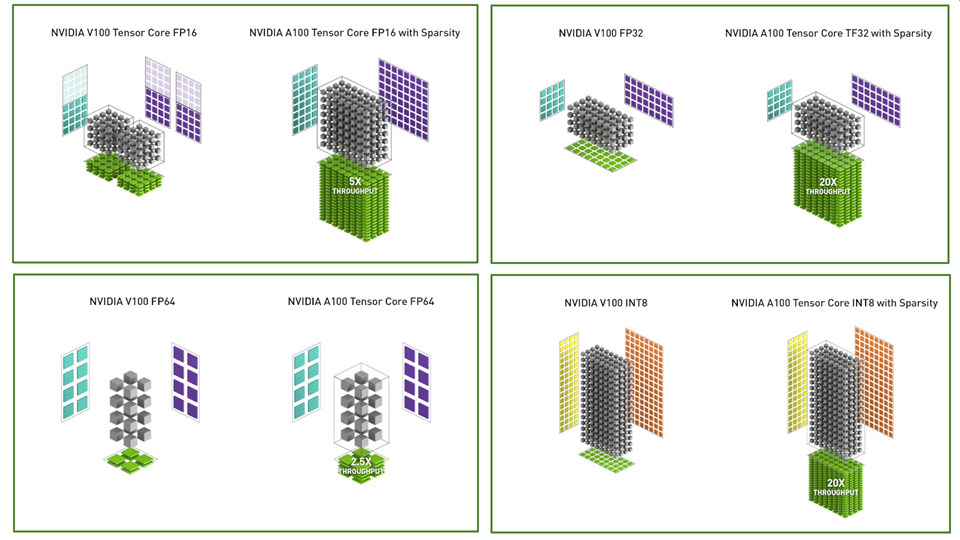
图1.将A100 Tensor Core操作与针对不同数据类型的V100 Tensor Core和标准操作进行比较。
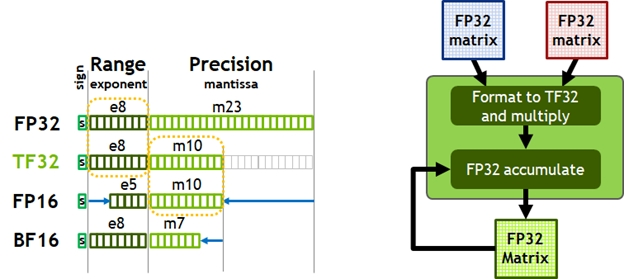
图2. TensorFloat-32(TF32)为FP32的范围提供了FP16的精度(左)。A100使用TF32加速张量数学运算,同时支持FP32输入和输出数据(右),从而可以轻松集成到DL和HPC程序中并自动加速DL框架。
今天,用于AI训练的默认数学是FP32,没有张量核心加速。NVIDIA Ampere架构引入了对TF32的新支持,使AI训练默认情况下可以使用张量内核,而无需用户方面的努力。非张量操作继续使用FP32数据路径,而TF32张量内核读取FP32数据并使用与FP32相同的范围,但内部精度降低,然后再生成标准IEEE FP32输出。TF32包含一个8位指数(与FP32相同),10位尾数(与FP16相同的精度)和1个符号位。
与Volta一样,自动混合精度(AMP)使可以将FP16与混合精度一起用于AI训练,而只需几行代码更改即可。使用AMP,A100的Tensor Core性能比TF32快2倍。
总而言之,用于DL训练的NVIDIA Ampere架构数学的用户选择如下:
- 默认情况下,使用TF32 Tensor Core,不调整用户脚本。与A100上的FP32相比,吞吐量高达8倍,而与V100上的FP32相比,吞吐量高达10倍。
- FP16或BF16混合精度训练应用于最大训练速度。与TF32相比,吞吐量提高了2倍,与A100上的FP32相比,吞吐量提高了16倍,而与V100上的FP32相比,吞吐量提高了20倍。
A100 GPU硬件架构的更多相关文章
- 深入GPU硬件架构及运行机制
目录 一.导言 1.1 为何要了解GPU? 1.2 内容要点 1.3 带着问题阅读 二.GPU概述 2.1 GPU是什么? 2.2 GPU历史 2.2.1 NV GPU发展史 2.2.2 NV GPU ...
- 在NVIDIA A100 GPU中使用DALI和新的硬件JPEG解码器快速加载数据
在NVIDIA A100 GPU中使用DALI和新的硬件JPEG解码器快速加载数据 如今,最流行的拍照设备智能手机可以捕获高达4K UHD的图像(3840×2160图像),原始数据超过25 MB.即使 ...
- 在NVIDIA A100 GPU上利用硬件JPEG解码器和NVIDIA nvJPEG库
在NVIDIA A100 GPU上利用硬件JPEG解码器和NVIDIA nvJPEG库 根据调查,普通人产生的1.2万亿张图像可以通过电话或数码相机捕获.这样的图像的存储,尤其是以高分辨率的原始格式, ...
- 全球最低功耗蓝牙单芯片DA14580的硬件架构和低功耗
号称全球最低功耗蓝牙单芯片DA14580在可穿戴市场.健康医疗.ibeacon定位等市场得到广泛的应用,但是因为其较为封闭的技术/资料支持导致开发人员有较高的技术门槛,网络上也极少看到有关DA1458 ...
- CUDA01 - 硬件架构、warp调度、指令流水线和cuda并发流
这一部分打算从头记录一下CUDA的编程方法和一些物理架构上的特点:从硬件入手,写一下包括线程束的划分.流水线的调度等等微结构的问题,以及这些物理设备是如何与软件对应的.下一部分会写一下cuda中的几种 ...
- [IE9] GPU硬件加速
IE9 的一个重大改进就是使用了GPU硬件加速来渲染网页. 那么GPU硬件加速到底能够带来多大的性能提升? 你可以在IE的测试案例网站(http://ie.microsoft.com/testdr ...
- GPU硬件加速原理 /转
现代浏览器大都可以利用GPU来加速页面渲染.每个人都痴迷于60桢每秒的顺滑动画.在GPU的众多特性之中,它可以存储一定数量的纹理(一个矩形的像素点集合)并且高效地操作这些纹理(比如进行特定的移动.缩放 ...
- HackRF One硬件架构及参数简介
本文内容.开发板及配件仅限用于学校或科研院所开展科研实验! 淘宝店铺名称:开源SDR实验室 HackRF链接:https://item.taobao.com/item.htm?spm=a1z10.1- ...
- GPU体系架构(一):数据的并行处理
最近在了解GPU架构这方面的内容,由于资料零零散散,所以准备写两篇博客整理一下.GPU的架构复杂无比,这两篇文章也是从宏观的层面去一窥GPU的工作原理罢了 GPU根据厂商的不同,显卡型号的不同,GPU ...
随机推荐
- Thinkphp5助手函数和Thinkphp3的单字母函数对应参照表
- 【Feign/Ribbon】记录一次生产上的SpringCloudFeign的重试问题
在上周在的微供有数项目中(数据产品),需要对接企业微信中第三方应用,在使用Feign的去调用微服务的用户模块用微信的code获取access_token以及用户工厂信息时出现Feign重试超时报错的情 ...
- 路由器逆向分析------firmware-mod-kit工具安装和使用说明
本文博客地址:http://blog.csdn.net/qq1084283172/article/details/68061957 一.firmware-mod-kit工具的安装 firmware-m ...
- POJ2337 欧拉路径字典序输出
题意: 给一些单词,问是否可以每个单词只用一次,然后连接在一起(不一定要成环,能连接在一起就行). 思路: 这个题目的入手点比较好想,其实就是问欧拉路径,先说下解题步骤,然后在 ...
- 《THE LEAN STARTUP》 《精益创业》
书名:<THE LEAN STARTUP> <精益创业> 作者: [美] 埃里克·莱斯 IMVU:(3D人物场景聊天)https://secure.imvu.com 作者是这个 ...
- 【phpstorm】Server's certificate is not trusted
问题描述 phpstorm 一直跳出 问题解决 file-->Settings然后搜索Server Certificates,选中框打钩
- 想要测试Dubbo接口?测试的关键点在哪里?
Dubbo接口如何测试? 这个dubbo如何测试,dubbo接口测试什么玩意儿? RPC的有一个类型,叫Dubbo接口. 那这个接口如何测试?测试的关键点在哪里? 这个面试问题,我觉得大家可能就有 ...
- JWT 基本使用
JWT 基本使用 在上一节中 session 共享功能使用 redis 进行存储,用户量激增时会导致 redis 崩溃,而 JWT 不依赖服务器,能够避免这个问题. 1.传统 session 1.1. ...
- NABCD-name not found
项目 内容 课程 2020春季计算机学院软件工程(罗杰 任健) 作业要求 团队项目选择 项目名称 FOTT 项目内容 在OCR-Form-Tools开源项目的基础上,扩展功能,支持演示更多的API,例 ...
- 技能Get·BOM头是什么?
阅文时长 | 0.26分钟 字数统计 | 472.8字符 主要内容 | 1.引言&背景 2.BOM头是什么? 3.如何创建或取消BOM头? 4.如何判断文件是否包含BOM头? 5.声明与参考资 ...