【kafka学习笔记】合理安排broker、partition、consumer数量
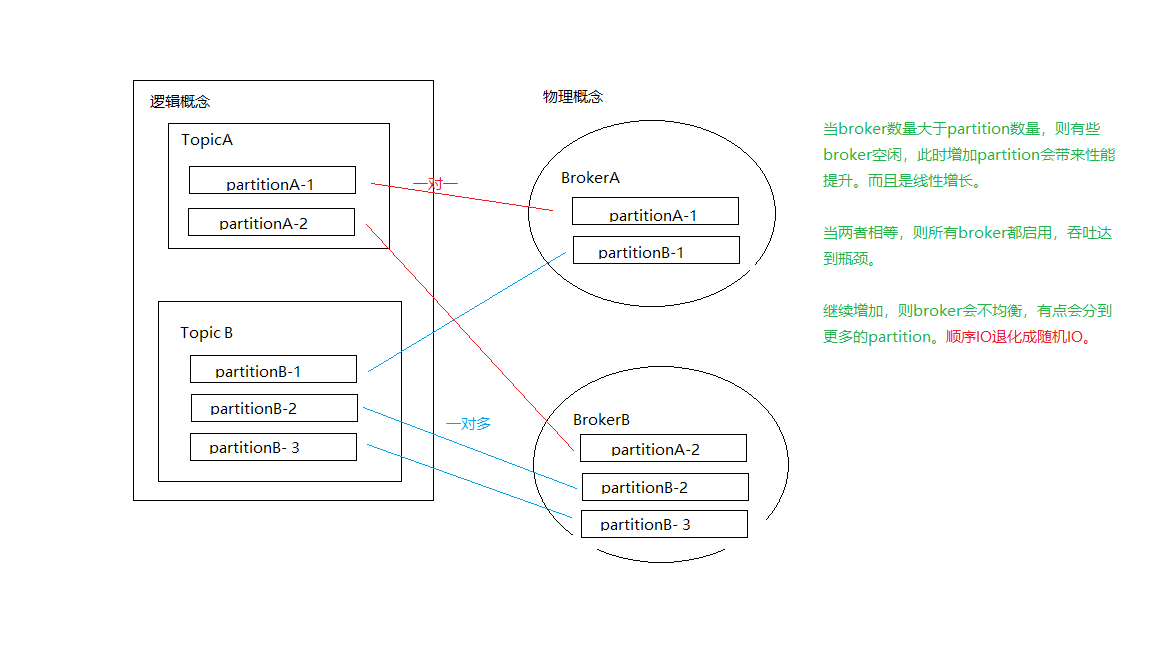
broker的数量最好大于等于partition数量
一个partition最好对应一个硬盘,这样能最大限度发挥顺序写的优势。
broker如果免得是多个partition,需要随机分发,顺序IO会退化成随机IO。
实验条件:3个 Broker,1个 Topic,无Replication,异步模式,3个 Producer,消息 Payload 为100字节:
当 Partition 数量小于 Broker个数时,Partition 数量越大,吞吐率越高,且呈线性提升。
Kafka 会将所有 Partition 均匀分布到所有Broker 上,所以当只有2个 Partition 时,会有2个 Broker 为该 Topic 服务。3个 Partition 时同理会有3个 Broker 为该 Topic 服务。
当 Partition 数量多于 Broker 个数时,总吞吐量并未有所提升,甚至还有所下降。
可能的原因是,当 Partition 数量为4和5时,不同 Broker 上的 Partition 数量不同,而 Producer 会将数据均匀发送到各 Partition 上,这就造成各Broker 的负载不同,不能最大化集群吞吐量。
• 当broker数量大于partition数量,则有些broker空闲,此时增加partition会带来性能提升。而且是线性增长。
• 当两者相等,则所有broker都启用,吞吐达到瓶颈。
• 继续增加,则broker会不均衡,有点会分到更多的partition。
顺序IO退化成随机IO。
consumer数量最好和partition数量一致
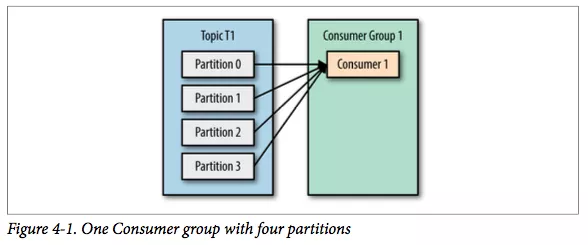
假设有一个 T1 主题,该主题有 4 个分区;同时我们有一个消费组 G1,这个消费组只有一个消费者 C1。
那么消费者 C1 将会收到这 4 个分区的消息。
如果我们增加新的消费者 C2 到消费组 G1,那么每个消费者将会分别收到两个分区的消息。
相当于 T1 Topic 内的 Partition 均分给了 G1 消费的所有消费者,在这里 C1 消费 P0 和 P2,C2 消费 P1 和 P3。

如果增加到 4 个消费者,那么每个消费者将会分别收到一个分区的消息。 这时候每个消费者都处理其中一个分区,满负载运行。
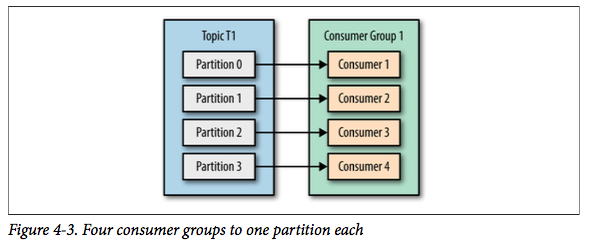
但如果我们继续增加消费者到这个消费组,剩余的消费者将会空闲,不会收到任何消息。
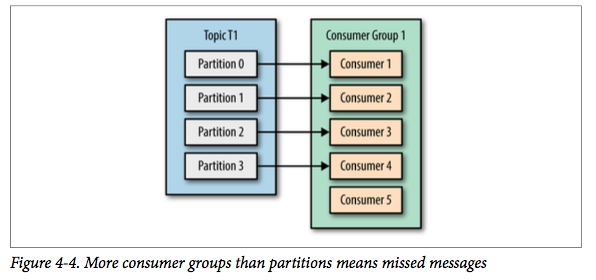
总而言之,我们可以通过增加消费组的消费者来进行水平扩展提升消费能力。 这也是为什么建议创建主题时使用比较多的分区数,这样可以在消费负载高的情况下增加消费者来提升性能。
另外,消费者的数量不应该比分区数多,因为多出来的消费者是空闲的,没有任何帮助。 如果我们的 C1 处理消息仍然还有瓶颈,我们如何优化和处理?
把 C1 内部的消息进行二次 sharding,开启多个 goroutine worker 进行消费,为了保障 offset 提交的正确性,需要使用 watermark 机制,保障最小的 offset 保存,才能往 Broker 提交。
● 保证顺序性,避免大的offest先提交,小的offest挂了,重启后会消息丢失。
● 解决:开一个协程专门提交offest,保证只提交最小的,重复消费代替消息丢失。
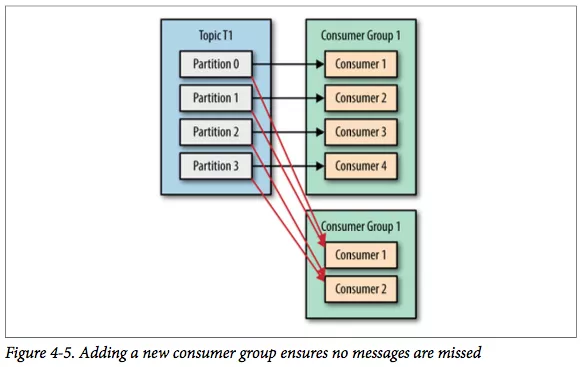
Kafka 一个很重要的特性就是,只需写入一次消息,可以支持任意多的应用读取这个消息。 换句话说,每个应用都可以读到全量的消息。为了使得每个应用都能读到全量消息,应用需要有不同的消费组。
对于上面的例子,假如我们新增了一个新的消费组 G2,而这个消费组有两个消费者如图。 在这个场景中,消费组 G1 和消费组 G2 都能收到 T1 主题的全量消息,在逻辑意义上来说它们属于不同的应用。
最后,总结起来就是:如果应用需要读取全量消息,那么请为该应用设置一个消费组;如果该应用消费能力不足,那么可以考虑在这个消费组里增加消费者。
【kafka学习笔记】合理安排broker、partition、consumer数量的更多相关文章
- Kafka 学习笔记之 High Level Consumer相关参数
High Level Consumer相关参数 自动管理offset auto.commit.enable = true auto.commit.interval.ms = 60*1000 手动管理o ...
- 大数据 -- kafka学习笔记:知识点整理(部分转载)
一 为什么需要消息系统 1.解耦 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险.许多 ...
- kafka学习笔记(一)消息队列和kafka入门
概述 学习和使用kafka不知不觉已经将近5年了,觉得应该总结整理一下之前的知识更好,所以决定写一系列kafka学习笔记,在总结的基础上希望自己的知识更上一层楼.写的不对的地方请大家不吝指正,感激万分 ...
- Kafka 学习笔记之 Kafka0.11之console-producer/console-consumer
Kafka 学习笔记之 Kafka0.11之console-producer/console-consumer: 启动Zookeeper 启动Kafka0.11 创建一个新的Topic: ./kafk ...
- Kafka学习笔记之Kafka Consumer设计解析
0x00 摘要 本文主要介绍了Kafka High Level Consumer,Consumer Group,Consumer Rebalance,Low Level Consumer实现的语义,以 ...
- Kafka学习笔记(5)----Kafka的Consumer
1. Pull vs Push Producer主动的通过push将消息发布到Broker上,Consumer通过Pull的的方式从Broker消息消息. 通过Push的方式由于是一有消息就推到Bro ...
- Kafka学习笔记(二):Partition分发策略
kafka版本0.8.2.1 Java客户端版本0.9.0.0 为了更好的实现负载均衡和消息的顺序性,Kafka Producer可以通过分发策略发送给指定的Partition.Kafka保证在par ...
- kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- [Big Data - Kafka] kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
随机推荐
- C#窗体学习
//进度条控件 private void button1_Click(object sender, EventArgs e) { int i; ...
- FastAPI(六十二)实战开发《在线课程学习系统》需求分析
前言 基础的分享我们已经分享了六十篇,那么我们这次分享开始将用一系列的文章分享实战课程.我们分享的系统是在线学习系统.我们会分成不同的模块进行分享.我们的目的是带着大家去用fastapi去实战一次,开 ...
- C/C++ Qt ListWidget 列表框组件应用
ListWidget列表框组件,该组件与TreeWidget有些相似,区别在于TreeWidget可以实现嵌套以及多字段结构,而ListWidget组件则只能实现单字段结构,ListWidget组件常 ...
- Stupid && 祖传Fortran代码救赎之路(编译Dll)
Stupid && 祖传Fortran代码救赎之路(编译Dll) gfortran编译动态库 在Windows平台下,Intel Fortran安装过于庞大且费事(现在集成到OneAP ...
- 【POJ1845】Sumdiv【算数基本定理 + 逆元】
描述 Consider two natural numbers A and B. Let S be the sum of all natural divisors of A^B. Determine ...
- Codeforces 1361C - Johnny and Megan's Necklace(欧拉回路)
Codeforces 题目传送门 & 洛谷题目传送门 u1s1 感觉这个题作为 D1C 还是蛮合适的-- 首先不难发现答案不超过 \(20\),所以可以直接暴力枚举答案并 check 答案是否 ...
- CF1208H Red Blue Tree
CF1208H Red Blue Tree 原本应该放在这里但是这题过于毒瘤..单独开了篇blog 首先考虑如果 $ k $ 无限小,那么显然整个树都是蓝色的.随着 $ k $ 逐渐增大,每个点都会有 ...
- python3 excel读、写、修改操作
python3上Excel文件操作的库比较多,新手一开始不知道如何选择合适的库,故整理如下: xlwt: 只能写不能读,只支持python2.3到python2.7版本,只支持xls文件. xlrd ...
- C++你不知道的事
class A { public: A() { cout<<"A's constructor"<<endl; } virtual ~A() { cout&l ...
- C/C++ Qt 数据库与TableView多组件联动
Qt 数据库组件与TableView组件实现联动,以下案例中实现了,当用户点击并选中TableView组件内的某一行时,我们通过该行中的name字段查询并将查询结果关联到ListView组件内,同时将 ...