Kafka学习笔记(5)----Kafka的Consumer
1. Pull vs Push
Producer主动的通过push将消息发布到Broker上,Consumer通过Pull的的方式从Broker消息消息。
通过Push的方式由于是一有消息就推到Broker,所以极大的保证了消息实时性,但是在某些情况下,可能由于Consumer网络,或是其他原因倒是消费速度低,此时就可能会导致Consumer堆积大量的消息,甚至在极端情况下会压垮Consumer.
通过Pull拉取消息保证了Consumer能够按自己实际处理能力来拉取相应的消息,并且Broker的实现也相对简单,但是也会出现在消息处理能力很低的情况下造成消息的实时性过低。
kafka提供了High Level Consumer和High Level Consume两种方式的API。
2. High Level Consumer
很多应用场景下,客户程序只是希望从Kafka顺序读取并处理数据,而不太关心具体的offset。它同时也希望提供一些语义,例如同一条消息只被某一个Consumer消费(单播)或被所有Consumer消费(广播),Kafka High Level API提供了一个从Kafka消费数据的高层抽象,从而屏蔽掉其中的细节,并提供丰富的语义。
在Kafka中,High Level Consumer将从某个Partition读取的最后一条消息的offset存于Zookeeper中(从0.8.2开始同时支持将offset存于Zookeeper中和专用的Kafka Topic中)。这个offset基于客户程序提供给Kafka的名字来保存,这个名字被称为Consumer Group,Consumer Group是整个Kafka集群全局唯一的,而非针对某个Topic的。每个High Level Consumer实例都属于一Consumer Group,若不指定则属于默认的Group。在消息被消费之后,消息并不会立即被删除,只是相应的offset加一,若以可能Consumer中的offset将会跟消息的数据一样多,
在High Level Consumer下由于存在了关联关系(Group ),所以消息删除也将不再是到一定时间或消息条数达到某个值就删除,而是通过压缩的方式,保留最新的key的value的方式。具体示例如下:
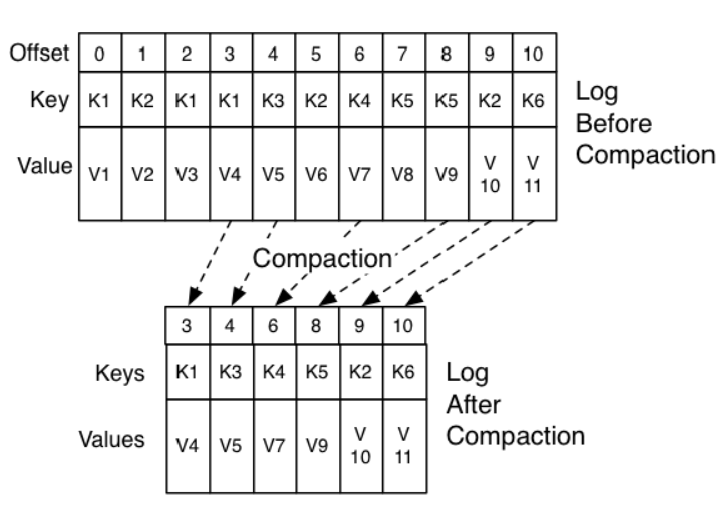
这样就保证了消息与offset之间仍然是正确的对应关系。
对于每条消息,在同一个Consumer Gourp里都只会被一个Consumer消费,不同的Cosumer Group可以消费同一条消息。
如下:
Kafka的设计理念之一就是同时提供对离线批处理和在线流处理的支持。可以同时使用Hadoop系统进行离线批处理,Storm或它流处理系统进行流处理。也可使用Kafka的Mirror Maker将消息从一个数据中心镜像到另一个数据中心。
如图:

Consumer的Rebalance(平衡策略)
High Level Consumer启动时将其ID注册到其Consumer Group下,在Zookeeper上的路径为/consumers/[consumer group]/ids/[consumer id],在/consumers/[consumer group]/ids上注册Watch,在/brokers/ids上注册Watch,如果Consumer通过Topic Filter创建消息流,则它会同时在/brokers/topics上也创建Watch,强制自己在其Consumer Group内启动Rebalance流程
Rebalance算法
1. 将目标Topic下的所有Partirtion排序,存于PT
2. 对某Consumer Group下所有Consumer排序,存于CG,第i个Consumer记为Ci
3. N=size(PT)/size(CG) ,向上取整
4. 解除Ci对原来分配的Partition的消费权(i从0开始)
5. 将第i∗N 到(i+1)∗N−1个Partition分配给Ci
Rebalance算法也存在如下缺点:
1. Herd Effect: 任何Broker或者Consumer的增减都会触发所有的Consumer的Rebalance
2. Split Brain: 每个Consumer分别单独通过Zookeeper判断哪些Broker和Consumer宕机,同时Consumer在同一时刻从Zookeeper“看”到的View可能不完全一样,这是由Zookeeper的特性决定的。
3. 调整结果不可控所有Consumer分别进行Rebalance,彼此不知道对应的Rebalance是否成功
3. Low Level Consumer
使用Low Level Consumer (Simple Consumer)的主要原因是,用户希望比Consumer Group更好的控制数据的消费,如:
1. 同一条消息读多次,方便Replay
2. 只消费某个Topic的部分Partition
3. 管理事务,从而确保每条消息被处理一次(Exactly once)
与High Level Consumer相对,Low Level Consumer要求用户做大量的额外工作
1. 在应用程序中跟踪处理offset,并决定下一条消费哪条消息
2. 获知每个Partition的Leader
3. 处理Leader的变化
5. 处理多Consumer的协作
Kafka学习笔记(5)----Kafka的Consumer的更多相关文章
- Kafka学习笔记之Kafka Consumer设计解析
0x00 摘要 本文主要介绍了Kafka High Level Consumer,Consumer Group,Consumer Rebalance,Low Level Consumer实现的语义,以 ...
- Kafka学习笔记之Kafka三款监控工具
0x00 概述 在之前的博客中,介绍了Kafka Web Console这 个监控工具,在生产环境中使用,运行一段时间后,发现该工具会和Kafka生产者.消费者.ZooKeeper建立大量连接,从而导 ...
- Kafka学习笔记之Kafka性能测试方法及Benchmark报告
0x00 概述 本文主要介绍了如何利用Kafka自带的性能测试脚本及Kafka Manager测试Kafka的性能,以及如何使用Kafka Manager监控Kafka的工作状态,最后给出了Kafka ...
- Kafka学习笔记之Kafka背景及架构介绍
0x00 概述 本文介绍了Kafka的创建背景,设计目标,使用消息系统的优势以及目前流行的消息系统对比.并介绍了Kafka的架构,Producer消息路由,Consumer Group以及由其实现的不 ...
- Kafka 学习笔记之 High Level Consumer相关参数
High Level Consumer相关参数 自动管理offset auto.commit.enable = true auto.commit.interval.ms = 60*1000 手动管理o ...
- Kafka学习笔记之Kafka High Availability(下)
0x00 摘要 本文在上篇文章基础上,更加深入讲解了Kafka的HA机制,主要阐述了HA相关各种场景,如Broker failover,Controller failover,Topic创建/删除,B ...
- Kafka学习笔记之Kafka High Availability(上)
0x00 摘要 Kafka在0.8以前的版本中,并不提供High Availablity机制,一旦一个或多个Broker宕机,则宕机期间其上所有Partition都无法继续提供服务.若该Broker永 ...
- Kafka学习笔记1——Kafka的安装和启动
一.准备工作 1. 安装JDK 可以用命令 java -version 查看版本
- Kafka学习笔记之Kafka自身操作日志的清理方法(非Topic数据)
0x00 概述 本文主要讲Kafka自身操作日志的清理方法(非Topic数据),Topic数据自己有对应的删除策略,请看这里. Kafka长时间运行过程中,在kafka/logs目录下产生了大量的ka ...
- Kafka学习笔记之Kafka日志删出策略
0x00 概述 kafka将topic分成不同的partitions,每个partition的日志分成不同的segments,最后以segment为单位将陈旧的日志从文件系统删除. 假设kafka的在 ...
随机推荐
- 认识计算机操作系统(day01)
一.计算机的框架 什么是操作系统?(汽车) 加油系统 油门 用户跟加油子系统交互的窗口.(接口) 方向系统 方向盘 用户跟方向系统的交互接口. 导航系统 ... 汽车的操作系统有很多的子系统来完成.这 ...
- [bzoj1860 ZJOI2006] 超级麻将 (线性dp)
传送门 Description Input 第一行一个整数N(N<=100),表示玩了N次超级麻将. 接下来N行,每行100个数a1..a100,描述每次玩牌手中各种牌的数量.ai表示数字为i的 ...
- 《团队名称》第八次团队作业:Alpha冲刺
项目 内容 这个作业属于哪个课程 任课教师博客主页链接 这个作业的要求在哪里 作业链接地址 团队名称 代码敲不队 作业学习目标 (1)掌握软件测试基础技术(2)学习迭代式增量软件开发过程(Scrum) ...
- 阿里云 LAMP 使用基础
产品亮点 1.基于阿里云CentOS7.2镜像 2.采用yum方式安装,软件安装均为默认目录,未作任何修改. 3.采用经典LAMP组合,拓展性强,资源丰富,解决方案较多 4.附带PhpMyadmin和 ...
- jQuery源码分析 开篇(一)
解读一个开源框架,最终目的当然就是学习程序的设计思想和实现技巧. JavaScript宗旨就是Write Less, Do More,简洁的API,优雅的链式,强大的查询与便捷的操作都是我们喜欢他的原 ...
- 嵌入式linux实现NAT端口映射
场景: 1.嵌入式linux系统内已经在2个网卡,分别为eth0(内网物理网卡,ip地址:192.168.1.4)以及ppp1(VPN客户端通过PPTP协议拨号生成的虚拟网卡,ip地址:192.168 ...
- 通过Sqoop实现Mysql / Oracle 与HDFS / Hbase互导数据
通过Sqoop实现Mysql / Oracle 与HDFS / Hbase互导数据\ 下文将重点说明通过Sqoop实现Mysql与HDFS互导数据,Mysql与Hbase,Oracle与Hbase的互 ...
- BA-WG-冷源
冷源群控系统最好由冷源厂家来做的理由 1.冷机厂家对空调的参数十分的清楚,明确的知道冷机的负荷曲线,可以优化冷机加减载的最合理时间达到最佳的节能效果 2.独立的CSM硬件模块,内置不同冷机的型号特性, ...
- tcpip学习
http://www.cnblogs.com/ggjucheng/archive/2012/08/18/2645324.html
- jQuery Mobile中$.mobile.buttonMarkup方法使用具体解释
近期在群里遇到多数网友提到$.mobile.buttonMarkup()方法的使用. 我这里就列了一下api的使用说明,以后大家看博客就能解决这个问题.如有不对的地方,请留言指出! jQuery Mo ...