Spark Stage 的划分
Spark作业调度
对RDD的操作分为transformation和action两类,真正的作业提交运行发生在action之后,调用action之后会将对原始输入数据的所有transformation操作封装成作业并向集群提交运行。这个过程大致可以如下描述:
- 由DAGScheduler对RDD之间的依赖性进行分析,通过DAG来分析各个RDD之间的转换依赖关系
- 根据DAGScheduler分析得到的RDD依赖关系将Job划分成多个stage
- 每个stage会生成一个TaskSet并提交给TaskScheduler,调度权转交给TaskScheduler,由它来负责分发task到worker执行
接下来,理解 Spark 中RDD的依赖关系.
RDD依赖关系
Spark中RDD的粗粒度操作,每一次transformation都会生成一个新的RDD,这样就会建立RDD之间的前后依赖关系,在Spark中,依赖关系被定义为两种类型,分别是窄依赖和宽依赖
- 窄依赖,父RDD的分区最多只会被子RDD的一个分区使用,
- 宽依赖,父RDD的一个分区会被子RDD的多个分区使用(宽依赖指子RDD的每个分区都要依赖于父RDD的所有分区,这是shuffle类操作)
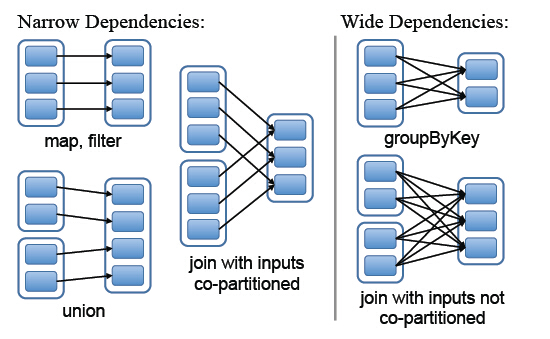
图中左边都是窄依赖关系,可以看出分区是1对1的。右边为宽依赖关系,有分区是1对多。(map,filter,union属于第一类窄依赖)
stage的划分
stage的划分是Spark作业调度的关键一步,它基于DAG确定依赖关系,借此来划分stage,将依赖链断开,每个stage内部可以并行运行,整个作业按照stage顺序依次执行,最终完成整个Job。实际应用提交的Job中RDD依赖关系是十分复杂的,依据这些依赖关系来划分stage自然是十分困难的,Spark此时就利用了前文提到的依赖关系,调度器从DAG图末端出发,逆向遍历整个依赖关系链,遇到ShuffleDependency(宽依赖关系的一种叫法)就断开,遇到NarrowDependency就将其加入到当前stage。stage中task数目由stage末端的RDD分区个数来决定,RDD转换是基于分区的一种粗粒度计算,一个stage执行的结果就是这几个分区构成的RDD。
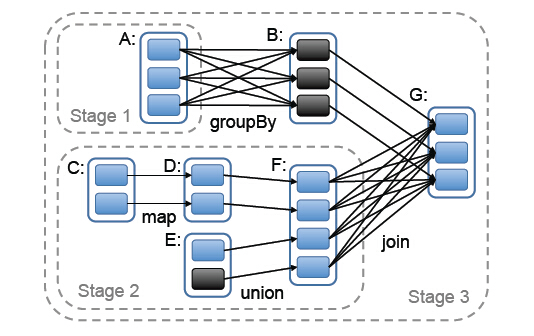
图中可以看出,在宽依赖关系处就会断开依赖链,划分stage,这里的stage1不需要计算,只需要计算stage2和stage3,就可以完成整个Job。
总结:遇到一个宽依赖就分一个stage
参考博客:https://blog.csdn.net/mahuacai/article/details/51919615
Spark Stage 的划分的更多相关文章
- 【Spark篇】--Spark中的宽窄依赖和Stage的划分
一.前述 RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖. Spark中的Stage其实就是一组并行的任务,任务是一个个的task . 二.具体细节 窄依赖 父RDD和子RDD parti ...
- 用实例说明Spark stage划分原理
注意:此文的stage划分有错,stage的划分是以shuffle操作作为边界的,可以参考<spark大数据处理技术>第四章page rank例子! 参考:http://litaotao. ...
- spark 源码分析之十九 -- DAG的生成和Stage的划分
上篇文章 spark 源码分析之十八 -- Spark存储体系剖析 重点剖析了 Spark的存储体系.从本篇文章开始,剖析Spark作业的调度和计算体系. 在说DAG之前,先简单说一下RDD. 对RD ...
- 021 RDD的依赖关系,以及造成的stage的划分
一:RDD的依赖关系 1.在代码中观察 val data = Array(1, 2, 3, 4, 5) val distData = sc.parallelize(data) val resultRD ...
- stage的划分
stage的划分是以shuffle操作作为边界的,遇到一个宽依赖就分一个stage 一个Job会被拆分为多组Task,每组任务被称为一个Stage就像Map Stage, Reduce Stage.S ...
- 窄依赖与宽依赖&stage的划分依据
RDD根据对父RDD的依赖关系,可分为窄依赖与宽依赖2种. 主要的区分之处在于父RDD的分区被多少个子RDD分区所依赖,如果一个就为窄依赖,多个则为宽依赖.更好的定义应该是: 窄依赖的定义是子RDD的 ...
- Spark 宽窄依赖和stage的划分
窄依赖 父RDD和子RDD partition之间的关系是一对一的,或者父RDD一个partition只对应一个子RDD的partition情况下的父RDD和子RDD partition关系是多对一的 ...
- Spark Stage切分 源码剖析——DAGScheduler
Spark中的任务管理是很重要的内容,可以说想要理解Spark的计算流程,就必须对它的任务的切分有一定的了解.不然你就看不懂Spark UI,看不懂Spark UI就无法去做优化...因此本篇就从源码 ...
- spark的知识的链接
IDEA 创建scala spark的Mvn项目:https://blog.csdn.net/u014646662/article/details/84618032 Spark详解03Job 物理执行 ...
随机推荐
- linux rtl8188eu ap模式 密码错误 disassoc reason code(8)
2018-05-30 14:12:46 于深圳南山科技园 最近有个项目,客户需要通过手机app通过机器wifi热点连接,从而实现对机器的设置及视频的实时预览等各种功能.这两天一直在搞rtl8188eu ...
- Python 模块 itertools
python 2.6 引入了itertools模块,使得排列组合的实现非常简单: import itertools 有序排列:e.g., 4个数内选2个排列: >>> print l ...
- hdu 2830 Matrix Swapping II(额,,排序?)
题意: N*M的矩阵,每个格中不是0就是1. 可以任意交换某两列.最后得到一个新矩阵. 问可以得到的最大的子矩形面积是多少(这个子矩形必须全是1). 思路: 先统计,a[i][j]记录从第i行第j列格 ...
- python解释器的下载与安装
python解释器 1. 什么是python解释器 用一种能让电脑听的懂得语言,使得电脑可以听从人们的指令去进行工作(翻译官) Python解释器本身也是个程序, 它是解释执行Python代码的,所以 ...
- 远程设备管理opendx平台搭建-server,agent以及front实际搭建
本系列文章讲述的是一个系列的第二部分,最终可以搭建一整套设备远程管理平台,与stf不同的是,opendx搭建较为简单,而且由于底层是appium来支持的,所以,较容易支持ios,也容易支持更高版本的安 ...
- OSI模型 & TCP/IP模型
分层思想 分层思想:将复杂 的流程分解 为几个功能相对单一 的子过程 整个流程更加清晰 ,复杂问题简单化 更容易发现问题并针对性的解决问题 分层思想在网络中的应用 OSI模型 国际标准化组织(Inte ...
- docker file 笔记
FROM # FROM scratch, FROM centos, FROM ubuntu:latest LABEL RUN # 每运行一次RUN,image都会生成新的一层,为了美观,避免 ...
- java注解@Transactional事务类内调用不生效问题及解决办法
@Transactional 内部调用例子 在 Spring 的 AOP 代理下,只有目标方法由外部调用,目标方法才由 Spring 生成的代理对象来管理,这会造成自调用问题.若同一类中的其他没有@T ...
- not noly go —— 运行轨迹[一]
前言 学习一下go 语言,也不完全是go,几乎是所以语言通用的部分,主要在于巩固一下基础,几乎不会涉及到语法相关的东西. 正文 前置内容 说起语言,很多人喜欢谈论解释型语言和编译型语言,其实对语言谈论 ...
- 使用Token进行CSRF漏洞防御
1.登录验证成功之后,在会话SESSION["user_token"]中保存Token. 2.在后台操作中,增删改表单中添加隐藏域hidden,设置value为Token. 3.提 ...