Spark Stage 的划分
Spark作业调度
对RDD的操作分为transformation和action两类,真正的作业提交运行发生在action之后,调用action之后会将对原始输入数据的所有transformation操作封装成作业并向集群提交运行。这个过程大致可以如下描述:
- 由DAGScheduler对RDD之间的依赖性进行分析,通过DAG来分析各个RDD之间的转换依赖关系
- 根据DAGScheduler分析得到的RDD依赖关系将Job划分成多个stage
- 每个stage会生成一个TaskSet并提交给TaskScheduler,调度权转交给TaskScheduler,由它来负责分发task到worker执行
接下来,理解 Spark 中RDD的依赖关系.
RDD依赖关系
Spark中RDD的粗粒度操作,每一次transformation都会生成一个新的RDD,这样就会建立RDD之间的前后依赖关系,在Spark中,依赖关系被定义为两种类型,分别是窄依赖和宽依赖
- 窄依赖,父RDD的分区最多只会被子RDD的一个分区使用,
- 宽依赖,父RDD的一个分区会被子RDD的多个分区使用(宽依赖指子RDD的每个分区都要依赖于父RDD的所有分区,这是shuffle类操作)
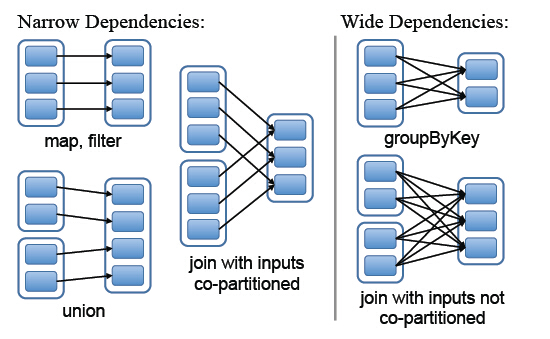
图中左边都是窄依赖关系,可以看出分区是1对1的。右边为宽依赖关系,有分区是1对多。(map,filter,union属于第一类窄依赖)
stage的划分
stage的划分是Spark作业调度的关键一步,它基于DAG确定依赖关系,借此来划分stage,将依赖链断开,每个stage内部可以并行运行,整个作业按照stage顺序依次执行,最终完成整个Job。实际应用提交的Job中RDD依赖关系是十分复杂的,依据这些依赖关系来划分stage自然是十分困难的,Spark此时就利用了前文提到的依赖关系,调度器从DAG图末端出发,逆向遍历整个依赖关系链,遇到ShuffleDependency(宽依赖关系的一种叫法)就断开,遇到NarrowDependency就将其加入到当前stage。stage中task数目由stage末端的RDD分区个数来决定,RDD转换是基于分区的一种粗粒度计算,一个stage执行的结果就是这几个分区构成的RDD。
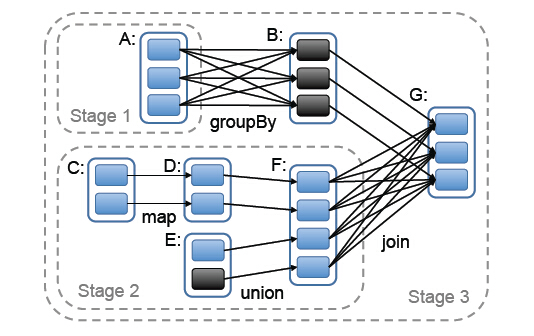
图中可以看出,在宽依赖关系处就会断开依赖链,划分stage,这里的stage1不需要计算,只需要计算stage2和stage3,就可以完成整个Job。
总结:遇到一个宽依赖就分一个stage
参考博客:https://blog.csdn.net/mahuacai/article/details/51919615
Spark Stage 的划分的更多相关文章
- 【Spark篇】--Spark中的宽窄依赖和Stage的划分
一.前述 RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖. Spark中的Stage其实就是一组并行的任务,任务是一个个的task . 二.具体细节 窄依赖 父RDD和子RDD parti ...
- 用实例说明Spark stage划分原理
注意:此文的stage划分有错,stage的划分是以shuffle操作作为边界的,可以参考<spark大数据处理技术>第四章page rank例子! 参考:http://litaotao. ...
- spark 源码分析之十九 -- DAG的生成和Stage的划分
上篇文章 spark 源码分析之十八 -- Spark存储体系剖析 重点剖析了 Spark的存储体系.从本篇文章开始,剖析Spark作业的调度和计算体系. 在说DAG之前,先简单说一下RDD. 对RD ...
- 021 RDD的依赖关系,以及造成的stage的划分
一:RDD的依赖关系 1.在代码中观察 val data = Array(1, 2, 3, 4, 5) val distData = sc.parallelize(data) val resultRD ...
- stage的划分
stage的划分是以shuffle操作作为边界的,遇到一个宽依赖就分一个stage 一个Job会被拆分为多组Task,每组任务被称为一个Stage就像Map Stage, Reduce Stage.S ...
- 窄依赖与宽依赖&stage的划分依据
RDD根据对父RDD的依赖关系,可分为窄依赖与宽依赖2种. 主要的区分之处在于父RDD的分区被多少个子RDD分区所依赖,如果一个就为窄依赖,多个则为宽依赖.更好的定义应该是: 窄依赖的定义是子RDD的 ...
- Spark 宽窄依赖和stage的划分
窄依赖 父RDD和子RDD partition之间的关系是一对一的,或者父RDD一个partition只对应一个子RDD的partition情况下的父RDD和子RDD partition关系是多对一的 ...
- Spark Stage切分 源码剖析——DAGScheduler
Spark中的任务管理是很重要的内容,可以说想要理解Spark的计算流程,就必须对它的任务的切分有一定的了解.不然你就看不懂Spark UI,看不懂Spark UI就无法去做优化...因此本篇就从源码 ...
- spark的知识的链接
IDEA 创建scala spark的Mvn项目:https://blog.csdn.net/u014646662/article/details/84618032 Spark详解03Job 物理执行 ...
随机推荐
- Luogu P4390 [BOI2007]Mokia 摩基亚 | CDQ分治
题目链接 $CDQ$分治. 考虑此时在区间$[l,r]$中,要计算$[l,mid]$中的操作对$[mid+1,r]$中的询问的影响. 计算时,排序加上树状数组即可. 然后再递归处理$[l,mid]$和 ...
- hdu 1083 Courses(二分图最大匹配)
题意: P门课,N个学生. (1<=P<=100 1<=N<=300) 每门课有若干个学生可以成为这门课的代表(即候选人). 又规定每个学生最多只能成为一门课的代 ...
- ONVIF客户端中预置位设置代码实现过程
simpleOnvif的功能:提供支持Windows.Linux.arm.Android.iOS等各种平台的SDK库,方便集成,二次开发 之前跟大家分享了我们安徽思蔷信息科技的simpleOnvif的 ...
- Linux wget 命令 使用总结
简介 wget命令用来从指定的URL下载文件.wget非常稳定,它在带宽很窄的情况下和不稳定网络中有很强的适应性,如果是由于网络的原因下载失败,wget会不断的尝试,直到整个文件下载完毕.如果是服务器 ...
- 设置IDEA启动,不要自动打开上次使用时的项目
打开idea时自动加载最近编辑的项目,很费时间,关闭设置如下
- docker容器运行java后台程序,存到数据库的时间差一天的问题
主要原因是docker容器中的时间用的是标准时间,不是用的宿主机的时间. 修改方法: docker run -e TZ="Asia/Shanghai" -d -p 80:80 -- ...
- yum install hadoop related client
yum list avaliable hadoop\* yum list installed yum repolist repo is in /etc/yum.repos.d yum install ...
- Python 流程控制-分支结构详解
目录 Python 流程控制--分支结构 1.结构分类 顺序结构 分支结构 循环结构 2.分支结构详解 分支结构 定义格式: if 单支结构 if 双分支结构 if 多分支结构 Python 流程控制 ...
- WPF仿Tabcontrol加载切换多个不同View
在同一块区域显示不同的视图内容,直接使用Tabcontrol,可能要重写TabItem的控件模板,最直接的方法通过按钮的切换,控制一个ContentControl的Content值,实现切换不同的视图 ...
- [atAGC020E]Encoding Subsets
令$f_{S}$表示字符串$S$的答案(所有子集的方案数之和),考虑转移: 1.最后是一个字符串,不妨仅考虑最后一个字符,即$f_{S[1,|S|)}$(字符串下标从1开始),特别的,若$S_{|S| ...