为什么使用 LSTM 训练速度远大于 SimpleRNN?
今天试验 TensorFlow 2.x , Keras 的 SimpleRNN 和 LSTM,发现同样的输入、同样的超参数设置、同样的参数规模,LSTM 的训练时长竟然远少于 SimpleRNN。
模型定义:
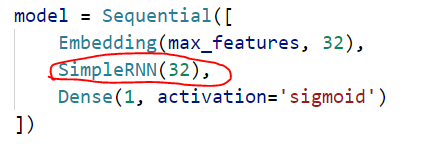
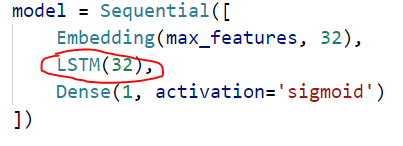
训练参数都这样传入:

我们知道,LSTM 是修正了的 SimpleRNN(我随意想出来的词,“修正”),或者说,是在 SimpleRNN 基础之上又添加了别的措施使模型能考虑到超长序列的标记之间的依赖。 缓解了梯度消失和梯度爆炸的问题。
所以,LSTM 比 SimpleRNN 是多了很多参数矩阵的,且每一步也多了一些计算。而训练过程既有前向,又有反向,不管哪个过程,理论上 LSTM都是比SimpleRNN要花更多时间的,那么为什么我在使用 TensorFlow with Keras 时会出现相反的情况呢?
训练情况(第一个 epoch):
SimpleRNN 的

LSTM的

原因,就在于:版本。
按住 Ctrl,点击两个类名 SimpleRNN 和 LSTM,进入定义的模块,会发现 from tensorflow.keras.layers import SimpleRNN 的 SimpleRNN定义所在的模块分别是这样的
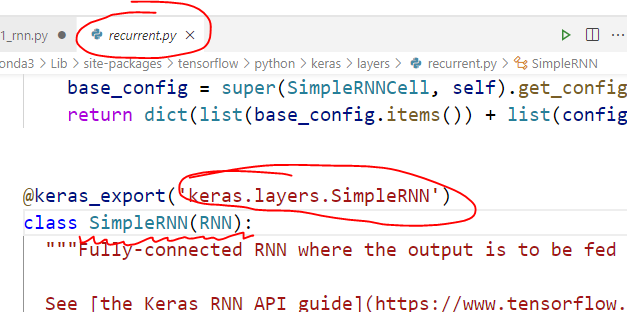
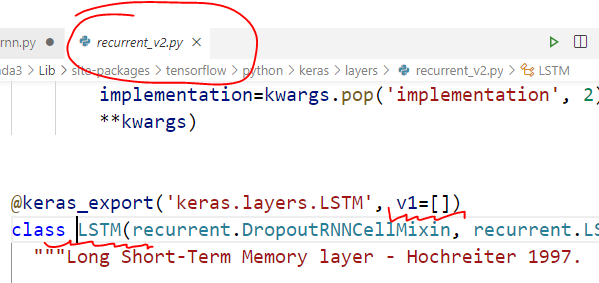
懂了,SimpleRNN 是 TensorFlow 1.xx 的东西,而这个 LSTM 是 TensorFlow 2.xx 的东西,肯定内部做了优化,反正二者一开始就不是一个起跑线上的东西。虽然我们写代码表面上都是from tensorflow.kears.layers 里 import 的,但是这种模块导入真的不能证明他们是放在同一个模块里定义的,因为导入是可以导来导去的,有的一个 import 就找到了它的定义,有的需要经过好几次 import 的传递,就像是个链,从我们的源文件一直到达最终定义的模块,这个 LSTM 隐藏的就很深(或者封装的很好(皮))。
要找到 这个 SimpleRNN 的 counterpart,就须使用 tensorflow.compat.v1.keras.layers.LSTM,找到它,发现
这就与上述 SimpleRNN 所在同一个模块了。
试验训练一下。

果然,比 SimpleRNN 慢得多,合理了。舒服了。
-------------------------------------------
我发现我真的好无聊,整天搞这些没用的。
抓主要矛盾,抓主要矛盾,主要矛盾!!!
下次一定 :)
为什么使用 LSTM 训练速度远大于 SimpleRNN?的更多相关文章
- 进程物理内存远大于Xmx的问题分析
问题描述 最近经常被问到一个问题,”为什么我们系统进程占用的物理内存(Res/Rss)会远远大于设置的Xmx值”,比如Xmx设置1.7G,但是top看到的Res的值却达到了3.0G,随着进程的运行,R ...
- [转载]Java进程物理内存远大于Xmx的问题分析
进程物理内存远大于Xmx的问题分析 问题描述 最近经常被问到一个问题,”为什么我们系统进程占用的物理内存(Res/Rss)会远远大于设置的Xmx值”,比如Xmx设置1.7G,但是top看到的Res的值 ...
- iGear 用了这个小魔法,模型训练速度提升 300%
一个高精度AI模型离不开大量的优质数据集,这些数据集往往由标注结果文件和海量的图片组成.在数据量比较大的情况下,模型训练周期也会相应加长.那么有什么加快训练速度的好方法呢? 壕气的老板第一时间想到的通 ...
- 实例演示 C# 中 Dictionary<Key, Value> 的检索速度远远大于 hobbyList.Where(c => c.UserId == user.Id)
前言 我们知道,有时候在一些项目中,为了性能,往往会一次性加载很多条记录来进行循环处理(备注:而非列表呈现).比如:从数据库中加载 10000 个用户,并且每个用户包含了 20 个“爱好”,在 Wi ...
- C++,1....n中随机等概率的输出m个不重复的数(假设n远大于m)。
#include <stdlib.h> #include <time.h> knuth(int n, int m) { srand((unsigned )); ; i < ...
- 高性能网络编程(一)----accept建立连接
编写服务器时,许多程序员习惯于使用高层次的组件.中间件(例如OO(面向对象)层层封装过的开源组件),相比于服务器的运行效率而言,他们更关注程序开发的效率,追求更快的完成项目功能点.希望应用代码完全不关 ...
- Linux Cache Mechanism Summary(undone)
目录 . 缓存机制简介 . 内核缓存机制 . 内存缓存机制 . 文件缓存机制 . 数据库缓存机制 1. 缓存机制简介 0x1: 什么是缓存cache 在计算机整个领域中,缓存(cache)这个词是一个 ...
- D. Powerful array 莫队算法或者说块状数组 其实都是有点优化的暴力
莫队算法就是优化的暴力算法.莫队算法是要把询问先按左端点属于的块排序,再按右端点排序.只是预先知道了所有的询问.可以合理的组织计算每个询问的顺序以此来降低复杂度. D. Powerful array ...
- 高性能网络编程1----accept建立连接
转 http://taohui.org.cn/tcpperf1.html 陶辉 taohui.org.cn 回到应用层,往往只需要调用类似于accept的API就可以建立TCP连接.建立连接的流程大 ...
随机推荐
- MySQL是如何实现事物隔离?
前言 众所周知,MySQL的在RR隔离级别下查询数据,是可以保证数据不受其它事物影响,而在RC隔离级别下只要其它事物commit后,数据都会读到commit之后的数据,那么事物隔离的原理是什么?是通过 ...
- 通过git将项目传到github上
lenovo@LAPTOP-3KMEN0B2 MINGW64 /e/Users/lenovo/springboot-project/forum $ ls forum.iml HELP.md mvnw* ...
- 初遇SpringBoot踩坑与加载静态文件遇到的坑
SpringBoot开发 创建SpringBoot项目 大家都知道SpringBoot开发非常快,创建SpringBoot项目时,勾上SpringW ...
- 项目记事【Git】:git pull 出错 error: cannot lock ref 'refs/remotes/origin/feature/hy78861': is at d4244546c8cc3827491cc82878a23c708fd0401d but expected a6a00bf2e92620d0e06790122bab5aeee01079bf
今天 pull 代码的时候碰到以下问题(隐去了一些公司敏感信息): XXX@CN-00012645 MINGW64 /c/Gerrard/Workspace/XXX (master) $ git pu ...
- 摄像头ISP系统原理(下)
摄像头ISP系统原理(下) l WDR(Wide Dynamic Range)------宽动态 动态范围(Dynamic Range)是指摄像机支持的最大输出信号和最小输出信号的比值,或者说图像最 ...
- EasyExcel 框架使用-读
EasyExcel 框架使用 官方介绍:JAVA解析Excel工具EasyExcel Java解析.生成Excel比较有名的框架有Apache poi.jxl.但他们都存在一个严重的问题就是非常的耗内 ...
- 开发掉坑(二)前端静态资源 Uncaught SyntaxError: Unexpected token <
某天,有同学反馈后台管理系统出现静态资源无法加载的问题. 复现如下: 进入首页. 点击侧边栏某个子功能,静态资源可正常访问到. 等待10分钟左右,点击侧边栏其他子功能,无法访问到静态资源. 查看控制台 ...
- springboot2.x整合tkmapper
springboot整合tkmapper 1.导入pom依赖 1.1 导入springboot的parent依赖 <parent> <artifactId>spring-boo ...
- xxl-job执行器的注册
一.执行器注册流程 二.具体流程 1.注册监控线程 //类:JobRegistryHelper.java:方法:public void start() registryMonitorThread = ...
- OOP第三次总结Blog
1. 前言 相比于前一次Blog题目集,此次七八九题目集偏重于类的继承.多态性使用方法以及接口的应用;在设计层面,强调模式复用,不断的迭代,若前期设计不合理,则后续的题目增加新的功能(即可扩展性)将会 ...