为什么使用 LSTM 训练速度远大于 SimpleRNN?
今天试验 TensorFlow 2.x , Keras 的 SimpleRNN 和 LSTM,发现同样的输入、同样的超参数设置、同样的参数规模,LSTM 的训练时长竟然远少于 SimpleRNN。
模型定义:
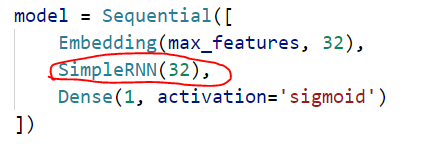
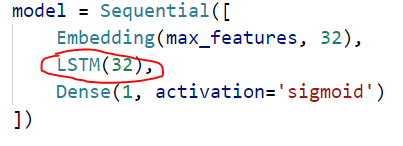
训练参数都这样传入:

我们知道,LSTM 是修正了的 SimpleRNN(我随意想出来的词,“修正”),或者说,是在 SimpleRNN 基础之上又添加了别的措施使模型能考虑到超长序列的标记之间的依赖。 缓解了梯度消失和梯度爆炸的问题。
所以,LSTM 比 SimpleRNN 是多了很多参数矩阵的,且每一步也多了一些计算。而训练过程既有前向,又有反向,不管哪个过程,理论上 LSTM都是比SimpleRNN要花更多时间的,那么为什么我在使用 TensorFlow with Keras 时会出现相反的情况呢?
训练情况(第一个 epoch):
SimpleRNN 的

LSTM的

原因,就在于:版本。
按住 Ctrl,点击两个类名 SimpleRNN 和 LSTM,进入定义的模块,会发现 from tensorflow.keras.layers import SimpleRNN 的 SimpleRNN定义所在的模块分别是这样的
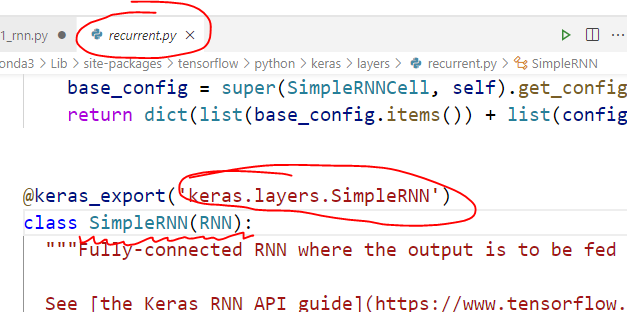
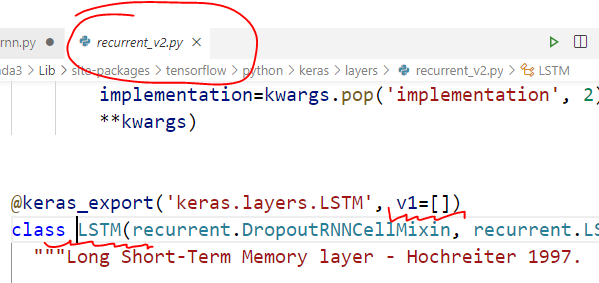
懂了,SimpleRNN 是 TensorFlow 1.xx 的东西,而这个 LSTM 是 TensorFlow 2.xx 的东西,肯定内部做了优化,反正二者一开始就不是一个起跑线上的东西。虽然我们写代码表面上都是from tensorflow.kears.layers 里 import 的,但是这种模块导入真的不能证明他们是放在同一个模块里定义的,因为导入是可以导来导去的,有的一个 import 就找到了它的定义,有的需要经过好几次 import 的传递,就像是个链,从我们的源文件一直到达最终定义的模块,这个 LSTM 隐藏的就很深(或者封装的很好(皮))。
要找到 这个 SimpleRNN 的 counterpart,就须使用 tensorflow.compat.v1.keras.layers.LSTM,找到它,发现
这就与上述 SimpleRNN 所在同一个模块了。
试验训练一下。

果然,比 SimpleRNN 慢得多,合理了。舒服了。
-------------------------------------------
我发现我真的好无聊,整天搞这些没用的。
抓主要矛盾,抓主要矛盾,主要矛盾!!!
下次一定 :)
为什么使用 LSTM 训练速度远大于 SimpleRNN?的更多相关文章
- 进程物理内存远大于Xmx的问题分析
问题描述 最近经常被问到一个问题,”为什么我们系统进程占用的物理内存(Res/Rss)会远远大于设置的Xmx值”,比如Xmx设置1.7G,但是top看到的Res的值却达到了3.0G,随着进程的运行,R ...
- [转载]Java进程物理内存远大于Xmx的问题分析
进程物理内存远大于Xmx的问题分析 问题描述 最近经常被问到一个问题,”为什么我们系统进程占用的物理内存(Res/Rss)会远远大于设置的Xmx值”,比如Xmx设置1.7G,但是top看到的Res的值 ...
- iGear 用了这个小魔法,模型训练速度提升 300%
一个高精度AI模型离不开大量的优质数据集,这些数据集往往由标注结果文件和海量的图片组成.在数据量比较大的情况下,模型训练周期也会相应加长.那么有什么加快训练速度的好方法呢? 壕气的老板第一时间想到的通 ...
- 实例演示 C# 中 Dictionary<Key, Value> 的检索速度远远大于 hobbyList.Where(c => c.UserId == user.Id)
前言 我们知道,有时候在一些项目中,为了性能,往往会一次性加载很多条记录来进行循环处理(备注:而非列表呈现).比如:从数据库中加载 10000 个用户,并且每个用户包含了 20 个“爱好”,在 Wi ...
- C++,1....n中随机等概率的输出m个不重复的数(假设n远大于m)。
#include <stdlib.h> #include <time.h> knuth(int n, int m) { srand((unsigned )); ; i < ...
- 高性能网络编程(一)----accept建立连接
编写服务器时,许多程序员习惯于使用高层次的组件.中间件(例如OO(面向对象)层层封装过的开源组件),相比于服务器的运行效率而言,他们更关注程序开发的效率,追求更快的完成项目功能点.希望应用代码完全不关 ...
- Linux Cache Mechanism Summary(undone)
目录 . 缓存机制简介 . 内核缓存机制 . 内存缓存机制 . 文件缓存机制 . 数据库缓存机制 1. 缓存机制简介 0x1: 什么是缓存cache 在计算机整个领域中,缓存(cache)这个词是一个 ...
- D. Powerful array 莫队算法或者说块状数组 其实都是有点优化的暴力
莫队算法就是优化的暴力算法.莫队算法是要把询问先按左端点属于的块排序,再按右端点排序.只是预先知道了所有的询问.可以合理的组织计算每个询问的顺序以此来降低复杂度. D. Powerful array ...
- 高性能网络编程1----accept建立连接
转 http://taohui.org.cn/tcpperf1.html 陶辉 taohui.org.cn 回到应用层,往往只需要调用类似于accept的API就可以建立TCP连接.建立连接的流程大 ...
随机推荐
- linux 安装配置NFS服务器
一.Ubuntu安装配置NFS 1.安装NFS服务器 sudo apt-get install nfs-kernel-server 安装nfs-kernel-server时,apt会自动安装nfs-c ...
- 浅析IOC 和 DI
学习过spring框架的人一定都会听过Spring的IoC(控制反转) .DI(依赖注入)这两个概念,对于初学Spring的人来说,总觉得IoC .DI这两个概念是模糊不清的,是很难理解的,今天和大家 ...
- Jmeter- 笔记6 - 负载测试
普通场景介绍 1.线程数:并发用户数 2.Ramp-Up时间:启动时间(线程数的准备时间),在这个时间点结束时,所有用户都已运行起来 3.循环次数:每个线程数都要运行的次数.永远 和 调度器一起使用, ...
- Jmeter- 笔记2 - Jmeter介绍
性能测试工具:Jmeter 环境:Window,jdk1.8 Jmeter是Apache下的Java语言开发.运行Java语言的环境是jre(Java run env.).jdk是Java开发工具包, ...
- C++ 扩展 Op
C++ 扩展 Op 本文将介绍如何使用 C++ 扩展 Op,与用 Python 扩展 Op 相比,使用 C++ 扩展 Op,更加灵活.可配置的选项更多,且支持使用 GPU 作为计算设备.一般可使用 P ...
- Python爬虫入门:Urllib parse库使用详解(二)
文字转载:https://www.jianshu.com/p/e4a9e64082ef,转载内容仅供学习 如有侵权,请联系删除 获取url参数 urlparse 和 parse_qs ParseRes ...
- redis常用命令练习
redis-server redis-cli select 0-15 redis key: string\hash\list\set\sortedset 1.增删改查... keys * 所有key ...
- 牛客网sql实战参考答案(mysql版):1-15
1.查找最晚入职员工的所有信息,为了减轻入门难度,目前所有的数据里员工入职的日期都不是同一天(sqlite里面的注释为--,mysql为comment) CREATE TABLE `employees ...
- mybatis学习——使用注解开发
前言: 一个语句既可以通过 XML 定义,也可以通过注解定义.不过,由于 Java 注解的一些限制以及某些 MyBatis 映射的复杂性,要使用大多数高级映射(比如:嵌套联合映射),仍然需要使用 XM ...
- DHCP:IP 并非与生俱来
初识 DHCP 众所周知,因特网上的每台设备都规定了其全世界唯一的地址,也就是说 "IP 地址",正是由于有了 IP 地址,才保证了用户在连网的计算机上操作时,能够高效而且方便地从 ...