HCNA Routing&Switching之路由基础
在开始聊路由之前,我们首先要明白在网络通讯里,什么是路由?什么是路由表、路由器以及网关的相关术语;路由简单讲就是指网络数据包从源头到目标的路径,主要用来为不同网络间通讯提供数据包转发依据;路由表就是多条路由信息的集合,主要作用就是用来存储路由信息,以及为路由器提供路由的依据;路由器就是指具有路由功能和维护路由表的网络设备;所谓网关是指路由器上的接口ip地址(一台路由器一个接口对应一个广播域,所以路由器天生就是用来隔离广播域的);
路由器的工作原理
当路由器(或其他三层设备)收到一个ip数据包时,首先会查看该包的ip头部中的目标ip地址,并在路由表中进行查找和匹配,在匹配到最优路由后,将数据包扔给对应路由所指的出接口或下一跳,从而完成数据包的转发;当收到的ip数据包在路由表中没有匹配的路由时,路由器会自动丢弃对应的ip数据包;简单讲就是路由器收到报文,然后查找路由表,如果有对应匹配的路由,就把对应报文从对应路由所指定的出接口或下一条所在同网段ip地址所在接口发出去;如果没有匹配的路由信息则自动丢弃该数据报文;从上述描述我们不难理解,一个数据报文要想从路由器通过,必须满足对应路由器上要有匹配的路由;有了匹配的路由,对应路由器就知道把对应数据报文从那个接口转发出去;
ip路由过程
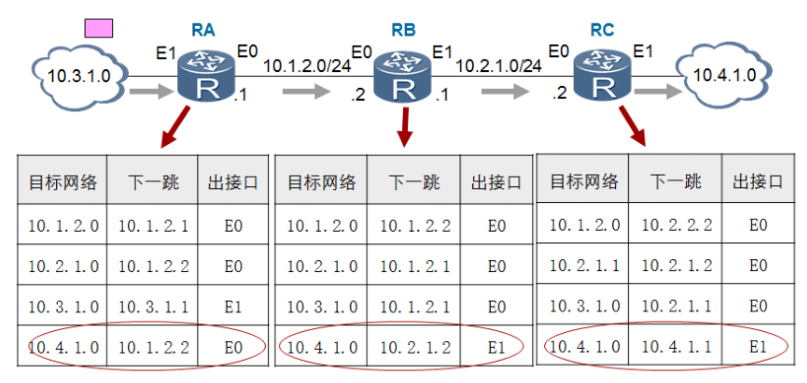
提示:当一个报文从10.3.1.0发出,首先会被RA收到,RA收到报文后,一看该报文是到10.4.1.0网络,然后就查看自己的路由表,看看有没有到达10.4.1.0路由;如果有就从对应路由所指定的出接口转发出去;如果没有就丢弃;同样的原理,当数据包从RA的E0口发送出去以后,对应与RA的E0口直连的RB的E0口就会收到对应的数据报文;当RB收到RA转发出来的报文以后,也会先看对应报文的目标网络,然后和自己的路由表中的路由进行匹配;匹配到就从对应的接口发出去;依次类推,最终数据包会到达RC,RC收到报文以后,查看路由表发现对应报文的目标网络是和自己E1口直连,然后RC会把对应报文从E1口发送出去;到此路由器的工作就完成了;后续就是通过目标ip地址,arp广播拿到对应目标ip地址mac,然后进行二层以太网封装,最终将数据报文送达到对应主机或设备的网卡上,由对应目标ip地址所在设备进行处理;
查看路由表
<Huawei>display ip routing-table
Route Flags: R - relay, D - download to fib
------------------------------------------------------------------------------
Routing Tables: Public
Destinations : 4 Routes : 4 Destination/Mask Proto Pre Cost Flags NextHop Interface 127.0.0.0/8 Direct 0 0 D 127.0.0.1 InLoopBack0
127.0.0.1/32 Direct 0 0 D 127.0.0.1 InLoopBack0
127.255.255.255/32 Direct 0 0 D 127.0.0.1 InLoopBack0
255.255.255.255/32 Direct 0 0 D 127.0.0.1 InLoopBack0 <Huawei>
提示:Destination/Mask字段用来描述目标网络和掩码;Proto用来描述路由的来源,常见的路由来源有Direct(直连),static(静态),ospf(动态路由学习中的一种),RIP等等;pre用来描述对应路由的优先级,如果有多条不同的路由到达相同目标网络,优先级越低对应路由就越优先匹配;cost是用来描述对应路由的开销,多条相同路由来源到达相同目标网络,开销越低,对应路由就越优先匹配;NextHop用来描述下一跳地址,所谓下一跳就是指ip报文所经由的下一个路由器的接口地址;interface用来描述出接口(ip报文从哪个接口转发出去);
路由器转发原则
1、被转发到路由必须存在(如果不存在该路由条目,路由器收到此类报文会直接丢弃不做任何处理);
2、根据最长匹配原则进行匹配,也就是掩码越长越优先转发;
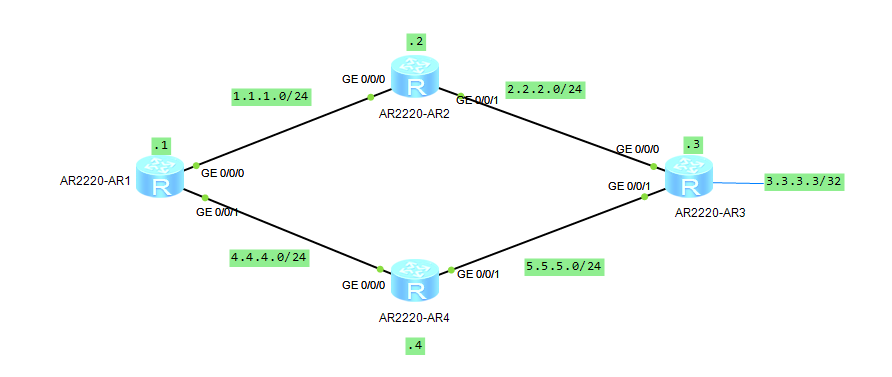
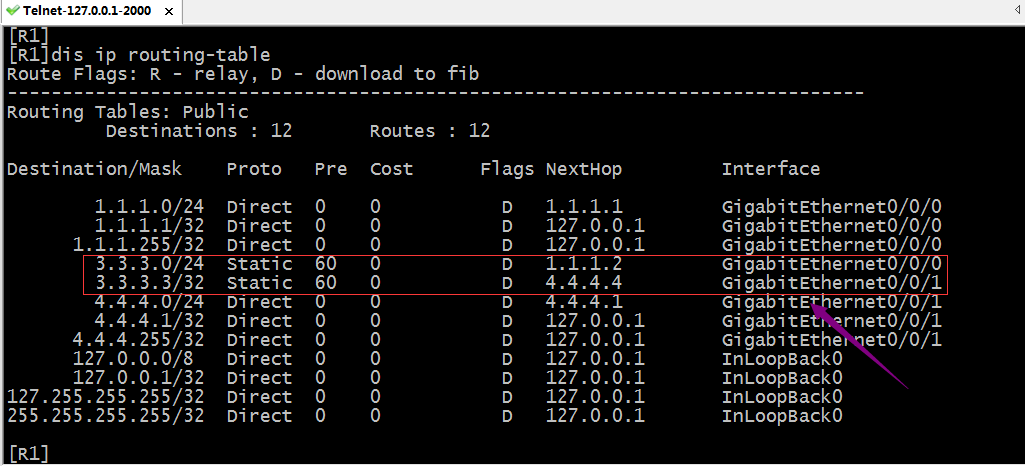
提示:如图所示,R1上有两条静态路由,分别都能到达3.3.3.3,其中一条是出接口为g0/0/0掩码为24,一条是g0/0/1掩码为32,现在我们看看数据报文到底会走哪一边呢?
验证:用tracert 3.3.3.3来查看对应数据包会走的那一条路?
[R1]tracert 3.3.3.3
traceroute to 3.3.3.3(3.3.3.3), max hops: 30 ,packet length: 40,press CTRL_C to break
1 4.4.4.4 30 ms 10 ms 10 ms
2 5.5.5.3 20 ms 30 ms 30 ms
[R1]
提示:可以看到当目标地址相同时,相同协议,优先级,开销的情况下掩码越长越优先匹配上;
3、当掩码长度一样,会比较优先级,优先级数字越小越优先转发;
示例:还是上述实验top,修改下静态路由,把g0/0/1上的优先级改调大一点,看看对应数据包是否还会选择下面的路呢?
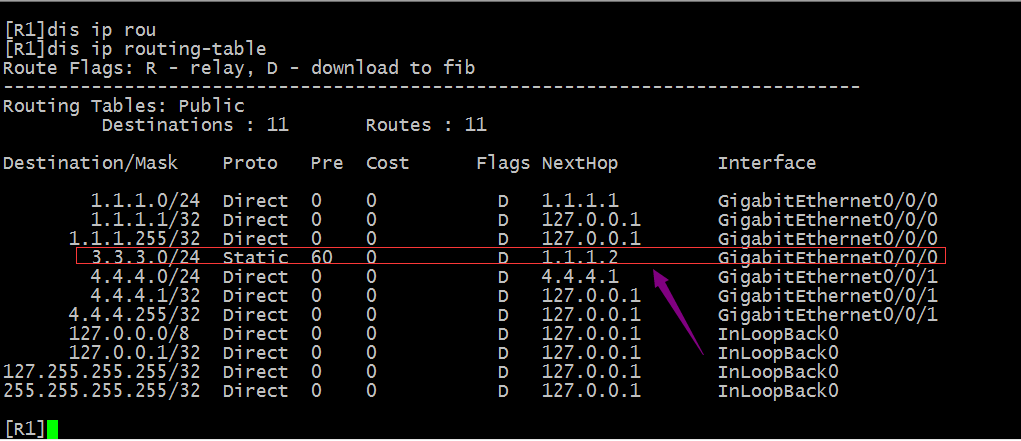
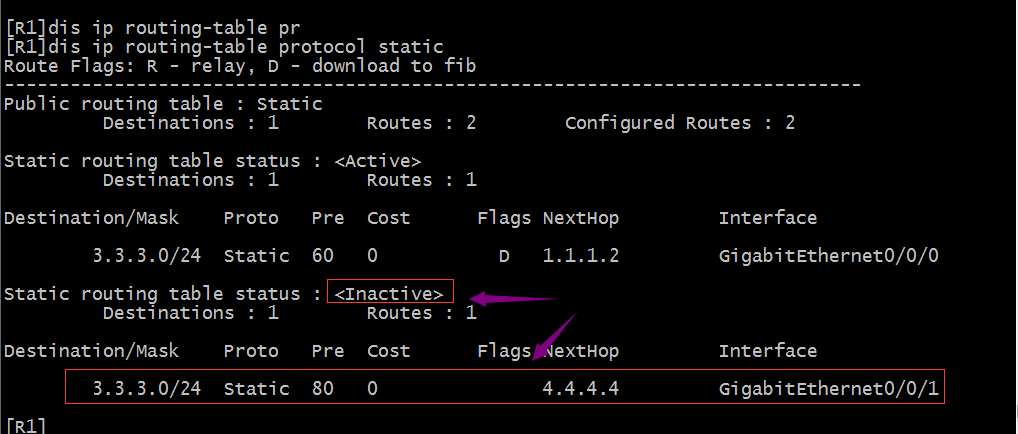
提示:当我们把原来的32位掩码路由删除以后,重新添加24为掩码的优先级为80的路由以后,对应路由表中反而就只有一条优先级为60的路路由;说明相同目标网络,相同掩码以及相同协议和开销的情况下,优先级越低的路由优先匹配(因为路由表中只存在最优路由);此时我们在R1上访问3.3.3.3时,数据报文会从g0/0/0发出,因为路由表中就只有一条路由;
验证:用R1 tracert 3.3.3.3,看看数据包是否走R2到达R3?
[R1]tracert 3.3.3.3
traceroute to 3.3.3.3(3.3.3.3), max hops: 30 ,packet length: 40,press CTRL_C to break
1 1.1.1.2 20 ms 20 ms 10 ms
2 2.2.2.3 30 ms 30 ms 30 ms
[R1]
提示:可以看到数据包走g0/0/0到达1.1.1.2,然后在到达R3的2.2.2.2;
常用路由协议默认优先级

4、当掩码和优先级一样,会比较开销(cost值),开销越小越优先转发;
示例:还是上述的top,全网运行ospf,然后修改g0/0/0上的开销为50,看看对应的路由表中会存放那条路由?
[R1]dis ip routing-table
Route Flags: R - relay, D - download to fib
------------------------------------------------------------------------------
Routing Tables: Public
Destinations : 13 Routes : 14 Destination/Mask Proto Pre Cost Flags NextHop Interface 1.1.1.0/24 Direct 0 0 D 1.1.1.1 GigabitEthernet0/0/0
1.1.1.1/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/0
1.1.1.255/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/0
2.2.2.0/24 OSPF 10 2 D 1.1.1.2 GigabitEthernet0/0/0
3.3.3.3/32 OSPF 10 2 D 4.4.4.4 GigabitEthernet0/0/1
OSPF 10 2 D 1.1.1.2 GigabitEthernet0/0/0
4.4.4.0/24 Direct 0 0 D 4.4.4.1 GigabitEthernet0/0/1
4.4.4.1/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/1
4.4.4.255/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/1
5.5.5.0/24 OSPF 10 2 D 4.4.4.4 GigabitEthernet0/0/1
127.0.0.0/8 Direct 0 0 D 127.0.0.1 InLoopBack0
127.0.0.1/32 Direct 0 0 D 127.0.0.1 InLoopBack0
127.255.255.255/32 Direct 0 0 D 127.0.0.1 InLoopBack0
255.255.255.255/32 Direct 0 0 D 127.0.0.1 InLoopBack0 [R1]int g0/0/0
[R1-GigabitEthernet0/0/0]ospf cost 50
[R1-GigabitEthernet0/0/0]q
[R1]dis ip routing-table
Route Flags: R - relay, D - download to fib
------------------------------------------------------------------------------
Routing Tables: Public
Destinations : 13 Routes : 13 Destination/Mask Proto Pre Cost Flags NextHop Interface 1.1.1.0/24 Direct 0 0 D 1.1.1.1 GigabitEthernet0/0/0
1.1.1.1/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/0
1.1.1.255/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/0
2.2.2.0/24 OSPF 10 3 D 4.4.4.4 GigabitEthernet0/0/1
3.3.3.3/32 OSPF 10 2 D 4.4.4.4 GigabitEthernet0/0/1
4.4.4.0/24 Direct 0 0 D 4.4.4.1 GigabitEthernet0/0/1
4.4.4.1/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/1
4.4.4.255/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/1
5.5.5.0/24 OSPF 10 2 D 4.4.4.4 GigabitEthernet0/0/1
127.0.0.0/8 Direct 0 0 D 127.0.0.1 InLoopBack0
127.0.0.1/32 Direct 0 0 D 127.0.0.1 InLoopBack0
127.255.255.255/32 Direct 0 0 D 127.0.0.1 InLoopBack0
255.255.255.255/32 Direct 0 0 D 127.0.0.1 InLoopBack0 [R1]
提示:可以看到在没有改g0/0/0接口开销时,在路由表中存在两条到达3.3.3.3的路由,而更改了g0/0/0接口开销以后,对应路由表中只有一条开销为2的路由;说明当去往同一目标ip地址时,掩码优先级一样时,开销越低越优先被匹配;
5、当掩码、优先级、开销都一样,则负载分担;
示例:还是上述top,我们把g0/0/0接口上的开销删除,看看对应路由会有什么变化?
[R1]dis ip routing-table
Route Flags: R - relay, D - download to fib
------------------------------------------------------------------------------
Routing Tables: Public
Destinations : 13 Routes : 13 Destination/Mask Proto Pre Cost Flags NextHop Interface 1.1.1.0/24 Direct 0 0 D 1.1.1.1 GigabitEthernet0/0/0
1.1.1.1/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/0
1.1.1.255/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/0
2.2.2.0/24 OSPF 10 3 D 4.4.4.4 GigabitEthernet0/0/1
3.3.3.3/32 OSPF 10 2 D 4.4.4.4 GigabitEthernet0/0/1
4.4.4.0/24 Direct 0 0 D 4.4.4.1 GigabitEthernet0/0/1
4.4.4.1/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/1
4.4.4.255/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/1
5.5.5.0/24 OSPF 10 2 D 4.4.4.4 GigabitEthernet0/0/1
127.0.0.0/8 Direct 0 0 D 127.0.0.1 InLoopBack0
127.0.0.1/32 Direct 0 0 D 127.0.0.1 InLoopBack0
127.255.255.255/32 Direct 0 0 D 127.0.0.1 InLoopBack0
255.255.255.255/32 Direct 0 0 D 127.0.0.1 InLoopBack0 [R1]int g0/0/0
[R1-GigabitEthernet0/0/0]d th
[V200R003C00]
#
interface GigabitEthernet0/0/0
ip address 1.1.1.1 255.255.255.0
ospf cost 50
#
return
[R1-GigabitEthernet0/0/0]undo ospf cos
[R1-GigabitEthernet0/0/0]undo ospf cost
[R1-GigabitEthernet0/0/0]d th
[V200R003C00]
#
interface GigabitEthernet0/0/0
ip address 1.1.1.1 255.255.255.0
#
return
[R1-GigabitEthernet0/0/0]q
[R1]dis ip routing-table
Route Flags: R - relay, D - download to fib
------------------------------------------------------------------------------
Routing Tables: Public
Destinations : 13 Routes : 14 Destination/Mask Proto Pre Cost Flags NextHop Interface 1.1.1.0/24 Direct 0 0 D 1.1.1.1 GigabitEthernet0/0/0
1.1.1.1/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/0
1.1.1.255/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/0
2.2.2.0/24 OSPF 10 2 D 1.1.1.2 GigabitEthernet0/0/0
3.3.3.3/32 OSPF 10 2 D 4.4.4.4 GigabitEthernet0/0/1
OSPF 10 2 D 1.1.1.2 GigabitEthernet0/0/0
4.4.4.0/24 Direct 0 0 D 4.4.4.1 GigabitEthernet0/0/1
4.4.4.1/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/1
4.4.4.255/32 Direct 0 0 D 127.0.0.1 GigabitEthernet0/0/1
5.5.5.0/24 OSPF 10 2 D 4.4.4.4 GigabitEthernet0/0/1
127.0.0.0/8 Direct 0 0 D 127.0.0.1 InLoopBack0
127.0.0.1/32 Direct 0 0 D 127.0.0.1 InLoopBack0
127.255.255.255/32 Direct 0 0 D 127.0.0.1 InLoopBack0
255.255.255.255/32 Direct 0 0 D 127.0.0.1 InLoopBack0 [R1]
提示:删除g0/0/0上的接口开销以后,对应路由表中就有两条去往3.3.3.3的路由,他们掩码优先级开销都一样,此时当r1收到一个去往3.3.3.3的报文后,有可能数据包走g0/0/0,也有可能走g0/0/1;
等价路由(ECMP, Equal Cost Multi-Path)
类似上一个示例,同一个路由来源,当达到同一个目标网络有几条相同度量值的路由时,这些路由都会被加入到路由表中, 数据包会在这几个链路上进行负载分担。所谓负载分担不是负载均衡,负载分担是指多条链路上都会有流量,不一定是平均分配的;而负载均衡是指多条链路上的流量是平均负载的;
路由表的形成以及路由的来源
路由表的形成就是一条条路由信息的集合,路由的来源主要由三个,第一个是直连路由,所谓直连路由是路由a连接路由B,中间没有任何设备,这个就叫做直连;直连路由的形成必须满足两个条件,首先对应直接接口都正确配置了地址,其次对应接口都接线了,并且接口物理状态是up状态,这两个条件必须同时满足,直连路就会生成;一般在模拟器上我们连好线,配置上地址,对应直连路由就会自动生成; 路由信息除了来自直连路由,还来自静态路由和动态路由;静态路由就是管理员人工手动添加到路由;动态路由是指路由器之间通过动态路由协议学习到的路由;常用的动态路由协议有rip,ospf,bgp,isis;
HCNA Routing&Switching之路由基础的更多相关文章
- HCNA Routing&Switching之STP基础
前文我们了解了VLAN动态注册协议GVRP相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/15113770.html:今天我们来讨论下二层环路和STP相 ...
- HCNA Routing&Switching之静态路由
前文我们聊到了路由的相关概念和路由基础方面的话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/14947897.html:今天我们聊聊静态路由相关话题: 回顾 ...
- HCNA Routing&Switching之OSPF度量值和基础配置命令总结
前文我们了解了OSPF的网络类型,OSPF中的DR和BDR的选举规则.作用等相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/15054938.html: ...
- HCNA Routing&Switching之动态路由基本概念
前文我们了解了静态路由的相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/14965433.html:今天我们来聊一聊动态路由相关概念: 首先我们要清楚什 ...
- HCNA Routing&Switching之动态路由协议OSPF基础(一)
前文我们了解了基于路径矢量算法的动态路由协议RIP防环以及度量值的修改相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/15012895.html:今天我 ...
- HCNA Routing&Switching之交换技术基础
什么是交换机?顾名思义,交换机就是用来数据包交换的:广泛用于终端接入:它的前身是hub(集线器),hub是一个古老的设备,它的作用也是用于终端接入,但hub有一个最大的缺点是它不能隔离冲突域:所谓冲突 ...
- HCNA Routing&Switching之VLAN间路由
前文我们了解了二层交换技术vlan相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/15091491.html:今天我们来聊一聊不同VLAN间通信相关话题 ...
- HCNA Routing&Switching之动态路由协议OSPF基础(二)
前文我们主要了解了OSPF的区域.区域分类.路由器类型.OSPF的核心工作流程,回顾请参考:https://www.cnblogs.com/qiuhom-1874/p/15025533.html:今天 ...
- HCNA Routing&Switching之二层交换技术VLAN基础
前文我们主要聊了下交换机的工作原理和以太网接口的速率和双工相关话题,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/15088183.html:今天我们主要来聊一 ...
随机推荐
- 技术干货 | 轻松两步完成向 mPaaS 小程序传递启动参数
前言 在部分场景下,需要向小程序的默认接收页(pages/index/index)传递参数. 本文将以传递 name 和 pwd 参数为例,分别介绍此场景在 Android 小程序和 iOS 小程序中 ...
- spark_shuffle方式的演进过程
spark shuffle有四种方式,分别是 hashshuffle 优化后的hashshuffle sortshuffle bypass 一.hashshuffle与优化 一开始spark的shuf ...
- 调试备忘录-SWD协议解析
目录--点击可快速直达 目录 写在前面 1 SWD协议简介 2 SWD物理层协议解析 2.1 SWD通信时序分析 2.2 SWD 寄存器简介 2.2.1 DP寄存器 2.2.2 AP寄存器 ...
- Splunk 8.2.0 发布 (macOS, Linux, Windows)
强烈鄙视 CSDN 用户 CIAS(账号:hanzheng260561728),盗用本站资源,删除原文链接,并且用于收费下载!!! 请访问原文链接:https://sysin.org/article/ ...
- Lidar激光雷达与Radar雷达
Lidar激光雷达与Radar雷达 自动驾驶技术正迅速成为汽车工业的驱动力.来自全球的汽车制造商正在与Google等顶级高科技巨头以及其他知名初创公司合作,共同开发下一代自动驾驶汽车.中国也开辟了自动 ...
- 单点突破:MySQL之日志
前言 开发环境:MySQL5.7.31 日志是 mysql 数据库的重要组成部分,记录着数据库运行期间各种状态信息.若数据库发生故障,可通过不同日志记录恢复数据库的原来数据.因此实际上日志系统直接决定 ...
- (鸡汤文)这一次我终于搞懂了 JavaScript 定时器的 this 指向!
开篇语 忽然有一种感觉,每次学习一个知识点就像是谈一场恋爱:从初次邂逅,到彼此了解,一切都那么的符合恋爱的过程! 如果这个知识点再有点"调皮"的话,那简直是让人欲仙欲死而又不可自拔 ...
- 高吞吐、低延迟 Java 应用的 GC 优化实践
本篇原文作者是 LinkedIn 的 Swapnil Ghike,这篇文章讲述了 LinkedIn 的 Feed 产品的 GC 优化过程,虽然文章写作于 April 8, 2014,但其中的很多内容和 ...
- Luat Inside | 致敬经典,使用Air724UG制作简易贪吃蛇
作者简介: 打盹的消防车--活跃于Luat社群的新生代全能开发者,东北小伙儿爽朗幽默.好学敏思,更是实力行动派.幼年曾手握火红炽铁而后全然无恙,堪称魔幻经历:如今热衷于各类嵌入式软硬件研究,快意物联江 ...
- JAVA并行程序基础一
JAVA并行程序基础一 线程的状态 初始线程:线程的基本操作 1. 新建线程 新建线程只需要使用new关键字创建一个线程对象,并且用start() ,线程start()之后会执行run()方法 不要直 ...