(4)ElasticSearch在linux环境中搭建集群
1.概述
一个运行中的Elasticsearch实例称为一个节点(node),而集群是由一个或者多个拥有相同cluster.name配置的节点组成,它们共同承担数据和负载的压力。当有节点加入集群中或者从集群中移除节点时,集群将会重新平均分布所有的数据。
如一个节点被选举成为主节点时,它将负责管理集群范围内的所有变更,例如增删索引或者节点等。而主节点并不需要涉及到文档级别的变更和搜索等操作,所以当集群只拥有一个主节点的情况下,即使流量的增加它也不会成为瓶颈。任何节点都可以成为主节点。
用户可以将请求发送到集群中的任何节点,包括主节点。每个节点都知道任意文档所处的位置,并且能够将我们的请求直接转发到存储我们所需文档的节点。无论我们将请求发送到哪个节点,它都能负责从各个包含我们所需文档的节点收集回数据,并将最终结果返回給客户端。Elasticsearch对这一切的管理都是透明的。
2. 为什么要实现Elasticsearch集群
如果是单节点集群,一旦该节点出现故障,无法做到故障转移,那么Elasticsearch就会无法访问,这对系统来说是灾难性的,而部署多节点集群,能够水平扩容,故障转移,实现高可用,解决高并发。
2.1高可用
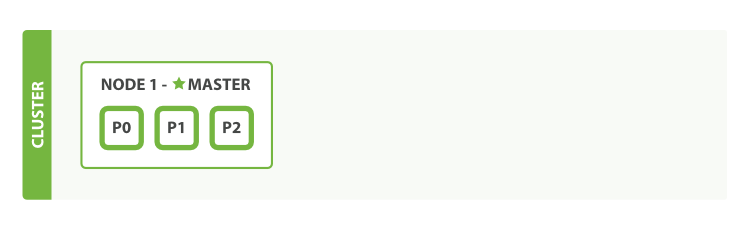
假设我们部署了三个节点集群(三个主分片P0、P1、P2,分别各对应两个副本分片R0、R1、R2):
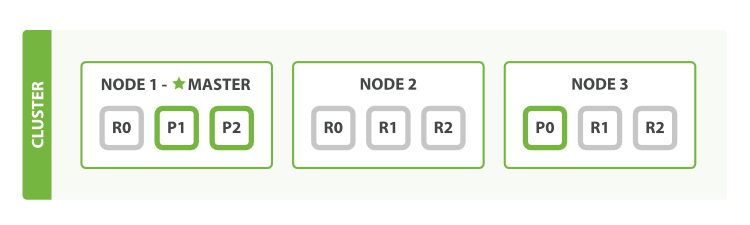
如果主节点Node1故障了,Elasticsearch内部机制会根据节点故障重新选举一个节点作为主节点,而主副分片也会重新调整: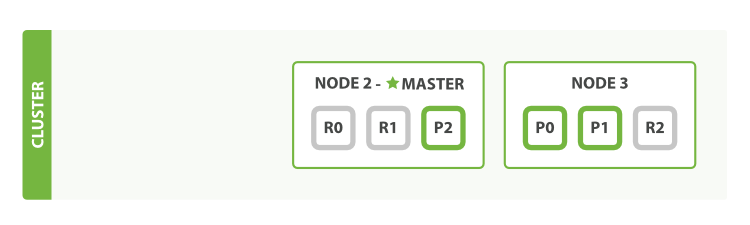
但因为副本分片是主副一比二缘故,此时集群健康状态会是yellow。但当故障节点恢复正常时候,集群健康状态会是green恢复正常。
2.2存储空间
一台服务器存储空间肯定是有限的,当数据量上来时候,这是灾难性的。如果部署多台服务器节点集群,那么就能解决存储空间的问题了。
3.集群搭建
3.1环境准备
|
System |
IP |
Node |
Leader |
|
CentOS-7 |
192.168.142.129 |
node-1 |
master |
|
192.168.142.130 |
node-2 |
replica |
分别往129、130服务器部署两个Elasticsearch节点,安装详情可以参考我第一篇文章。
3.2修改elasticsearch.yml配置
# ---------------------------------- Cluster -----------------------------------
#
# Use a descriptive name for your cluster:
#
cluster.name: my-ebs
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: node-1
#
# Add custom attributes to the node:
#
#node.attr.rack: r1
#
# ----------------------------------- Memory -----------------------------------
#
# Lock the memory on startup:
#
bootstrap.memory_lock: true
#
# Make sure that the heap size is set to about half the memory available
# on the system and that the owner of the process is allowed to use this
# limit.
#
# Elasticsearch performs poorly when the system is swapping the memory.
#
# ---------------------------------- Network -----------------------------------
#
# By default Elasticsearch is only accessible on localhost. Set a different
# address here to expose this node on the network:
#
network.host: 192.168.142.129
#
# By default Elasticsearch listens for HTTP traffic on the first free port it
# finds starting at 9200. Set a specific HTTP port here:
#
#http.port: 9200
#
# For more information, consult the network module documentation.
#
# --------------------------------- Discovery ----------------------------------
#
# Pass an initial list of hosts to perform discovery when this node is started:
# The default list of hosts is ["127.0.0.1", "[::1]"]
#
#discovery.seed_hosts: ["host1", "host2"]
discovery.seed_hosts: ["192.168.142.129", "192.168.142.130"]
#
# Bootstrap the cluster using an initial set of master-eligible nodes:
#
cluster.initial_master_nodes: ["node-1", "node-2"]
#
# For more information, consult the discovery and cluster formation module documentation.
#
这是node-1修改后的配置,node-2配置相差不大,区别如下:
node.name: node-2
network.host: 192.168.142.130
集群节点外部访问HTTP端口默认都是9200,内部TCP连接端口默认都是9300。如果是同一个服务器不同节点,那么就要配置不同的端口号了。具体配置说明详情可以查看官网。
3.3允许Elasticsearch端口访问
输入如下命令放开防火墙对Elasticsearch端口访问限制:
firewall-cmd --zone=public --add-port=9200/tcp --permanent
firewall-cmd --zone=public --add-port=9300/tcp –permanent
重新加载防火墙:
firewall-cmd –reload
3.4启动Elasticsearch集群
如何启动Elasticsearch或者启动过程会遇到什么样问题,不懂的可以查看我第一篇文章,里面基本都有介绍,这里就不一一描述了,因为集群搭建主要是配置文件:
●node1: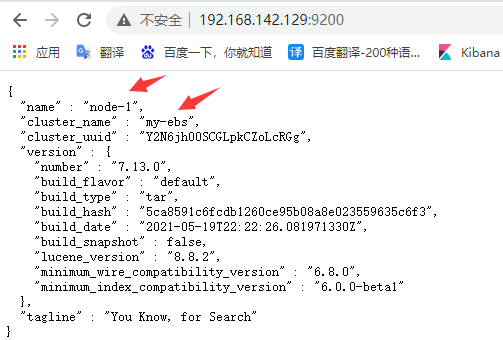
●node2: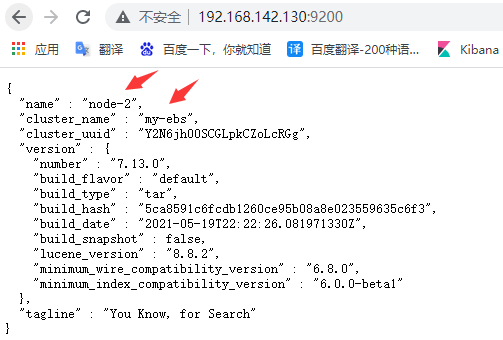
●查看集群节点状况:
http://192.168.142.129:9200/_cat/nodes?pretty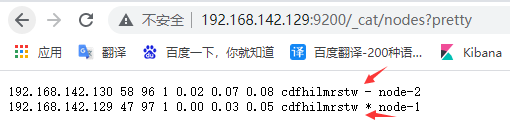
注:*符号表示主节点,-表示副节点。
●查看集群状态:
http://192.168.142.129:9200/_cluster/health
status字段指示着当前集群在总体上是否工作正常。它的三种颜色含义如下:
green:所有的主分片和副本分片都正常运行。
yellow:所有的主分片都正常运行,但不是所有的副本分片都正常运行。
red:有主分片没能正常运行。
参考文献:
Important Elasticsearch configuration
应对故障
(4)ElasticSearch在linux环境中搭建集群的更多相关文章
- (1)Zookeeper在linux环境中搭建集群
1.简介 ZooKeeper是Apache软件基金会的一个软件项目,它为大型分布式计算提供开源的分布式配置服务.同步服务和命名注册.ZooKeeper的架构通过冗余服务实现高可用性.Zookeeper ...
- Linux环境下Hadoop集群搭建
Linux环境下Hadoop集群搭建 前言: 最近来到了武汉大学,在这里开始了我的研究生生涯.昨天通过学长们的耐心培训,了解了Hadoop,Hdfs,Hive,Hbase,MangoDB等等相关的知识 ...
- Linux环境下ZooKeeper集群环境搭建关键步骤
ZooKeeper版本:zookeeper-3.4.9 ZooKeeper节点:3个节点 以下为Linux环境下ZooKeeper集群环境搭建关键步骤: 前提条件:已完成在Linux环境中安装JDK并 ...
- Linux环境下SolrCloud集群环境搭建关键步骤
Linux环境下SolrCloud集群环境搭建关键步骤. 前提条件:已经完成ZooKeeper集群环境搭建. 一.下载介质 官网下载地址:http://www.apache.org/dyn/close ...
- Linux环境下HDFS集群环境搭建关键步骤
Linux环境下HDFS集群环境搭建关键步骤记录. 介质版本:hadoop-2.7.3.tar.gz 节点数量:3节点. 一.下载安装介质 官网下载地址:http://hadoop.apache.or ...
- Linux+.NetCore+Nginx搭建集群
本篇和大家分享的是Linux+NetCore+Nginx搭建负载集群,对于netcore2.0发布后,我一直在看官网的文档并学习,关注有哪些新增的东西,我,一个从1.0到2.0的跟随者这里只总结一句话 ...
- (3)ElasticSearch在linux环境中安装与配置head插件
1.简介 ElasticSearch-Head跟Kibana一样也是一个针对ElasticSearch集群操作的API的可视化管理工具,它提供了集群管理.数据可视化.增删改查.查询语句等功能,最重要还 ...
- Linux环境下Redis集群实践
环境:centos 7 一.编译及安装redis源码 源码地址:redis版本发布列表 cd redis-3.2.8 sudo make && make install 二.创建节点 ...
- (2)ElasticSearch在linux环境中集成IK分词器
1.简介 ElasticSearch默认自带的分词器,是标准分词器,对英文分词比较友好,但是对中文,只能把汉字一个个拆分.而elasticsearch-analysis-ik分词器能针对中文词项颗粒度 ...
随机推荐
- 快速上手 Rook,入门云原生存储编排
Rook 是一个开源 cloud-native storage orchestrator(云原生存储编排器),为各种存储解决方案提供平台.框架和支持,以与云原生环境进行原生集成. Rook 将存储软件 ...
- RTC为何这么火?
国内疫情已经接近尾声,有疫情的原因孵化的音视频互动类 App数量出现井喷式增长,通讯场景被资本关注,市场持续走高.在线教育.娱乐社交.直播带货等领域逆势增长,也带动了开发者们对于 IM 和RTC能力的 ...
- ListPopupWindow和Popupwindow的阴影相关问题demo总结
Popupwindow: 优点:可以通过setBackgroundDrawable()来重新设置阴影. 缺点:当AnchorView是可移动的,比如移动到屏幕的左右边界.左下角.右下角时,Popupw ...
- insert()与substr()函数
insert()函数与substr()函数 insert()函数: insert ( pos, str2);--将字符串str2插入到原字符串下标为pos的字符前 insert (pos, n, c) ...
- Android太太太太太卷了,累了
我们聊到互联网行业的时候,一个不可避免的话题就是"内卷",而在程序员这个群体中,Android,绝对是卷得最厉害的. 毕竟前几年Android兴起的时候,入门门槛低,培训机构培养了 ...
- 1549页Android最新面试题含答案
在今年年初的疫情中,成了失业人员之一,于是各种准备面试,发现面试题网上很多,但是都是很凌乱的,而且一个地方一点,没有一个系统的面试题库,有题库有的没有答案或者是答案很简洁,没有达到面试的要求.所以一直 ...
- lerna 常用命令
lerna 介绍 lerna 处理机构 固定模式(fixed) 所有包是统一的版本号,每次升级,所有包版本统一更新,不管这个包内容改变与否 具体体现在,lerna 的配置文件 lerna.json 中 ...
- Tomcat服务器种的HttpServletRequest类
HttpServletRequest 类有什么作用: 每次只要有请求进入 Tomcat 服务器,Tomcat 服务器就会把请求过来的 HTTP 协议信息解析好封装到 Reque ...
- POSIX多线程编程-条件变量pthread_cond_t
条件变量通过允许线程阻塞和等待另一个线程发送信号的方法弥补了互斥锁的不足,它常和互斥锁一起使用.使用时,条件变量被用来阻塞一个线程,当条件不满足时,线程往往解开相应的互斥锁并等待条件发生变化.一旦其它 ...
- 寻找写代码感觉(二)之 Spring Boot 项目属性配置
一.前言 写代码就和恋爱一样,有反馈就要趁热打铁,搞完了项目搭建,接下来就来搞搞项目配置. 二.IDEA设置 1.编码配置 这里所说的就是代码的编码格式,你可以不设置,但是可能要面临的是,很多未知的麻 ...