Python的正则表达式与JSON
Python的正则表达式需要导入re模块
菜鸟教程:http://www.runoob.com/python/python-reg-expressions.html
官方文档:https://docs.python.org/3.6/library/re.html
一译中文:https://yiyibooks.cn/xx/python_352/library/re.html
常用正则表达式:https://www.cnblogs.com/Akeke/p/6649589.html
===========================================================
1.方法
findall(pattern, string, flags=0):
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:正则表达式修饰符 - 可选标志 |
flags:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
flags可以指定多个 例:re.I | re.S 两者是且的关系
sub(pattern, repl, string, count=0, flags=0):检索和替换
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
repl可以为函数 很强大 例:
import re
s = 'A8C3721D86'
def convert(value):
matched = value.group() #拿到具体的值
if int(matched) >= 6:
return ''
else:
return ''
r = re.sub('\d',convert,s)
print(r)
----------------------------------------------------------------
A9C0900D99
#group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
match(pattern, string, flags=0):re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
search(pattern, string, flags=0): re.search 扫描整个字符串并返回第一个成功的匹配。
2.元字符
\d :匹配一个数字字符
\D:匹配一个非数字字符
\w:匹配字母数字及下划线 ,字母:单词字符(\的只能匹配a-z A-Z 0-9 _)
\W:匹配非字母数字及下划线,(&,\n,\r等都算作非字母数字及下划线)
\s:匹配任意空白字符,等价于 [\t\n\r\f].(制表符都算作空白字符 \n,\t,\r等)
\S:匹配任意非空字符
[...]:用来表示一组字符,单独列出:[amk] 匹配 'a','m'或'k'
import re
s = 'abc,acc,adc,aec,afc,ahc'
r = re.findall('a[cf]c',s)
print(r) ----------
['acc', 'afc']
[^...]:不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符
数量词
re{n}:让前面的re表达式匹配多次,例:
import re
s = 'python 11111java678php'
r = re.findall('[a-z]{3}',s)
print(r)
--------------------------------------------------
['pyt', 'hon', 'jav', 'php']
re{ n, m}:匹配 n 到 m 次由前面的正则表达式定义的片段,贪婪方式(够多则使用m值)
import re
s = 'python 11111java678php'
r = re.findall('[a-z]{3,6}',s)
print(r)
-----------------------------------------------------
['python', 'java', 'php']
re{ n, m}?:可以转换为非贪婪方式(使用n值)
re*:匹配0个或多个的表达式。(*前面的字符)
import re
s = 'pytho0python1pythonn2'
r = re.findall('python*',s)
print(r)
-------------------------------------------------
['pytho', 'python', 'pythonn']
re+:匹配1个或多个的表达式。
re?:匹配0个或1个由前面的正则表达式定义的片段,非贪婪方式(有一个也匹配,忽略后面多的re)
import re
s = 'pytho0python1pythonn2'
r = re.findall('python?',s)
print(r)
----------------------------------------------
['pytho', 'python', 'python']
. :匹配任意字符,除了换行符\n,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。
边界匹配
^:匹配字符串的开头
$:匹配字符串的末尾
import re
qq = ''
r = re.findall('\d{4,8}',qq)
print("\d{4,8} : " + str(r)) r2 = re.findall('^\d{4,8}',qq)
print('^\d{4,8}: '+str(r2)) r3 = re.findall('\d{4,8}$',qq)
print('\d{4,8}$: '+ str(r3)) r4 = re.findall('^\d{4,8}$',qq) #匹配整个字符串
print('^\d{4,8}$: '+ str(r4)) r5 = re.findall('^000',qq) #^匹配字符串开头,则开头必须000 ;$同理
print('^000: '+ str(r5))
-----------------------------------------------------------------------------
\d{4,8} : ['']
^\d{4,8}: ['']
\d{4,8}$: ['']
^\d{4,8}$: []
^000: []
组
(re):匹配括号内的表达式,也表示一个组
import re
qq = 'PythonPythonPythonPythonPythonPythonPython'
r = re.findall('(Python){3}',qq)
print(r)
------------------------------------------------------------------------
['Python', 'Python']
========================================================================
JSON
导入json模块
反序列化过程
import json
json_str = '{"name":"zhangsan","age":18}' #这里的json 中的字符串类型必须用"" ,因为里面用了"",所以外面需要用''
student = json.loads(json_str)
print(type(student))
print(student)
-----------------------------------------------------------------------
<class 'dict'>
{'name': 'zhangsan', 'age': 18}
import json
json_str = '[{"name":"zhangsan","age":18},{"name":"lisi","age":19}]'
student = json.loads(json_str)
print(type(student))
print(student)
--------------------------------------------------------------------
<class 'list'>
[{'name': 'zhangsan', 'age': 18}, {'name': 'lisi', 'age': 19}]
序列化过程
import json
student = [{'name':'zhangsan','age':18,'flag':False},{'name':'lisi','age':18,'flag':True}]
json_str = json.dumps(student)
print(type(json_str))
print(json_str)
-----------------------------------------------------------------------------
<class 'str'>
[{"name": "zhangsan", "age": 18, "flag": false}, {"name": "lisi", "age": 18, "flag": true}]
JSON中的数据类型和python中的对应关系:
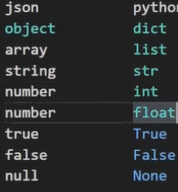
JSON对象:
JSON:
JSON字符串:
Python的正则表达式与JSON的更多相关文章
- Python(八) 正则表达式与JSON
一.初识正则表达式 正则表达式 是一个特殊的字符序列,一个字符串是否与我们所设定的这样的字符序列,相匹配 快速检索文本.实现替换文本的操作 json(xml) 轻量级 web 数据交换格式 impor ...
- python 历险记(六)— python 对正则表达式的使用(上篇)
目录 引言 什么是正则表达式? 正则表达式有什么用? 正则表达式的语法及使用实例 正则表达式语法有哪些? 这些正则到底该怎么用? 小结 参考文档 系列文章列表 引言 刚接触正则表达式,我也曾被它们天书 ...
- Python语言中对于json数据的编解码——Usage of json a Python standard library
一.概述 1.1 关于JSON数据格式 JSON (JavaScript Object Notation), specified by RFC 7159 (which obsoletes RFC 46 ...
- [python] 常用正则表达式爬取网页信息及分析HTML标签总结【转】
[python] 常用正则表达式爬取网页信息及分析HTML标签总结 转http://blog.csdn.net/Eastmount/article/details/51082253 标签: pytho ...
- Python 进阶 - 正则表达式
1. 正则表达式基础 1.1. 简单介绍 正则表达式并不是Python的一部分.正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十 ...
- python study - 正则表达式
第 7 章 正则表达式 7.1. 概览 7.2. 个案研究:街道地址 7.3. 个案研究:罗马字母 7.3.1. 校验千位数 7.3.2. 校验百位数 7.4. 使用 {n,m} 语法 7.4.1. ...
- python使用正则表达式文本替换
2D客户端编程从某种意义上来讲就是素材组织,所以,图片素材组织经常需要批量处理,python一定是最佳选择,不管是win/linux/mac都有一个简单的运行环境 举两个应用场景: 如果不是在某个文件 ...
- python的正则表达式 re
python的正则表达式 re 本模块提供了和Perl里的正则表达式类似的功能,不关是正则表达式本身还是被搜索的字符串,都可以是Unicode字符,这点不用担心,python会处理地和Ascii字符一 ...
- Python之正则表达式(re模块)
本节内容 re模块介绍 使用re模块的步骤 re模块简单应用示例 关于匹配对象的说明 说说正则表达式字符串前的r前缀 re模块综合应用实例 正则表达式(Regluar Expressions)又称规则 ...
随机推荐
- 为Linux集群创建新账户,并配置hadoop集群
转自:http://blog.csdn.net/bluesky8640/article/details/6945776 之前装python.jdk.hadoop都是用的root账户,这是一个绝对的失策 ...
- 监督学习——决策树理论与实践(上):分类决策树
1. 介绍 决策树是一种依托决策而建立起来的一种树.在机器学习中,决策树是一种预测模型,代表的是一种对象属性与对象值之间的一种映射关系,每一个节点代表某个对象/分类,树中的每一个分叉路 ...
- SQLServer覆盖索引
为了更好地理解覆盖索引,在正式介绍覆盖索引之前,首先稍微来谈一谈有关索引的一些基础知识. 数据页和索引页 在SQLServer中,数据存储的基本单位是页,一页的大小为8KB,分别由页首,数据行和行偏移 ...
- Vue中router两种传参方式
Vue中router两种传参方式 1.Vue中router使用query传参 相关Html: <!DOCTYPE html> <html lang="en"> ...
- 第8章—使用Spring Web Flow—Spring Web Flow的配置
Spring中配置Web Flow Spring Web Flow 是 Spring 的一个子项目,其最主要的目的是解决跨越多个请求的.用户与服务器之间的.有状态交互问题,比较适合任何比较复杂的.有状 ...
- 【Java并发编程】:使用wait/notify/notifyAll实现线程间通信
在java中,可以通过配合调用Object对象的wait()方法和notify()方法或notifyAll()方法来实现线程间的通信.在线程中调用wait()方法,将阻塞等待其他线程的通知(其他线程调 ...
- Asp.Net Core 连接Mysql
上一篇文章里最后在VS里测试是没有问题的,但是在Windows命令行模式下会报错. 首先用dotnet restore命令的时候会出现error: 然后用dotnet run会出现警告,但是依旧会成功 ...
- web前端html快速入门
HTML 学前端之间不得不知道一个网站:http://www.w3school.com.cn/ 网上有很多教程关于前端的,写的特别详细,也写的特别好.我们应该要自已理解,一些相应的前端的知识,不能只是 ...
- java面试②基础部分
2.1.3 讲一下java中int数据占几个字节 java中有几种基本数据类型? 2.1.4. 面向对象的特征有哪些方面 有四大基本特征:封装.抽象.继承.多态 1)封装,即将对象封装成一个高度自治和 ...
- 彻底解决springMVC中文乱码
一.页面编码 <%@ page contentType="text/html;charset=UTF-8" language="java" %> & ...