Hive的三种安装方式(内嵌模式,本地模式远程模式)
一、安装模式介绍:
Hive官网上介绍了Hive的3种安装方式,分别对应不同的应用场景。
1、内嵌模式(元数据保村在内嵌的derby种,允许一个会话链接,尝试多个会话链接时会报错)
2、本地模式(本地安装mysql 替代derby存储元数据)
3、远程模式(远程安装mysql 替代derby存储元数据)
二、安装环境以及前提说明:
首先,Hive是依赖于hadoop系统的,因此在运行Hive之前需要保证已经搭建好hadoop集群环境。
本文中使用的hadoop版本为2.5.1,Hive版本为1.2.1版。
OS:Linux Centos 6.5 64位
jdk:java version "1.7.0_79"
假设已经下载了Hive的安装包,且安装到了/home/install/hive-1.2.1
在~/.bash_profile中设定HIVE_HOME环境变量:
export HIVE_HOME=/home/install/hive-1.2.1
三、内嵌模式安装:
这种安装模式的元数据是内嵌在Derby数据库中的,只能允许一个会话连接,数据会存放到HDFS上。
1、切换到HIVE_HOME/conf目录下,执行下面的命令:
cp hive-env.sh.template hive-env.sh
vim hive-env.sh
在hive-env.sh中添加以下内容:
HADOOP_HOME=/home/install/hadoop-2.5.1
2、启动hive,由于已经将HIVE_HOME加入到了环境变量中,所以这里直接在命令行敲hive即可:

然后我们看到在hadoop的HDFS上已经创建了对应的目录。

注意,只要上面2步即可完成内嵌模式的安装和启动,不要画蛇添足。。。。。。比如下面
================================【下面这段就不要看了】==============================================
(作废)2、提供一个hive的基础配置文件,执行如下代码,就是将conf目录下自带的文件修改为配置文件:
cp hive-default.xml.template hive-site.xml
(作废)3、启动hive,由于已经将HIVE_HOME加入到了环境变量中,所以这里直接在命令行敲hive即可:
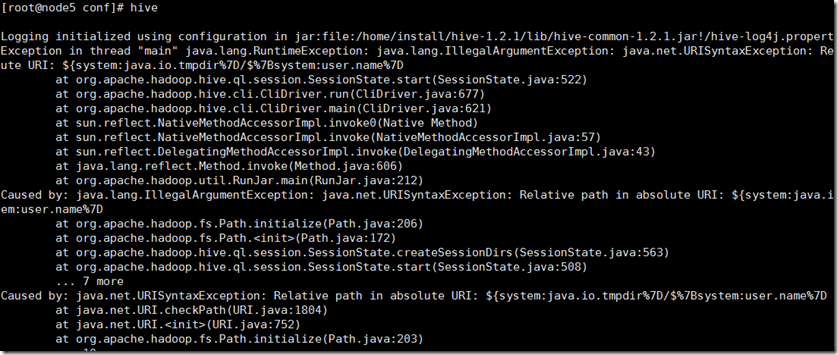
(作废)结果报错了,看错误日志中提到system:java.io.tmpdir,这个配置项在hive-site.xml中有提到。
(作废)我们创建一个临时目录/opt/tem/hive-1.2.1/iotemp,并修改hive-site.xml中的system:java.io.tmpdir的值:
mkdir -p /opt/tem/hive-1.2.1/iotemp
vim hive-site.xml
(作废)在vim编辑界面输入如下命令完成替换:
:%s@\${system:java.io.tmpdir}@/opt/tem/hive-1.2.1/iotemp@g
(作废)4、重新启动hive:

(作废)报了这样一个错误:java.lang.IncompatibleClassChangeError: Found class jline.Terminal, but interface was expected。
(作废)查询资料说,hadoop目录下存在老版本jline,替换掉就行了。复制后注意删除原来版本的jar包。
cp /home/install/hive-1.2.1/lib/jline-2.12.jar /home/install/hadoop-2.5.1/share/hadoop/yarn/lib/
rm -rf /home/install/hadoop-2.5.1/share/hadoop/yarn/lib/jline-0.9.94.jar
(作废)再次重新启动,OK了。

四、本地模式安装:
这种安装方式和嵌入式的区别在于,不再使用内嵌的Derby作为元数据的存储介质,而是使用其他数据库比如MySQL来存储元数据。
这种方式是一个多用户的模式,运行多个用户client连接到一个数据库中。这种方式一般作为公司内部同时使用Hive。
这里有一个前提,每一个用户必须要有对MySQL的访问权利,即每一个客户端使用者需要知道MySQL的用户名和密码才行。
下面开始正式搭建,这里要求hadoop系统已经正常启动,且MySQL数据库已经正确安装。
1、首先登录MySQL,创建一个数据库,这里命名为hive,数据库名是可以随意定义的。
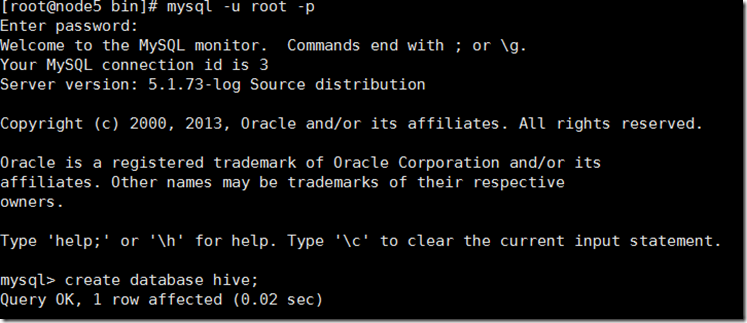
创建hive用户,并赋予所有的权限:
CREATE USER 'hive'@'localhost' IDENTIFIED BY '123456';
GRANT ALL PRIVILEGES ON *.* TO hive IDENTIFIED BY '123456' WITH GRANT OPTION;
2、将MySQL的JDBC驱动包拷贝到hive的安装目录中,驱动包自行查找下载。
cp mysql-connector-java-5.1.32-bin.jar /home/install/hive-1.2.1/lib/
3、将HIVE_HOME/conf下的hive-default.xml.template拷贝一份:
cp hive-default.xml.template hive-site.xml
4、修改hive-site.xml文件:
该配置文件有3300多行,选择其中的几个选项进行修改即可。
A、修改javax.jdo.option.ConnectionURL属性。
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
B、修改javax.jdo.option.ConnectionDriverName属性。
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
C、修改javax.jdo.option.ConnectionUserName属性。即数据库用户名。
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
D、修改javax.jdo.option.ConnectionPassword属性。即数据库密码。
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
E、添加如下属性hive.metastore.local:
<property>
<name>hive.metastore.local</name>
<value>true</value>
<description>controls whether to connect to remove metastore server or open a new metastore server in Hive Client JVM</description>
</property>
F、修改hive.server2.logging.operation.log.location属性,因为默认的配置里没有指定具体的路径。
<property>
<name>hive.server2.logging.operation.log.location</name>
<value>/tmp/hive/operation_logs</value>
<description>Top level directory where operation logs are stored if logging functionality is enabled</descripti on>
</property>
G、修改hive.exec.local.scratchdir属性。
<property>
<name>hive.exec.local.scratchdir</name>
<value>/tmp/hive</value>
<description>Local scratch space for Hive jobs</description>
</property>
H、修改hive.downloaded.resources.dir属性。
<property>
<name>hive.downloaded.resources.dir</name>
<value>/tmp/hive/resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
I、修改属性hive.querylog.location属性。
<property>
<name>hive.querylog.location</name>
<value>/tmp/hive/querylog</value>
<description>Location of Hive run time structured log file</description>
</property>
5、配置hive的log4j配置文件。
cp hive-log4j.properties.template hive-log4j.properties
6、将hive下的jline-2.12.jar替换掉hadoop自带的包,不然会报错。
cp /home/install/hive-1.2.1/lib/jline-2.12.jar /home/install/hadoop-2.5.1/share/hadoop/yarn/lib/
rm -rf /home/install/hadoop-2.5.1/share/hadoop/yarn/lib/jline-0.9.94.jar
7、启动hive,界面如下:

五、远程模式安装,即server模式。
这种模式需要使用hive安装目录下提供的beeline+hiveserver2配合使用才可以。
其原理就是将metadata作为一个单独的服务进行启动。各种客户端通过beeline来连接,连接之前无需知道数据库的密码。
1、首先执行hiveserver2命令:
./hiveserver2 start
启动后命令行会一直监听不退出,我们可以看到它监听了10000端口。

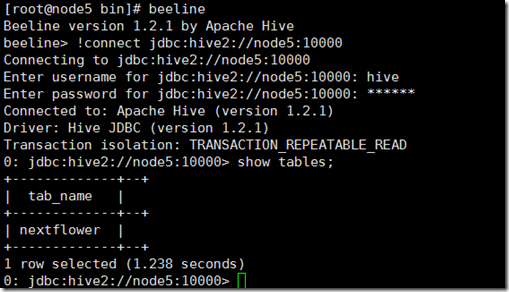
2、新开一个命令行窗口,执行beeline命令:
[root@node5 bin]# beeline
Beeline version 1.2.1 by Apache Hive
beeline> !connect jdbc:hive2://node5:10000
Connecting to jdbc:hive2://node5:10000
Enter username for jdbc:hive2://node5:10000: hive
Enter password for jdbc:hive2://node5:10000: ******
报错了,错误日志如下:
Error: Failed to open new session: java.lang.RuntimeException: java.lang.RuntimeException: org.apache.hadoop.security.AccessControlException: Permission denied: user=hive, access=EXECUTE, inode="/tmp":root:supergroup:drwx------
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkFsPermission(FSPermissionChecker.java:271)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:257)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkTraverse(FSPermissionChecker.java:208)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:171)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:5904)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.getFileInfo(FSNamesystem.java:3691)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.getFileInfo(NameNodeRpcServer.java:803)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolServerSideTranslatorPB.getFileInfo(ClientNamenodeProtocolServerSideTranslatorPB.java:779)
at org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$ClientNamenodeProtocol$2.callBlockingMethod(ClientNamenodeProtocolProtos.java)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:585)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:928)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2013)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:2009)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1614)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:2007) (state=,code=0)
0: jdbc:hive2://node5:10000 (closed)>
说是hive用户对HDFS上的/tmp权限不够。
这里直接把HDFS的权限设置为最大。
hadoop fs -chmod 777 /tmp
重新连接:成功了。
Hive的三种安装方式(内嵌模式,本地模式远程模式)的更多相关文章
- grub安装的 三种安装方式
1. 引言 grub是什么?最常态的理解,grub是一个bootloader或者是一个bootmanager,通过grub可以引导种类丰富的系统,如linux.freebsd.windows等.但一旦 ...
- Hive的三种Join方式
Hive的三种Join方式 hive Hive中就是把Map,Reduce的Join拿过来,通过SQL来表示. 参考链接:https://cwiki.apache.org/confluence/dis ...
- 【转】vue.js三种安装方式
Vue.js(读音 /vjuː/, 类似于 view)是一个构建数据驱动的 web 界面的渐进式框架.Vue.js 的目标是通过尽可能简单的 API 实现响应的数据绑定和组合的视图组件.它不仅易于上手 ...
- vue.js三种安装方式
Vue.js(读音 /vjuː/, 类似于 view)是一个构建数据驱动的 web 界面的渐进式框架.Vue.js 的目标是通过尽可能简单的 API 实现响应的数据绑定和组合的视图组件.它不仅易于上手 ...
- Hive metastore三种配置方式
http://blog.csdn.net/reesun/article/details/8556078 Hive的meta数据支持以下三种存储方式,其中两种属于本地存储,一种为远端存储.远端存储比较适 ...
- Hive之 hive的三种使用方式(CLI、HWI、Thrift)
Hive有三种使用方式——CLI命令行,HWI(hie web interface)浏览器 以及 Thrift客户端连接方式. 1.hive 命令行模式 直接输入/hive/bin/hive的执行程 ...
- centOS下 JDK的三种安装方式
由于各Linux开发厂商的不同,因此不同开发厂商的Linux版本操作细节也不一样,今天就来说一下CentOS下JDK的安装: 方法一:手动解压JDK的压缩包,然后设置环境变量 1.在/usr/目录下创 ...
- grub的三种安装方式
1.install命令 install: install [--stage2=STAGE2_FILE] [--force-lba] STAGE1 [d] DEVICE STAGE2 [ADDR] [p ...
- 关于CDH集群spark的三种安装方式简述
一.spark的命令行模式 1.第一种进入方式:执行 pyspark进入,执行exit()退出 注意报错信息:java.lang.IllegalArgumentException: Required ...
随机推荐
- DOM编程的性能问题
用脚本进行DOM操作的代价很昂贵,它是富Web应用中最常见的性能瓶颈. 浏览器中的DOM:天生就慢 DOM(文档对象模型)是独立于语言的,但在浏览器中的接口是用JavaScript实现的.两个相互独立 ...
- JS 工具类
之前工作用的JavaScript比较多,总结了一下工具类,和大家分享一下,有不足之处还请多多见谅!! 1. 数组工具类(arrayUtils) var arrayUtils = {}; (functi ...
- 2.5多重else嵌套的二次方程求根
#include<stdio.h> #include<math.h> int main() { double a, b, c, disc, x1, x2, realpart, ...
- 5天揭秘js高级技术-第二天
一.数组 1. 什么是数组? 数组就是一组数据的集合: 其表现形式就是内存中的一段连续的内存地址: 数组名称其实就是连续内存地址的首地址: 2. 关于js中的数组定义 数组定义无需指定数据类型: 数组 ...
- vtkBoxWidget2Example
This example uses a vtkBoxWidget2 to manipulate an actor. The widget only contains the interaction l ...
- CentOS 6.5移除openJDK及JDK安装环境变量配置及JDK版本切换
一.查找已经安装的open JDK [root@localhost ~]# rpm -qa|grep jdk java--openjdk-.el6_3.x86_64 java--openjdk-1.7 ...
- Linux学习之八--关闭firewall防火墙安装iptables并配置
CentOS 7之后默认使用的是firewall作为防火墙,这里改为iptables防火墙,并开启80端口.3306端口. 1.关闭firewall: systemctl stop firewalld ...
- 解决Android studio导入项目卡死
在使用Android studio的时候常常遇到这样的问题,从github或是其他地方导入项目,Android studio呈现卡死的现象!当遇到这种情况时,可以看看是下面那种情况,在按照方法来解决! ...
- DIV+CSS布局中主要CSS属性介绍
Float: Float属性是DIV+CSS布局中最基本也是最常用的属性,用于实现多列功能,我们知道<div>标签默认一行只能显示一个,而使用Float属性可以实现一行显示多个div的功能 ...
- matlab -xlsread 打开xls文件出错:服务器出现意外情况
错误:xlsread:服务器出现意外情况 原因:非matlab问题,Excel的com加载项启用 解决方法:office - Excel选项-加载项:管理-com加载项-转到-取消可用加载项的勾选.