Spark RDD 窄依赖研究
1.. 简介
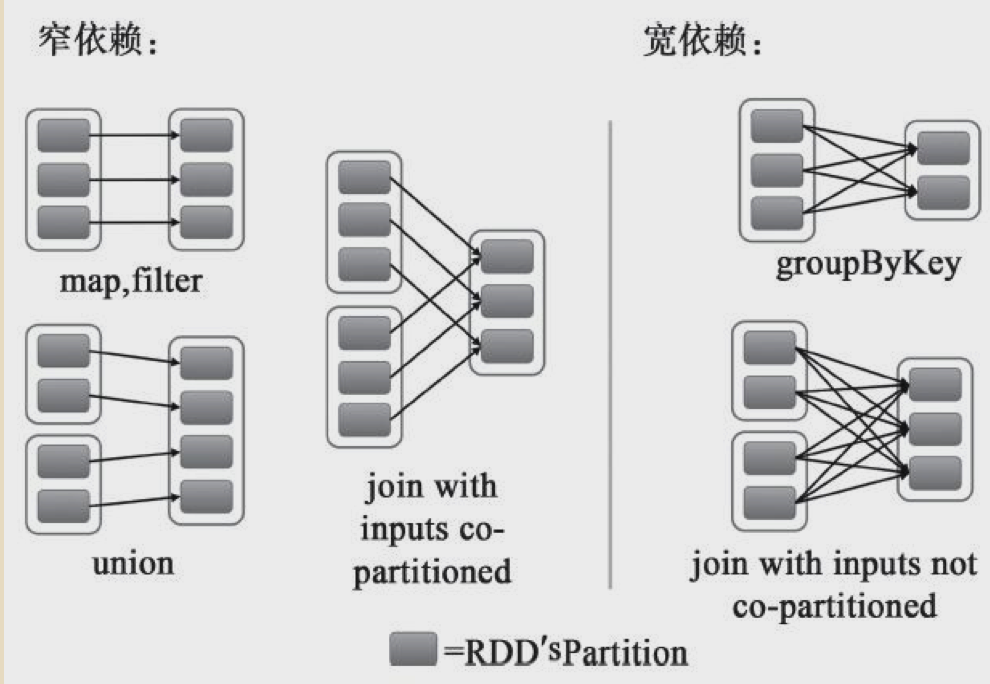
spark从RDD依赖上来说分为窄依赖和宽依赖。
其中可以这样区分是哪种依赖:当父RDD的一个partition被子RDD的多个partitions引用到的时候则说明是宽依赖,否则为窄依赖。
宽依赖会触发shuffe,宽依赖也是一个job钟不同stage的分界线。
本篇文章主要讨论一下窄依赖的场景。
2.依赖关系的建立
字RDD内部维护着父RDD的依赖关系,下列是依赖的抽象类,其中属性rdd就是父RDD
/**
* :: DeveloperApi ::
* Base class for dependencies.
*/
@DeveloperApi
abstract class Dependency[T] extends Serializable {
def rdd: RDD[T]
}
3.窄依赖的三种形式:
窄依赖的抽象类如下:
/**
* :: DeveloperApi ::
* Base class for dependencies where each partition of the child RDD depends on a small number
* of partitions of the parent RDD. Narrow dependencies allow for pipelined execution.
*/
@DeveloperApi
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] {
/**
* Get the parent partitions for a child partition.
* @param partitionId a partition of the child RDD
* @return the partitions of the parent RDD that the child partition depends upon
*/
def getParents(partitionId: Int): Seq[Int] override def rdd: RDD[T] = _rdd
}
窄依赖形式一:MAP,Filter....
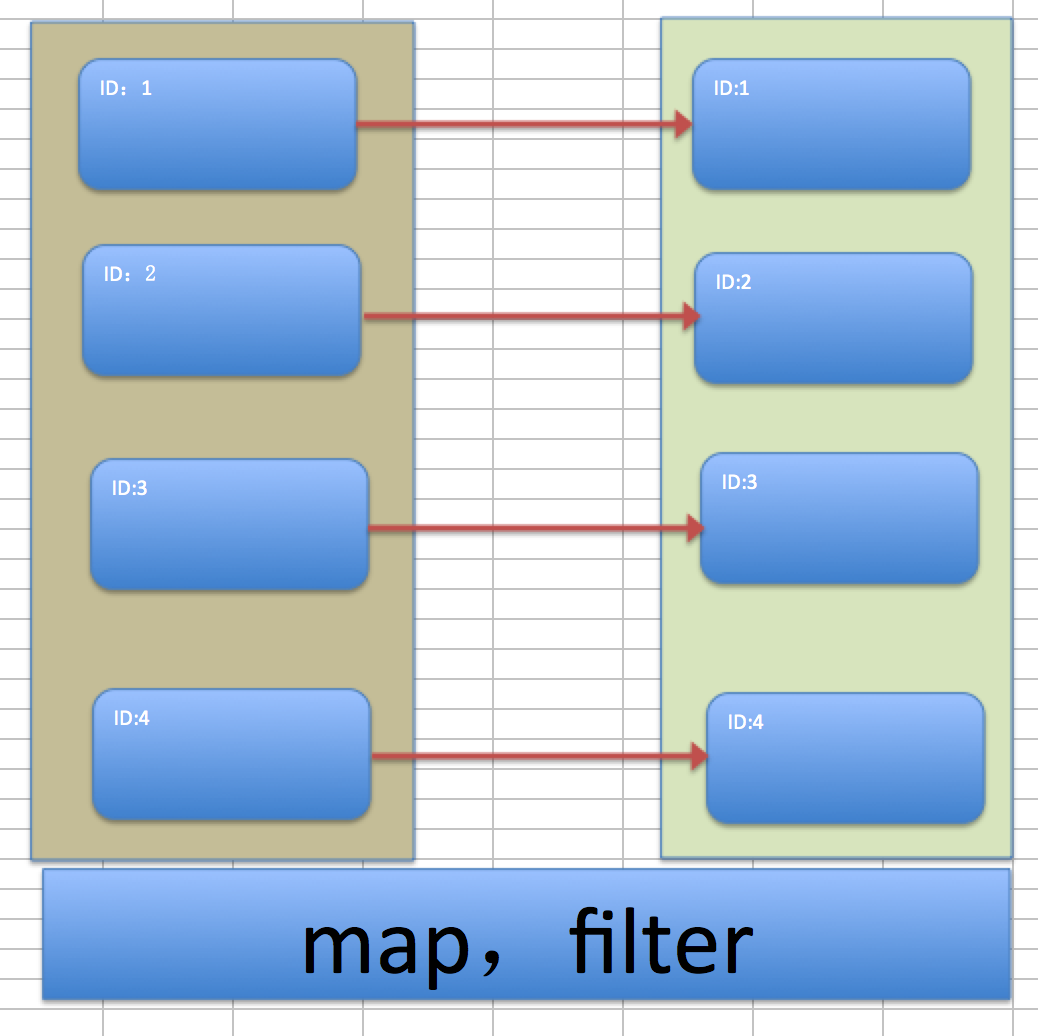
如上两个RDD的转换时通过MAP或者Filter等转换的,RDD的各个partition都是一一对应的,从执行时可以并行化的。
子RDD的分区依赖的父RDD的分区ID是一样不会有变化,这样的窄依赖实现类如下:
/**
* :: DeveloperApi ::
* Represents a one-to-one dependency between partitions of the parent and child RDDs.
*/
@DeveloperApi
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) {
override def getParents(partitionId: Int): List[Int] = List(partitionId) //子RDD的某个分区ID是和父RDD的分区ID是一致的
}
窄依赖方式二:UNION
先来看看其实现类:
/**
* :: DeveloperApi ::
* Represents a one-to-one dependency between ranges of partitions in the parent and child RDDs.
* @param rdd the parent RDD
* @param inStart the start of the range in the parent RDD
* @param outStart the start of the range in the child RDD
* @param length the length of the range
*/
@DeveloperApi
class RangeDependency[T](rdd: RDD[T], inStart: Int, outStart: Int, length: Int)
extends NarrowDependency[T](rdd) { override def getParents(partitionId: Int): List[Int] = {
if (partitionId >= outStart && partitionId < outStart + length) {
List(partitionId - outStart + inStart)
} else {
Nil
}
}
一开始并不好理解上述代码,可参考下图,下图中将各个参数的意义图形化展示:
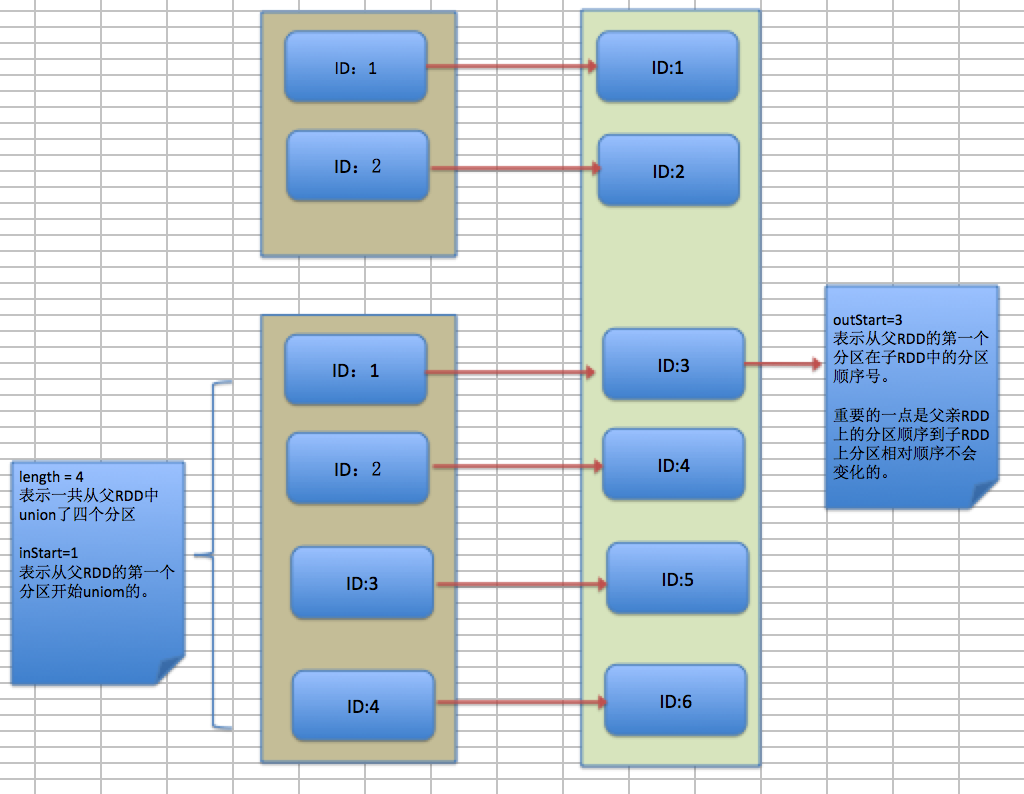
所以上述中子RDD分区中的位号(partitionid)和父RDD的位置号(partitionid)相对的差值 (outStart-inStart)
if (partitionId >= outStart && partitionId < outStart + length) 这段代码的意义:检查当前子RDD分区ID是否在当前父RDD下的范围内
partitionId - outStart + inStart 的意思是:当前子RDD分区id(位置号)与差值相减得出其在父RDD上的分区位置号(id)其实就是:partitionId - (outStart-inStart) 窄依赖方式三:join with inputs co-partitioned
此场景适用于窄依赖方式一。
Spark RDD 窄依赖研究的更多相关文章
- spark rdd 宽窄依赖理解
== 转载 == http://blog.csdn.net/houmou/article/details/52531205 Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过 ...
- Spark RDD的依赖解读
在Spark中, RDD是有依赖关系的,这种依赖关系有两种类型 窄依赖(Narrow Dependency) 宽依赖(Wide Dependency) 以下图说明RDD的窄依赖和宽依赖 窄依赖 窄依赖 ...
- Spark RDD 宽窄依赖
RDD 宽窄依赖 RDD之间有一系列的依赖关系, 可分为窄依赖和宽依赖 窄依赖 从 RDD 的 parition 角度来看 父 RRD 的 parition 和 子 RDD 的 parition 之间 ...
- Spark RDD概念学习系列之RDD的依赖关系(宽依赖和窄依赖)(三)
RDD的依赖关系? RDD和它依赖的parent RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency). 1)窄依赖指的是每 ...
- spark 划分stage Wide vs Narrow Dependencies 窄依赖 宽依赖 解析 作业 job stage 阶段 RDD有向无环图拆分 任务 Task 网络传输和计算开销 任务集 taskset
每个job被划分为多个stage.划分stage的一个主要依据是当前计算因子的输入是否是确定的,如果是则将其分在同一个stage,从而避免多个stage之间的消息传递开销. http://spark. ...
- Spark 中的宽依赖和窄依赖
Spark中RDD的高效与DAG图有着莫大的关系,在DAG调度中需要对计算过程划分stage,而划分依据就是RDD之间的依赖关系.针对不同的转换函数,RDD之间的依赖关系分类窄依赖(narrow de ...
- Spark Streaming揭秘 Day8 RDD生命周期研究
Spark Streaming揭秘 Day8 RDD生命周期研究 今天让我们进一步深入SparkStreaming中RDD的运行机制.从完整的生命周期角度来说,有三个问题是需要解决的: RDD到底是怎 ...
- Spark RDD概念学习系列之rdd的依赖关系彻底解密(十九)
本期内容: 1.RDD依赖关系的本质内幕 2.依赖关系下的数据流视图 3.经典的RDD依赖关系解析 4.RDD依赖关系源码内幕 1.RDD依赖关系的本质内幕 由于RDD是粗粒度的操作数据集,每个Tra ...
- Spark核心RDD、什么是RDD、RDD的属性、创建RDD、RDD的依赖以及缓存、
1:什么是Spark的RDD??? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行 ...
随机推荐
- 【CF710F】String Set Queries(二进制分组,AC自动机)
[CF710F]String Set Queries(二进制分组,AC自动机) 题面 洛谷 CF 翻译: 你有一个字符集合\(D\),初始为空, 有三种操作: 往\(D\)中加入一个串:从\(D\)中 ...
- BZOJ2530 [Poi2011]Party 【贪心】
题目链接 BZOJ2530 题解 如果我们删去一对不连边的仍然存在的点的话,这对点肯定不同时在那个\(\frac{2}{3}n\)的团中,也就是说,每次删点至少删掉一个外点,至多删掉一个内点 那么我们 ...
- linux内核分析 第五周 扒开系统调用的三层皮(下)
rm menu -rf 强制删除原menu文件 git clone http://github.com/mengning/menu.git 从github中克隆 cd menu 在test.c中增加上 ...
- 【数学/贪心/DP】【CF1088E】 Ehab and a component choosing problem
Description 给定一棵 \(n\) 个节点的树,点有点权 \(a_u\),可能为负.现在请你在树上找出 \(k~(1~\leq~k~\leq~n)\) 个不相交集合,使得每个集合中的每对点都 ...
- supervisor 添加新配置不生效的问题
supervisorctl reread supervisorctl reload (不运行这一步会导致启动不了) supervisorctl start xxx:* 提示:No config upd ...
- 【题解】【雅礼集训 2017 Day5】远行 LOJ 6038 LCT
Prelude 快要THUWC了,练一练板子. 传送到LOJ:o(TヘTo) Solution 首先有一条定理. 到树中任意一点的最远点一定是直径的两个端点之一. 我也不会证反正大家都在用,似乎可以用 ...
- Linux下安装Python3和django并配置mysql作为django默认服务器
我的操作系统为centos6.5 1 首先选择django要使用什么数据库.django1.10默认数据库为sqlite3,本人想使用mysql数据库,但为了测试方便顺便要安装一下sqlite开发包 ...
- unity还原three——顶点,三角面,uv
public class Geometry { public Geometry(string name, Data data, Hashtable hash) { Debug.Log("解析 ...
- ElasticStack系列之十五 & query cache 引起性能问题思考
问题描述 一个线上集群,执行的 Query DSL 都是一样的,只是参数不同.统计数据显示 98% ~ 99% 的查询相应速度都很快,只需要 4 ~ 6ms,但是有 1% 左右的查询响应时间在 100 ...
- day12 继承
设计原则:开闭原则:对于拓展open,对于修改close. 类与类的关系:1.is a(继承关系) 2.has a(组合关系) 继承的优点:1.代码的可重用性 2.父类的属性和方法用于子类 3.子类可 ...