11-hdfs-NameNode-HA-wtihQJM解决单点故障问题
在hdfs中, NN只有一个, 但其中保存的数据尤其重要, 所以需要将元数据保存, 其中源数据有2个形式, fsimage 和 edit文件, 最简单的解决方法就是复制fsimage, 并在文件修改时同时修改 NNActive 和 NNStandby 中的edit, 保存在第三方的QJM中, 所以多个NN除了active接受用户请求外, 无其他区别
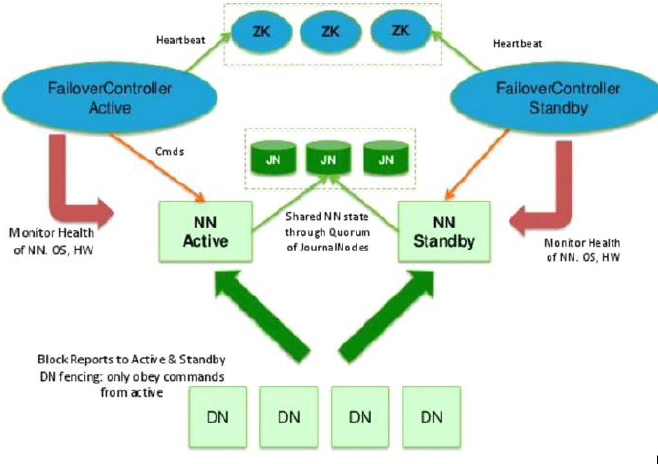
首先是, 集群规划:
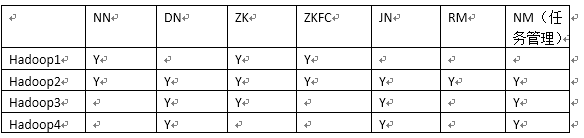
可以看到NN是有1和2组成active和standby的, 之前说过NN需要有DNN免密登录的权限, 所以, 两台分别设置其他三台的免密登录
1, 多台NN间切换, 通过zookeeper来实现的
1) 安装zookeeper.3.4.6.tar.gz, 并创建 conf/zoo.cfg文件
tickTime=
dataDir=/var/lib/zookeeper
clientPort=
initLimit=
syncLimit=
server.=192.168.208.106::
server.=192.168.208.107::
server.=192.168.208.108::
2), 创建data目录和log目录(mkdir -p)
3), 在 ${dataDir}/下面 配置节点信息 myid, 跟上面的server.x保持一致
4), 启动, cd /usr/opt/zookeeper3.4.6/bin
zkServer.sh start
5), 链接内存数据库, 通过get 和ls 等命令可查看数据库中的内容
zkCli.sh
zookeeper启动后, 就不要关闭了...
zk启动脚本:
脚本启动不管用的, 把环境变量配置在 ~/.bashrc下, 因为ssh分为登陆和非登陆, 读取配置文件的顺序不同
#!/bin/bash
host=(node2 node3 node4) start() {
for i in ${host[@]}
do
echo start $i
ssh -o StrictHostKeyChecking=no root@$i "/usr/local/zookeeper-3.4.11/bin/zkServer.sh start"
ssh -o StrictHostKeyChecking=no root@$i "jps"
echo start $i done
done
} stop() {
for i in ${host[@]}
do
echo stop $i
ssh -o StrictHostKeyChecking=no root@$i "/usr/local/zookeeper-3.4.11/bin/zkServer.sh stop"
ssh -o StrictHostKeyChecking=no root@$i "jps"
echo stop $i done
done
} case "$1" in start)
start
;; stop)
stop
;; *)
echo "Usage: start|stop"
;; esac
2, 修改hdfs的配置文件
2.1), 删除masters, 不需要SNN了
rm -rf /usr/opt/hadoop-2.5./etc/hadoop
2.2) 删除原集群中的数据文件
rm -rf /opt/hadoop
2.3) hdfs-site.xml
servername, zookeeper 使用
<property>
<name>dfs.nameservices</name>
<value>hdfscluster</value>
</property>
节点协议( 有几个nameNode定义几个)
<property>
<name>dfs.ha.namenodes.hdfscluster</name>
<value>nn1,nn2</value>
</property>
rpc协议( 文件上传下载使用)
<property>
<name>dfs.namenode.rpc-address.hdfscluster.nn1</name>
<value>192.168.208.106:</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hdfscluster.nn2</name>
<value>192.168.208.107:</value>
</property>
http协议
<property>
<name>dfs.namenode.http-address.hdfscluster.nn1</name>
<value>192.168.208.:</value>
</property>
<property>
<name>dfs.namenode.http-address.hdfscluster.nn2</name>
<value>192.168.208.:</value>
</property>
qjm节点, journalNodes节点, 用于缓存edits文件, uri, 分号隔开
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://192.168.208.107:8485;192.168.208.108:8485;192.168.208.109:8485/hdfscluster</value>
</property>
帮助客户端获得activeNameNode
<property>
<name>dfs.client.failover.proxy.provider.hdfscluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
远程登陆, 需要ssh密钥文件
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property> <property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
journalNode 数据存放的目录
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/journalNode/data</value>
</property>
2.4) core-site.xml, 修改下入口即可
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdfscluster</value>
</property>
3, 启用自动切换
3.1), hdfs-site.xml
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
3.2), core-site.xml, 更改一个配置即可, hadoop.tmp.dir仍然保留
<property>
<name>ha.zookeeper.quorum</name>
<value>192.168.208.106:,192.168.208.107:,192.168.208.108:</value>
</property>
4, 启动journalNode
hadoop-daemon.sh start journalnode
查看日志检查是否成功启动
停止: hadoop-daemon.sh stop journalnode
lgos/hadoop-root-journalnode-node4.log
5, 格式化其中一个NN
hdfs namenode -format
6, 拷贝fsimage 到另一台 NN上, 或者手动拷贝过去也可以
#启动刚刚格式化的NN
hadoop-daemon.sh start namenode
#在没有格式化的NN上执行
hdfs namenode -bootstrapStandby
#启动第二个NN
hadoop-daemon.sh start namenode
7, 初始化zookeeper, 在active的NN上执行
hdfs zkfc -formatZK
8, 启动
start-dfs.sh
排错时, 可用jps命令查看集群端口号, 然后kill -9, 或者 killall java
ps: 记得上个博客的配置, slaves等
以后启动时, 先启动3台zookeeper, 然后 start-dfs.sh 即可以了
非常坑, 因为私钥文件root前面没有加 / 表明根目录, 卡了一个小时!!!!
系列来自尚学堂
11-hdfs-NameNode-HA-wtihQJM解决单点故障问题的更多相关文章
- HDFS NameNode HA 部署文档
简介: HDFS High Availability Using the Quorum Journal Manager Hadoop 2.x 中,HDFS 组件有三个角色:NameNode.DataN ...
- Apache hadoop namenode ha和yarn ha ---HDFS高可用性
HDFS高可用性Hadoop HDFS 的两大问题:NameNode单点:虽然有StandbyNameNode,但是冷备方案,达不到高可用--阶段性的合并edits和fsimage,以缩短集群启动的时 ...
- HDFS namenode 高可用(HA)搭建指南 QJM方式 ——本质是多个namenode选举master,用paxos实现一致性
一.HDFS的高可用性 1.概述 本指南提供了一个HDFS的高可用性(HA)功能的概述,以及如何配置和管理HDFS高可用性(HA)集群.本文档假定读者具有对HDFS集群的组件和节点类型具有一定理解.有 ...
- HDFS的HA(高可用)
HDFS的HA(高可用) 概述 (1)实现高可用最关键的策略是[消除单点故障].HA 严格来说应该分成各个组件的 HA 机制:HDFS 的 HA 和 YARN 的 HA. (2)Hadoop2.0 之 ...
- hadoop2—namenode—HA原理详解
在hadoop1中NameNode存在一个单点故障问题,也就是说如果NameNode所在的机器发生故障,那么整个集群就将不可用(hadoop1中有个SecorndaryNameNode,但是它并不是N ...
- CDH4.1基于Quorum-based Journaling的NameNode HA
几个星期前, Cloudera发布了CDH 4.1最新的更新版本,这是第一个真正意义上的独立高可用性HDFS NameNode的hadoop版本,不依赖于特殊的硬件或外部软件.这篇文章从开发者的角度来 ...
- Hadoop2.0 Namenode HA实现方案
Hadoop2.0 Namenode HA实现方案介绍及汇总 基于社区最新release的Hadoop2.2.0版本,调研了hadoop HA方面的内容.hadoop2.0主要的新特性(Hadoop2 ...
- Hadoop2之NameNode HA详解
在Hadoop1中NameNode存在一个单点故障问题,如果NameNode所在的机器发生故障,整个集群就将不可用(Hadoop1中虽然有个SecorndaryNameNode,但是它并不是NameN ...
- 通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置
通过tarball形式安装HBASE Cluster(CDH5.0.2)——Hadoop NameNode HA 切换引起的Hbase错误,以及Hbase如何基于NameNode的HA进行配置 配置H ...
随机推荐
- codeforces 702C Cellular Network 2016-10-15 18:19 104人阅读 评论(0) 收藏
C. Cellular Network time limit per test 3 seconds memory limit per test 256 megabytes input standard ...
- LINUX中关于SIGNAL的定义
/* Signals. */ #define SIGHUP 1 /* Hangup (POSIX). */ #define SIGINT 2 /* Interrupt (ANSI). */ #defi ...
- CAS实战の遇到的问题
1.客户端启动报错,报错信息如下: 严重: Exception starting filter CAS Single Sign Out Filter java.lang.IllegalArgument ...
- maven下@override标签失效
经常遇见此问题,现记录如下,以备下次查阅. 在pom文件添加配置: <plugin> <groupId>org.apache.maven.plugins</groupId ...
- 通过keepalived搭建MySQL双主模式的高可用集群系统
1. 配置MySQL双主模式 1.修改my.cnf配置文件 默认情况下,MySQL的配置文件是/etc/my.cnf,在配置文件的[mysqld]段添加如下内容: server-id=1 log-bi ...
- [c# 20问] 4.Console应用获取执行路径
一行代码可以搞定了~ static void GetAppPath() { string path = System.Reflection.Assembly.GetExecutingAssembly( ...
- MvcPager分页控件使用注意事项!
初学MVC,做了个单页面应用,需要显示多个分页,并无刷新更新. 找到了MvcPager控件,非常好用,在使用ajax过程中遇到很多问题.慢慢调试和杨老师(MvcPaegr作者)请教,总于都解决了. 首 ...
- win 10 mysql8.0安装
1.解压缩安装包(记住自己的解压到那个目录,后面需要) 2.找到此电脑,然后找到属性(小编这里win10) 3.点击左侧高级系统设置 4.选择下面的环境变量 5.选择下面的新建,然后看图片,上面输入M ...
- Windows 环境下使用强大的wget工具
安装 下载[http://www.interlog.com/~tcharron/wgetwin.html] 解压到目录 比如我解压到D:\Tool\wget 添加wget环境变量,这样使用就更方便了, ...
- asp.net mvc 5 初体验
参考:http://www.asp.net/mvc/tutorials/mvc-5/introduction/getting-started 1. 新建 ASP.Net Web 应用程序,跟着向导一路 ...