Selenium2+python自动化41-绕过验证码(add_cookie)
前言
验证码这种问题是比较头疼的,对于验证码的处理,不要去想破解方法,这个验证码本来就是为了防止别人自动化登录的。如果你能破解,说明你们公司的验证码吗安全级别不高,那就需要提高级别了。
对于验证码,要么是让开发在测试环境弄个万能的验证码,如:1234,要么就是尽量绕过去,如本篇介绍的添加cookie的方法。
一、fiddler抓包
1.前一篇讲到,登录后会生成一个已登录状态的cookie,那么只需要直接把这个值添加到cookies里面就可以了。
2.可以先手动登录一次,然后抓取这个cookie,这里就需要用抓包工具fiddler了
3.先打开博客园登录界面,手动输入账号和密码(不要点登录按钮)
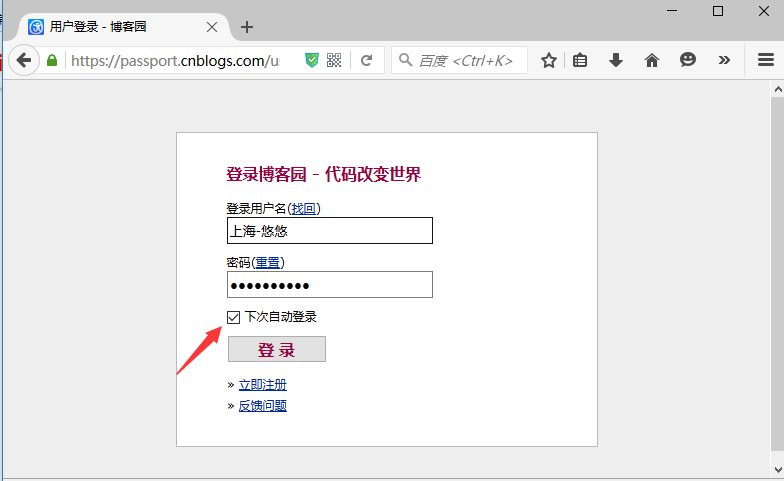
4.打开fiddler抓包工具,此时再点博客园登录按钮
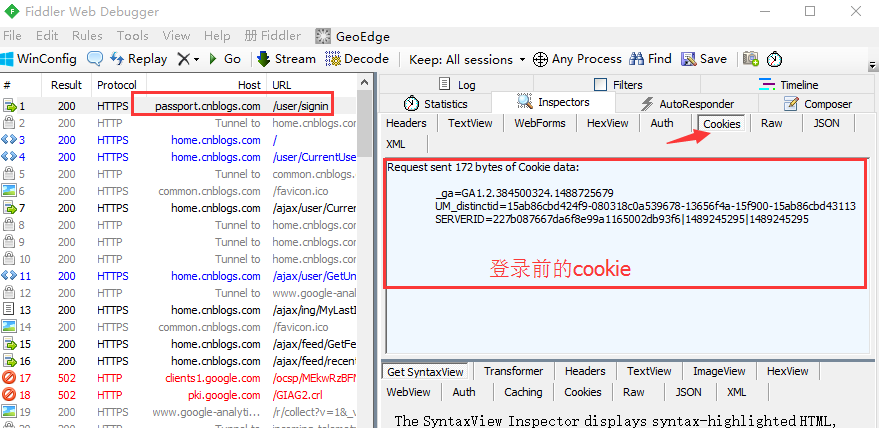
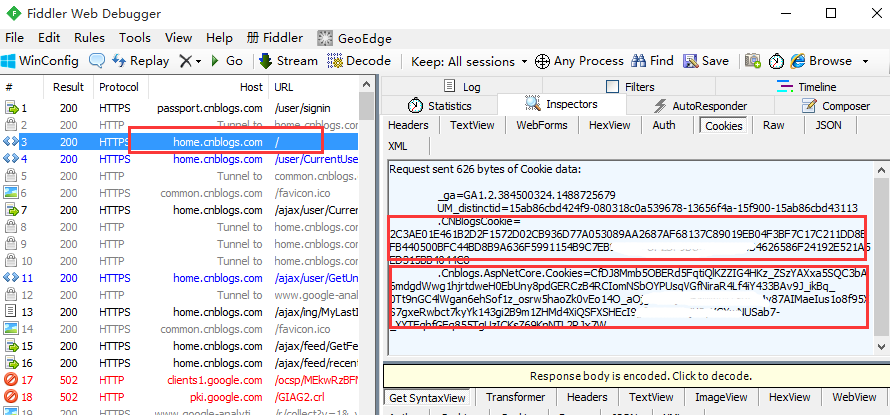
5.登录成功后,再查看cookie变化,发现多了两组参数,多的这两组参数就是我们想要的,copy出来,一会有用
二、添加cookie方法:driver.add_cookie()
1.add_cookie(cookie_dict)方法里面参数是cookie_dict,说明里面参数是字典类型。
2.源码官方文档介绍:
add_cookie(self, cookie_dict)
Adds a cookie to your current session.
:Args:
- cookie_dict: A dictionary object, with required keys - "name" and "value";
optional keys - "path", "domain", "secure", "expiry"
Usage:
driver.add_cookie({'name' : 'foo', 'value' : 'bar'})
driver.add_cookie({'name' : 'foo', 'value' : 'bar', 'path' : '/'})
driver.add_cookie({'name' : 'foo', 'value' : 'bar', 'path' : '/', 'secure':True})
3.从官方的文档里面可以看出,添加cookie时候传入字典类型就可以了,等号左边的是name,等号左边的是value。
4.把前面抓到的两组数据(参数不仅仅只有name和value),写成字典类型:
{'name':'.CNBlogsCookie','value':'2C3AE01E461B2D2F1572D02CB936D77A053089AA2xxxx...'}
{'name':'.Cnblogs.AspNetCore.Cookies','value':'CfDJ8Mmb5OBERd5FqtiQlKZZIG4HKz_Zxxx...'}
三、cookie组成结构
1.用抓包工具fidller只能看到cookie的name和value两个参数,实际上cookie还有其它参数
2.cookie参数组成,以下参数是我通过get_cookie(name)获取到的,
参考上一篇:Selenium2+python自动化40-cookie相关操作
cookie ={u'domain': u'.cnblogs.com',
u'name': u'.CNBlogsCookie',
u'value': u'xxxx',
u'expiry': 1491887887,
u'path': u'/',
u'httpOnly': True,
u'secure': False}
name:cookie的名称
value:cookie对应的值,动态生成的
domain:服务器域名
expiry:Cookie有效终止日期
path:Path属性定义了Web服务器上哪些路径下的页面可获取服务器设置的Cookie
httpOnly:防脚本攻击
secure:在Cookie中标记该变量,表明只有当浏览器和Web Server之间的通信协议为加密认证协议时,
浏览器才向服务器提交相应的Cookie。当前这种协议只有一种,即为HTTPS。
四、添加cookie
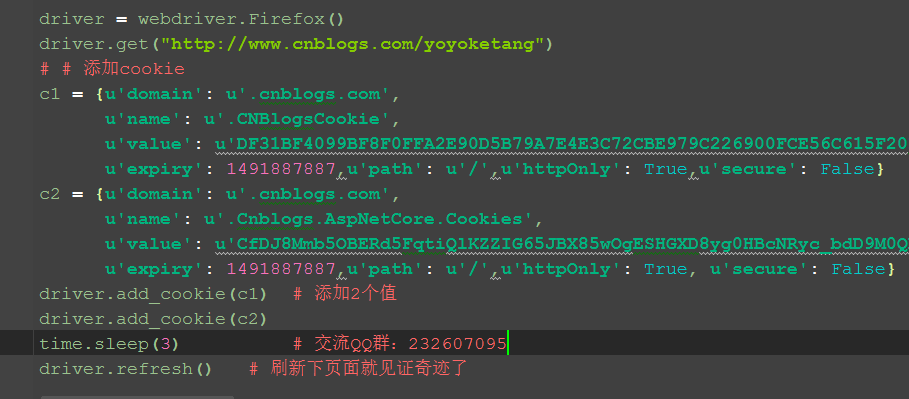
1.这里需要添加两个cookie,一个是.CNBlogsCookie,另外一个是.Cnblogs.AspNetCore.Cookies。
2.我这里打开的网页是博客的主页:http://www.cnblogs.com/yoyoketang,没进入登录页。
3.添加cookie后刷新页面,接下来就是见证奇迹的时刻了。
五、参考代码:
# coding:utf-8
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.get("http://www.cnblogs.com/yoyoketang")
# # 添加cookie
c1 = {u'domain': u'.cnblogs.com',
u'name': u'.CNBlogsCookie',
u'value': u'xxxx',
u'expiry': 1491887887,
u'path': u'/',
u'httpOnly': True,
u'secure': False}
c2 = {u'domain': u'.cnblogs.com',
u'name': u'.Cnblogs.AspNetCore.Cookies',
u'value': u'xxxx',
u'expiry': 1491887887,
u'path': u'/',
u'httpOnly': True,
u'secure': False}
driver.add_cookie(c1) # 添加2个值
driver.add_cookie(c2)
time.sleep(3) # 交流QQ群:232607095
# 刷新下页面就见证奇迹了
driver.refresh()
有几点需要注意:
1.登录时候要勾选下次自动登录按钮。
2.add_cookie()只添加name和value,对于博客园的登录是不成功。
3.本方法并不适合所有的网站,一般像博客园这种记住登录状态的才会适合。
学习过程中有遇到疑问的,可以加selenium(python+java) QQ群交流:646645429
另外成立了python接口自动化QQ群:226296743
selenium+python高级教程》已出书:selenium webdriver基于Python源码案例
(购买此书送对应PDF版本)

Selenium2+python自动化41-绕过验证码(add_cookie)的更多相关文章
- Selenium2+python自动化41-绕过验证码(add_cookie)【转载】
前言 验证码这种问题是比较头疼的,对于验证码的处理,不要去想破解方法,这个验证码本来就是为了防止别人自动化登录的.如果你能破解,说明你们公司的验证码吗安全级别不高,那就需要提高级别了. 对于验证码,要 ...
- Selenium2+python自动化13-Alert
不是所有的弹出框都叫alert,在使用alert方法前,先要识别出它到底是不是alert.先认清楚alert长什么样子,下次碰到了,就可以用对应方法解决.alert\confirm\prompt弹出框 ...
- Python Selenium Cookie 绕过验证码实现登录
Python Selenium Cookie 绕过验证码实现登录 之前介绍过博客园的通过cookie 绕过验证码实现登录的方法.这里并不多余,会增加分析和另外一种方法实现登录. 1.思路介绍 1.1. ...
- Selenium2+python自动化23-富文本(自动发帖)
前言 富文本编辑框是做web自动化最常见的场景,有很多小伙伴遇到了不知道无从下手,本篇以博客园的编辑器为例,解决如何定位富文本,输入文本内容 一.加载配置 1.打开博客园写随笔,首先需要登录,这里为了 ...
- Selenium2+python自动化24-js处理富文本(带iframe)
前言 上一篇Selenium2+python自动化23-富文本(自动发帖)解决了富文本上iframe问题,其实没什么特别之处,主要是iframe的切换,本篇讲解通过js的方法处理富文本上iframe的 ...
- Selenium2+python自动化7-xpath定位
前言 在上一篇简单的介绍了用工具查看目标元素的xpath地址,工具查看比较死板,不够灵活,有时候直接复制粘贴会定位不到.这个时候就需要自己手动的去写xpath了,这一篇详细讲解xpath的一些语法. ...
- Selenium2+python自动化28-table定位
前言 在web页面中经常会遇到table表格,特别是后台操作页面比较常见.本篇详细讲解table表格如何定位. 一.认识table 1.首先看下table长什么样,如下图,这种网状表格的都是table ...
- Selenium2+python自动化43-判断title(title_is)
From: https://www.cnblogs.com/yoyoketang/p/6539117.html 前言 获取页面title的方法可以直接用driver.title获取到,然后也可以把获取 ...
- Selenium2+python自动化54-unittest生成测试报告(HTMLTestRunner)
前言 批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLT ...
随机推荐
- 分析Windows的死亡蓝屏(BSOD)机制
这篇文章本来是投Freebuf的,结果没过.就贴到博客里吧,图懒得发上来了 对于Windows系统来说,被人们视为洪水猛兽的蓝屏也是一种有利于系统稳定的机制.蓝屏其实是Windows系 统的一种自查机 ...
- luogu P1126 机器人搬重物 题解
luogu P1126 机器人搬重物 题解 题目描述 机器人移动学会(\(RMI\))现在正尝试用机器人搬运物品.机器人的形状是一个直径\(1.6\)米的球.在试验阶段,机器人被用于在一个储藏室中搬运 ...
- Inno setup 常用修改技巧
Inno setup 常用修改技巧1 .如何让协议许可页面默认选中我同意按钮 [code]procedure InitializeWizard();beginWizardForm.LICENSEACC ...
- C++中bool类型变量初值对程序的影响
很困惑的一个问题 #include<iostream> using namespace std; int main() { //bool a=true; //非0(1,2,3,……)输出1 ...
- 7-10 守卫棋盘 uva11214
输入要给n*m的棋盘 均小于10 某些格子有标记 用最少的皇后 辐射到所有的标记 限时 6666ms 用IDA* 时间6000 尴尬. #include<bits/stdc++ ...
- react篇章-React State(状态)-数据自顶向下流动
<!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <title&g ...
- C#语法文本字面量
C#语法文本字面量 在日常生活中,文本用来表示除了数字以外的内容.例如有一个叫“比尔”的人,他的职位为“科长”.那么,“比尔”和“科长”都可以称为文本.在计算机里,现实世界中的文本通常被称为字符和字符 ...
- Django一些开发经验
总结一些 Django 开发的小经验.先说一些最最基础的吧. 使用 virtualenv 隔离开发环境 使用 pip 管理项目依赖,主要就是一个小技巧,使用 pip freeze > requi ...
- 为什么全部width:100%浏览器边缘存在留白?
一般浏览器都给body加了外边距,margin:0应该能解决你所遇到的问题.但你很可能又会遇到其他奇怪的现象,比如说p的行高,在不同浏览器上显示不一致,最根本的解决方案还是重置浏览器默认样式. 可以使 ...
- Where should we fork this repository?
韩梦飞沙 韩亚飞 313134555@qq.com yue31313 han_meng_fei_sha 我们应该在哪里分叉这个存储库? Where should we fork this re ...