【Kafka】《Kafka权威指南》——提交和偏移量
KafkaConsumer(消费者)每次调用 poll()方法,它总是返回由生产者写入 Kafka但还没有被消费者读取过的记录, 我们因 此可以追踪到哪些记录是被群组里的哪个消费者读取的。之前已经讨论过, Kafka 不会像其他 JMS 队列那样需要得到消费者的确认,这是 Kafka 的一个独特之处。相反,消 费者可以使用 Kafka来追踪消息在分区里的位置(偏移量)。
我们把更新分区当前位置的操作叫作提交。
那么消费者是如何提交偏移量的呢?消费者往一个 叫作 _consumer_offset 的特殊主题发送 消息,消息里包含每个分区的偏移量。 如果消费者一直处于运行状态,那么偏移量就没有 什么用处。不过,如果悄费者发生崩溃或者有新 的消费者加入群组,就会触发再均衡,完 成再均衡之后,每个消费者可能分配到新 的分区,而不是之前处理的那个。为了能够继续 之前的工作,消费者需要读取每个分区最后一次提交 的偏移量,然后从偏移量指定的地方 继续处理。
如果提交的偏移量小于客户端处理 的最后一个消息的偏移量 ,那么处于两个偏移量之间的 消息就会被重复处理,如图 4-6所示。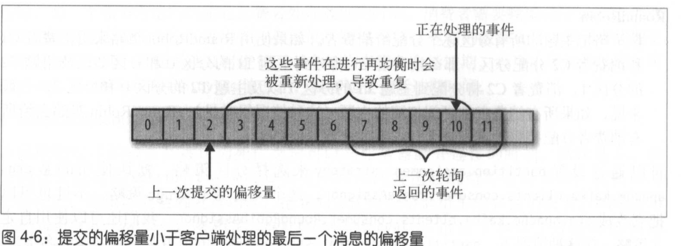
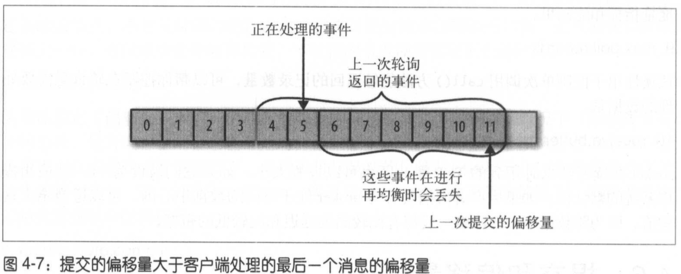
如果提交的偏移量大于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的 消息将会丢失,如图 4-7 所示。
所以,处理偏移量的方式对客户端会有很大的影响。 KafkaConsumer API提供了很多种方式来提交偏移量。
自动提交
最简单的提交方式是让悄费者自动提交偏移量。如果enable.auto.commit被设为 true,那么每过5s,消费者会自动把从 poll() 方法接收到的最大偏移量提交上去。提交时间间隔由 auto.commit.interval.ms 控制,默认值是 5s。与消费者里的其他东西 一样,自动提交也是在轮询(poll() )里进行的。消费者每次在进行轮询时会检查是否该提交偏移量了,如果是,那 么就会提交从上一次轮询返回的偏移量。
不过,在使用这种简便的方式之前,需要知道它将会带来怎样的结果。
假设我们仍然使用默认的 5s提交时间间隔,在最近一次提交之后的 3s发生了再均衡,再 均衡之后,消费者从最后一次提交的偏移量位置开始读取消息。这个时候偏移量已经落后 了 3s,所以在这 3s 内到达的消息会被重复处理。可以通过修改提交时间间隔来更频繁地提交偏移量,减小可能出现重复消息的时间窗,不过这种情况是无也完全避免的 。
在使用自动提交时 ,每次调用轮询方怯都会把上一次调用返 回的偏移量提交上去,它并不 知道具体哪些消息已经被处理了,所以在再次调用之前最好确保所有当前调用返回 的消息 都已经处理完毕(在调用 close() 方法之前也会进行自动提交)。 一般情况下不会有什么问 题,不过在处理异常或提前退出轮询时要格外小心 。
自动提交虽然方便 , 不过并没有为开发者留有余地来避免重复处理消息。
提交当前偏移量
大部分开发者通过控制偏移量提交时间来消除丢失消息的可能性,井在发生再均衡时减少 重复消息的数量。消费者 API提供了另一种提交偏移量的方式 , 开发者可以在必要的时候 提交当前偏移盘,而不是基于时间间隔。
取消自动提交,把 auto.commit.offset 设为 false,让应用程序决定何时提交 偏 移量。使用 commitSync() 提交偏移量最简单也最可靠。这个 API会提交由 poll() 方法返回 的最新偏移量,提交成 功后马上返回,如果提交失败就抛出异常。
要记住, commitSync() 将会提交由 poll() 返回的最新偏移量 , 所以在处理完所有记录后要 确保调用了 commitSync(),否则还是会有丢失消息的风险。如果发生了再均衡,从最近一 批消息到发生再均衡之间的所有消息都将被重复处理。
下面是我们在处理完最近一批消息后使用 commitSync() 方法提交偏移量的例子。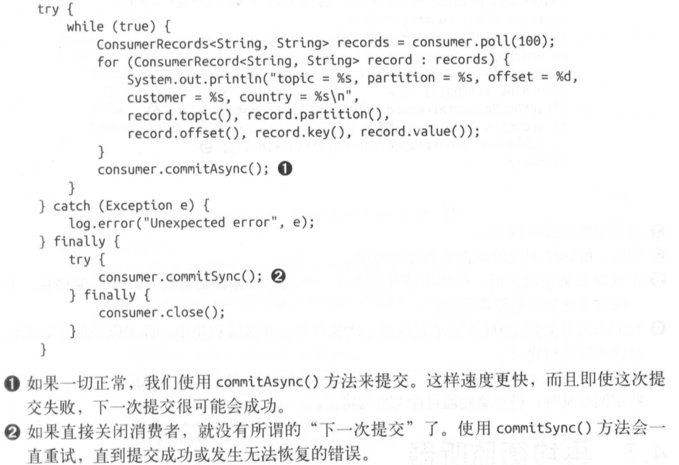
异步提交
同步提交有一个不足之处,在 broker对提交请求作出回应之前,应用程序会一直阻塞,这样会限制应用程序的吞吐量。我们可以通过降低提交频率来提升吞吐量,但如果发生了再均衡, 会增加重复消息的数量。
这个时候可以使用异步提交 API。我们只管发送提交请求,无需等待 broker的响应。
在成功提交或碰到无怯恢复的错误之前, commitSync() 会一直重试(应用程序也一直阻塞),但是 commitAsync() 不会,这也是 commitAsync() 不好的 一个地方。它之所以不进行重试,是因为在它收到 服务器响应的时候,可能有一个更大的偏移量已经提交成功。假设我们发出一个请求用于提交偏移量 2000,这个时候发生了短暂的通信问题 ,服务器收不到请求,自然也不会 作出任何响应。与此同时,我们处理了另外一批消息,并成功提交了偏移量 3000。如果 commitAsync() 重新尝试提交偏移量 2000,它有可能在偏移量 3000之后提交成功。这个时 候如果发生再均衡,就会出现重复消息。
我们之所以提到这个问题的复杂性和提交顺序的重要性,是因为 commitAsync()也支持回 调,在 broker 作出响应时会执行回调。回调经常被用于记录提交错误或生成度量指标, 不 过如果你要用它来进行重试, 一定要注意提交的顺序。
重试异步提交
我们可以使用一个单调递增的序列号来维护异步提交的顺序。在每次提交偏 移量之后或在回调里提交偏移量时递增序列号。在进行重试前,先检查回调 的序列号和即将提交的偏移量是否相等,如果相等,说明没有新的提交,那么可以安全地进行重试。如果序列号比较大,说明有一个新的提交已经发送出去了,应该停止重试。
同步和异步组合提交
一般情况下,针对偶尔出现的提交失败,不进行重试不会有太大问题,因为如果提交失败 是 因为临时问题导致的,那么后续的提交总会有成功的。但如果这是发生在关闭消费者或 再均衡前的最后一次提交,就要确保能够提交成功。
因此,在消费者关闭前一般会组合使用 commitAsync()和 commitSync()。它们的工作原理如下(后面讲到再均衡监听器时,我们会讨论如何在发生再均衡前提交偏移量):
提交特定的偏移量
提交偏移量的频率与处理消息批次的频率是一样的。但如果想要更频繁地提交出怎么办?如果 poll() 方法返回一大批数据,为了避免因再均衡引起的重复处理整批消息,想要在批次中间提交偏移量该怎么办?这种情况无法通过调用 commitSync()或 commitAsync() 来实现,因为它们只会提交最后一个偏移量,而此时该批次里的消息还没有处理完。
幸运的是,消费者 API 允许在调用 commitSync()和 commitAsync()方法时传进去希望提交 的分区和偏移量的 map。假设你处理了半个批次的消息, 最后一个来自主题“customers” 分区 3 的消息的偏移量是 5000, 你可以调用 commitSync() 方法来提交它。不过,因为消费者可能不只读取一个分区, 你需要跟踪所有分区的偏移量,所以在这个层面上控制偏移 量 的提交会让代码变复杂。
下面是提交特定偏移量的例子 :

再均衡监听器
在提交偏移量一节中提到过,消费者在退出和进行分区再均衡之前,会做一些清理工作。
你会在消费者失去对一个分区的所有权之前提交最后一个已处理记录的偏移量。如果消费 者准备了 一 个缓冲区用于处理偶发的事件,那么在失去分区所有权之前, 需要处理在缓冲 区累积下来的记录。你可能还需要关闭文件句柄、数据库连接等。
在为消费者分配新分区或移除旧分区时,可以通过消费者 API执行 一 些应用程序代码,在调用 subscribe()方法时传进去一个ConsumerRebalancelistener实例就可以了。 ConsumerRebalancelistener有两个需要实现的方法。
(1) public void onPartitionsRevoked(Collection<TopicPartition> partitions)方法会在 再均衡开始之前和消费者停止读取消息之后被调用。如果在这里提交偏移量,下一个接 管分区 的消费者就知道该从哪里开始读取了。
(2) public void onPartitionsAssigned(Collection<TopicPartition> partitions)方法会在 重新分配分区之后和消费者开始读取消息之前被调用。
下面的例子将演示如何在失去分区所有权之前通过 onPartitionsRevoked()方法来提交偏移量。在下一节,我们会演示另一个同时使用了 onPartitionsAssigned()方法的例子。

从特定偏移量处开始处理记录
到目前为止,我们知道了如何使用 poll() 方法从各个分区的最新偏移量处开始处理消息。 不过,有时候我们也需要从特定的偏移量处开始读取消息。
如果你想从分区的起始位置开始读取消息,或者直接跳到分区的末尾开始读取消息, 可以使 用 seekToBeginning(Collection<TopicPartition> tp) 和 seekToEnd(Collection<TopicPartition> tp) 这两个方法。
不过, Kafka也为我们提供了用 于查找特定偏移量的 API。 它有很多用途,比如向 后回退 几个消息或者向前跳过几个消息(对时间比较敏感的应用程序在处理滞后的情况下希望能 够向前跳过若干个消息)。在使用 Kafka 以外的系统来存储偏移量时,它将给我们 带来更 大的惊喜。
试想一下这样的场景:应用程序从 Kafka读取事件(可能是网站的用户点击事件流 ),对 它们进行处理(可能是使用自动程序清理点击操作井添加会话信息),然后把结果保 存到 数据库、 NoSQL 存储引擎或 Hadoop。假设我们真的不想丢失任何数据,也不想在数据库 里多次保存相同的结果。
这种情况下,消费者的代码可能是这样的 :
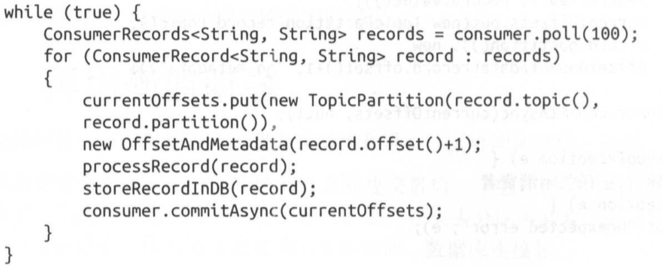
在这个例子里,每处理一条记录就提交一次偏移量。尽管如此, 在记录被保存到数据库之后以及偏移量被提交之前 ,应用程序仍然有可能发生崩溃,导致重复处理数据,数据库里就会出现重复记录。
如果保存记录和偏移量可以在一个原子操作里完成,就可以避免出现上述情况。记录和偏 移量要么 都被成功提交,要么都不提交。如果记录是保存在数据库里而偏移量是提交到 Kafka 上,那么就无法实现原子操作。
不过 ,如果在同一个事务里把记录和偏移量都写到数据库里会怎样呢?那么我们就会知道 记录和偏移量要么都成功提交,要么都没有,然后重新处理记录。
现在的问题是:如果偏移量是保存在数据库里而不是 Kafka里,那么消费者在得到新分区 时怎么知道该从哪里开始读取?这个时候可以使用 seek() 方法。在消费者启动或分配到新 分区时 ,可以使用 seek()方法查找保存在数据库里的偏移量。
下面的例子大致说明了如何使用这个 API。 使用 ConsumerRebalancelistener和 seek() 方 战确保我们是从数据库里保存的偏移量所指定的位置开始处理消息的。

通过把偏移量和记录保存到同 一个外部系统来实现单次语义可以有很多种方式,不过它们 都需要结合使用 ConsumerRebalancelistener和 seek() 方法来确保能够及时保存偏移量, 井保证消费者总是能够从正确的位置开始读取消息。
如何退出
在之前讨论轮询时就说过,不需要担心消费者会在一个无限循环里轮询消息,我们会告诉消费者如何优雅地退出循环。
如果确定要退出循环,需要通过另一个线程调用 consumer.wakeup()方法。如果循环运行 在主线程里,可以在 ShutdownHook里调用该方法。要记住, consumer.wakeup() 是消费者 唯一一个可以从其他线程里安全调用的方法。调用 consumer.wakeup()可以退出 poll(), 并抛出 WakeupException异常,或者如果调用 cconsumer.wakeup() 时线程没有等待轮询, 那 么异常将在下一轮调用 poll()时抛出。我们不需要处理 WakeupException,因为它只是用于跳出循环的一种方式。不过, 在退出线程之前调用 consumer.close()是很有必要的, 它 会提交任何还没有提交的东西 , 并向群组协调器(broker)发送消息,告知自己要离开群组,接下来 就会触发再均衡 ,而不需要等待会话超时。
下面是运行在主线程上的消费者退出线程的代码 。

【Kafka】《Kafka权威指南》——提交和偏移量的更多相关文章
- Kafka权威指南——broker的常用配置
前面章节中的例子,用来作为单个节点的服务器示例是足够的,但是如果想要把它应用到生产环境,就远远不够了.在Kafka中有很多参数可以控制它的运行和工作.大部分的选项都可以忽略直接使用默认值就好,遇到一些 ...
- 《Kafka权威指南》读书笔记-操作系统调优篇
<Kafka权威指南>读书笔记-操作系统调优篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 大部分Linux发行版默认的内核调优参数配置已经能够满足大多数应用程序的运 ...
- Kafka技术内幕 读书笔记之(三) 消费者:高级API和低级API——消费者消费消息和提交分区偏移量
消费者拉取钱程拉取每个分区的数据,会将分区的消息集包装成一个数据块( FetchedDataChunk )放入分区信息的队列中 . 而每个队列都对应一个消息流( KafkaStream ),消费者客户 ...
- Kafka权威指南 读书笔记之(五)深入Kafka
集中讨论以下3 个有意思的话题 :• Kafka 如何进行复制:• Kafka 如何处理来自生产者和消费者的请求 :• Kafka 的存储细节,比如文件格式和索引. 集群成员关系 Kafka 使用 Z ...
- Kafka权威指南 读书笔记之(四)Kafka 消费者一一从 Kafka读取数据
KafkaConsumer概念 消费者和消费者群组 Kafka 消费者从属于消费者群组.一个群组里的消费者订阅的是同一个主题,每个消费者接收主题一部分分区的消息. 往群组里增加消费者是横向伸缩消费能力 ...
- 【Kafka】《Kafka权威指南》——分区partition
在上篇的例子里([Kafka]<Kafka权威指南>--写数据), ProducerRecord 对象包含了目标主题.键和值. Kafka 的消息是 一个个 键值对, ProducerRe ...
- Kafka权威指南阅读笔记(第八章)
跨集群数据镜像 使用场景: 区域集群和中心集群 这种场景下,每个区域的应用程序只访问相应的区域内的集群.而有些情况下,需要将各个集群的信息汇总到中心集群,就可以用中心集群分析业务数据了. 冗余 一个K ...
- 【转】Spark Streaming和Kafka整合开发指南
基于Receivers的方法 这个方法使用了Receivers来接收数据.Receivers的实现使用到Kafka高层次的消费者API.对于所有的Receivers,接收到的数据将会保存在Spark ...
- Spark Streaming和Kafka整合开发指南(二)
在本博客的<Spark Streaming和Kafka整合开发指南(一)>文章中介绍了如何使用基于Receiver的方法使用Spark Streaming从Kafka中接收数据.本文将介绍 ...
随机推荐
- 洛谷 P2342 叠积木 题解
本蒟蒻又来发题解了 这题是不是有点像并查集,但是那个询问的个数是不是有点骚: 所以,普通的并查集是无法解决这个问题的,这个时候就需要用到带权并查集了: 每次跑的时候都记录下它的下面有几个点,然后询问的 ...
- luogu P3572 [POI2014]PTA-Little Bird |单调队列
从1开始,跳到比当前矮的不消耗体力,否则消耗一点体力,每次询问有一个步伐限制,求每次最少耗费多少体力 #include<cstdio> #include<cstring> #i ...
- [TimLinux] JavaScript position为fixed时支持水平滚动条
1. 固定定位 position: fixed;设置好之后,元素在浏览器窗口中的位置就固定住了,这个时候,不论是水平移动滚动条,还是垂直移动滚动条,元素是打死都不会动的. 但是当用fixed定位的元素 ...
- SPOJ Free TourII(点分治+启发式合并)
After the success of 2nd anniversary (take a look at problem FTOUR for more details), this 3rd year, ...
- R语言绘制KS曲线
更多大数据分析.建模等内容请关注公众号<bigdatamodeling> 将代码封装在函数PlotKS_N里,Pred_Var是预测结果,可以是评分或概率形式:labels_Var是好坏标 ...
- Linux-(3)Linux Shell 使用
三.Linux Shell 3.1 文件管理 3.1.1 ls 命令 显示指定工作目录下的内容及属性信息 ls 命令是Linux下最常用的指令之一.ls命令为英文单词 list 的缩写,正如英文单词 ...
- 【React】393 深入了解React 渲染原理及性能优化
如今的前端,框架横行,出去面试问到框架是常有的事. 我比较常用React, 这里就写了一篇 React 基础原理的内容, 面试基本上也就问这些, 分享给大家. React 是什么 React是一个专注 ...
- 伸缩容器-display:flex设置flex属性的理解
1.flex属性 1.1 flex属性是flex-grow, flex-shrink 和 flex-basis的简写,默认值为0 1 auto. flex-grow: 定义项目的放大比例,默认为0,即 ...
- 【Java Web开发学习】远程方法调用RMI
Java RMI 远程方法调用Remote Method Invocation 转载:http://www.cnblogs.com/yangchongxing/p/9078061.html 1.创建远 ...
- python爬虫--爬虫与反爬
爬虫与反爬 爬虫:自动获取网站数据的程序,关键是批量的获取. 反爬虫:使用技术手段防止爬虫程序的方法 误伤:反爬技术将普通用户识别为爬虫,从而限制其访问,如果误伤过高,反爬效果再好也不能使用(例如封i ...