Huffman树及其编解码
Huffman树——编解码
介绍:
Huffman树可以根据输入的字符串中某个字符出现的次数来给某个字符设定一个权值,然后可以根据权值的大小给一个给定的字符串编码,或者对一串编码进行解码,可以用于数据压缩或者解压缩,和对字符的编解码。
可是Huffman树的优点在哪?
1、就在于它对出现次数大的字符(即权值大的字符)的编码比出现少的字符编码短,也就是说出现次数越多,编码越短,保证了对数据的压缩。
2、保证编的码不会出现互相涵括,也就是不会出现二义性,比如a的编码是00100,b的编码是001,而c的编码是00,,这样的话,对于00100就可能是a,也可能是bc,而Huffman树编码方式不会出现这种问题。
如何实现
实现Huffman树的编解码需要三种数据类型,一个是优先级队列,用来保存树的结点,二是树,用来解码,三是表,用来当作码表编码。下面我们先一一介绍一下三种数据结构:
1、优先级队列
优先级队列里存放的是一个一个的树的结点,根据树结点中存放的字符的权值来确定其优先级,权重越小,优先级越小,放的位置越靠前。也就是说第一个结点存放的优先级最小,权值最小。
数据类型
//优先级队列,struct TNode表示树的结点,在后面介绍
typedef struct QNode
{
struct TNode* val; //树的结点,其实也就是数据域
int priority; //优先级
struct QNode* next; //指针域
}*Node;
typedef struct Queue
{
int size; //队列大小
struct QNode* front; //队列头指针
}queue;
2、树
树里面存放的是字符,以及指向自己的左右孩子结点的指针。比如下图,虽然下图中看起来书中存放了该字符的优先级,但其实可以不加,感觉比较繁琐,所以我取了,但是为了理解方便起见,我在图上标注了出来。
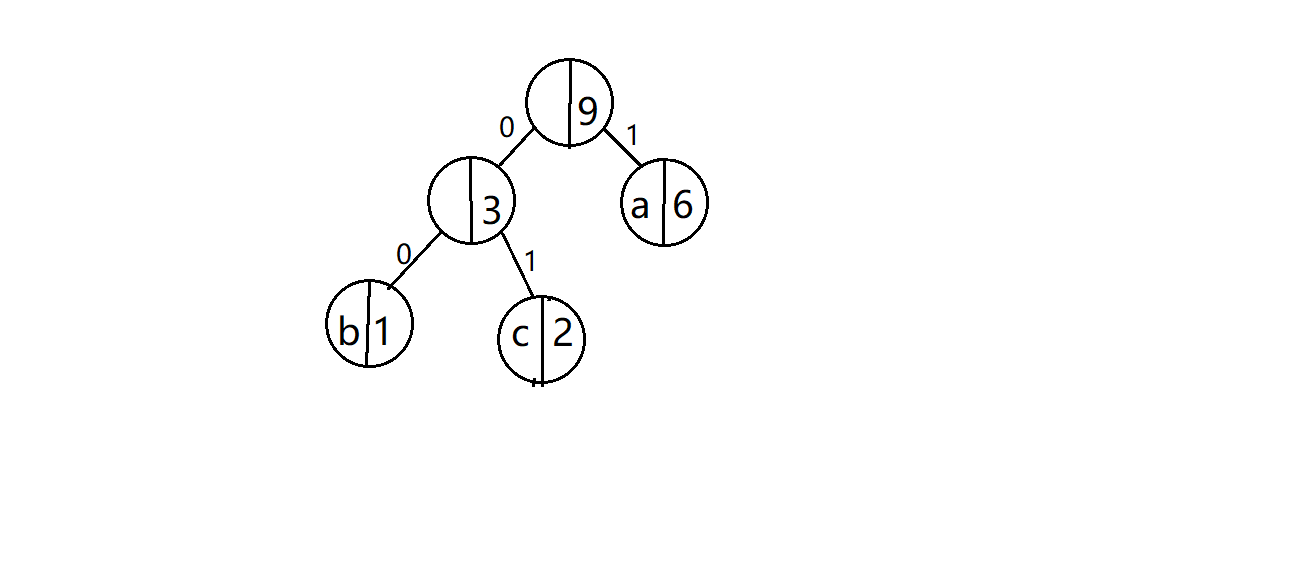
数据类型
//树
typedef struct TNode
{
char data; //字符值
struct TNode* left; //左孩子
struct TNode* right; //右孩子
}*Tree;
3、表
这个表其实就是一张编码表,里面存放了字符和该字符的编码,用于编码的时候查看。
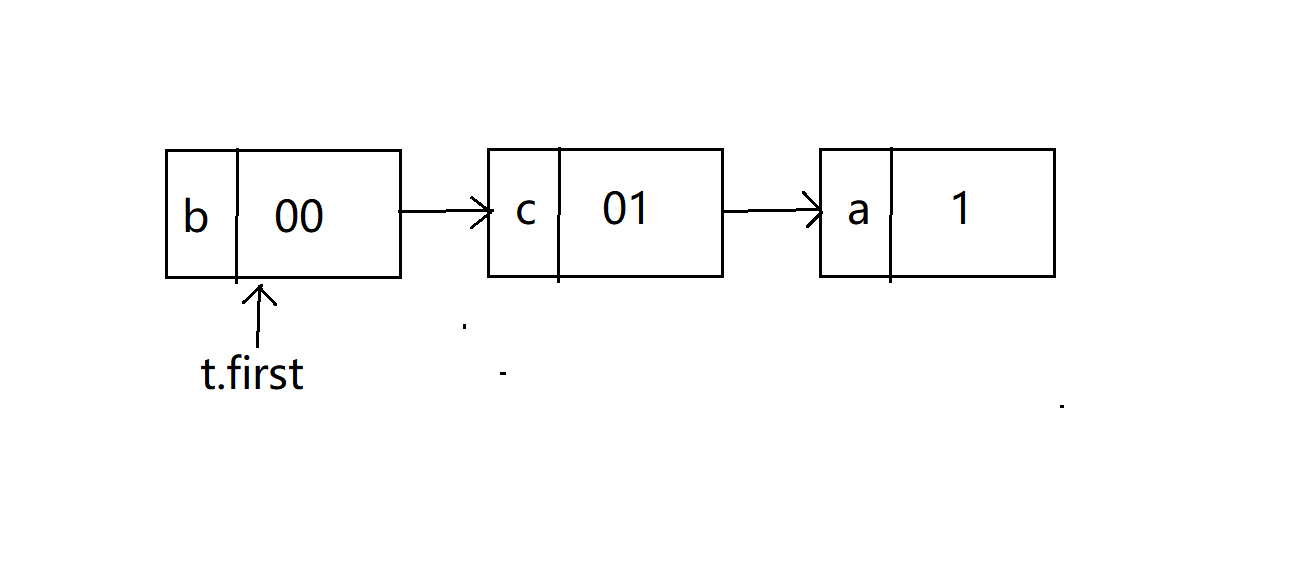
数据类型
//表
typedef struct BNode
{
char code[256]; //编码
char symbol; //字符
struct BNode* next; //指向下一个
}*bNode;
typedef struct Table
{
struct BNode* first; //表头
struct BNode* last; //表尾
}*table;
思路
为了简单起见我们讲述的时候就先将权值设置为用户输入而不是根据出现频率统计,因为我们作业也刚好是用户输入,文章最后我会贴出根据出现频率统计的代码,有兴趣可以看看。因为用到了很多数据类型所以可能写到一半会觉得有点晕,所以我们开始之前先理一下思路:
先设定a,b,c三个数据,它们的权值分别为6,1,2
1、首先要根据用户输入的每个字符的权值,创建出一个一个的树结点,然后将其按照优先级的大小存入优先级队列中,按从小到大的顺序,具体实现我会在后面贴。
2、根据优先级队列中存放的树的结点构建起一棵树。
先出队前两个结点,然后创建一个新的树的结点,新的树的结点的权值就等于出队的两个结点的权值之和,但其没有字符域,也就是说它不是一个真正的树的结点,我们称其为假树结点,对应称为真树结点。
让出队的两个真树结点作为新得到的假树结点的左右孩子,优先级小的真树结点(也就是先出队的真树结点)作为左孩子,另一个为右孩子。
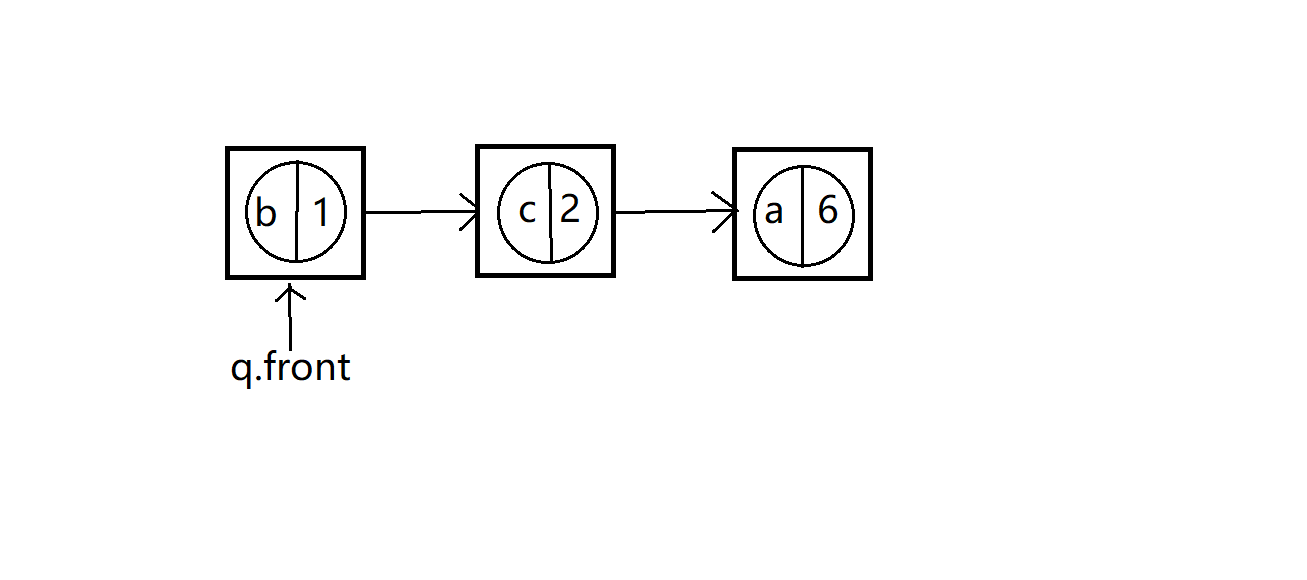
出队后
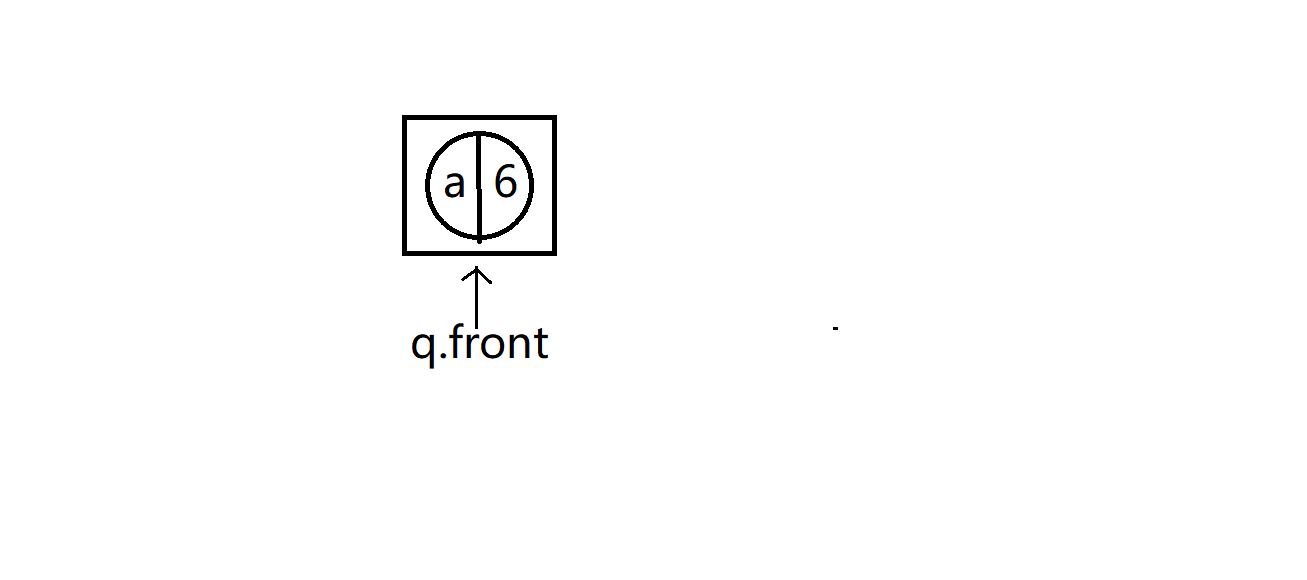
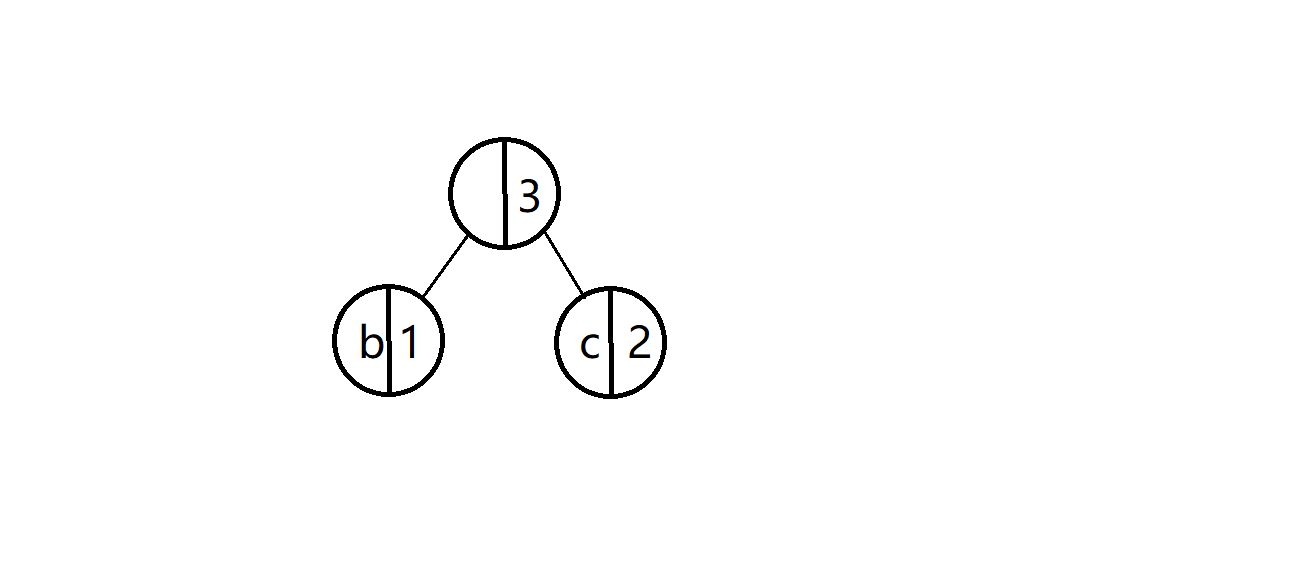
b和c为真树结点,最上面权值为3的为假树结点
最后将新创建的假树结点又入队,继续循环操作,直到队列只剩一个结点,那个结点就是假树结点,最后也要作为Huffman树的根节点root。
新的假树结点入队后
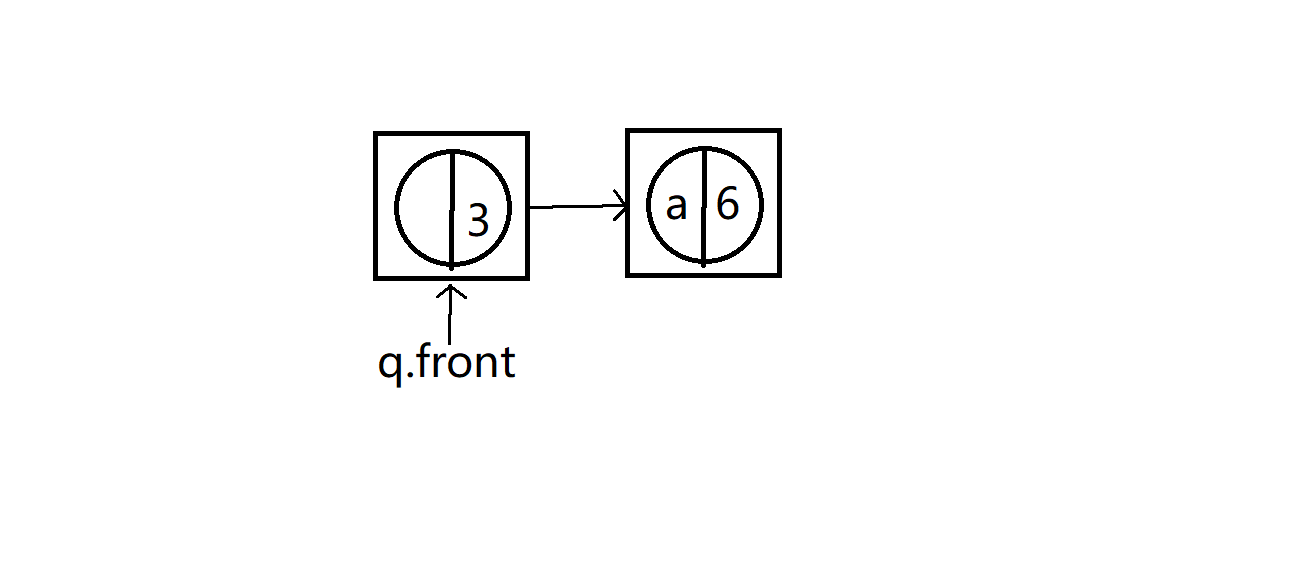
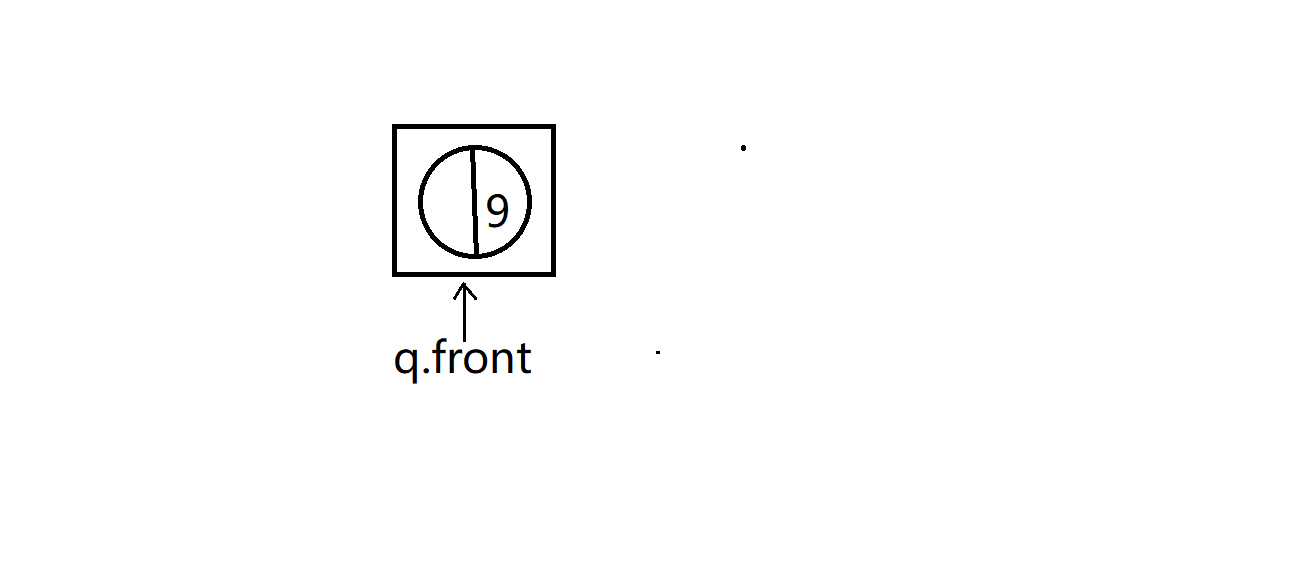
到最后就是下面这样
队列只剩最后一个假树结点,而且作为所构建Huffman树的根节点root
3、遍历整棵树建起一张码表,通过观察我们发现,真正有意义的真树结点其实都是叶子节点,所以我们在遍历的时候将所有的叶子节点的编码和字符存入表中即可。
我们规定遍历树建立表的时候,往左孩子访问一层给码值加0,往右就加1。比如刚刚介绍树的时候贴的那张图,b是00,c是01,a是1。
下面是建立起来的码表
构建Huffman树和创建编码表的实现过程
看完思路之后再看实现过程,我们先看创建队列时候的一系列操作:
因为为了方便我用了部分C++语法,所以分配内存会是用new,释放内存就是delete,就和C语言里malloc和free是一个作用,其他的都一样。
队列的初始化:
queue Init_queue()
{
queue q;
q.size = 0;
q.front = new struct QNode;
if (!q.front)
{
printf("分配失败!\n");
exit(1);
}
q.front->next = NULL;
return q;
}
队列的插入:
//插入,根据优先级
bool EnQueue(queue& q, Tree avl, int weight)
{
Node newp = new struct QNode;
newp->val = avl;
newp->priority = weight;
if (q.size == 0 || q.front == NULL) //空表
{
newp->next = NULL;
q.front = newp;
q.size = 1;
return true;
}
else //中间位置,需要迭代
{
if (weight <= q.front->priority) //比第一个都小
{
newp->next = q.front;
q.front = newp;
q.size++;
return true;
}
else //中间位置
{
Node beforp = q.front;
while (beforp->next != NULL)
{
if (weight <= beforp->next->priority)
{
newp->next = beforp->next;
beforp->next = newp;
q.size++;
return true;
}
else
{
beforp = beforp->next;
}
}
//需要插在队列最后
if (beforp->next == NULL)
{
newp->next = NULL;
beforp->next = newp;
q.size++;
return true;
}
}
}
return true;
}
创建一个队列:
需要用户输入每个字符和对应的优先级
//创建队列
queue Create_Queue()
{
queue q = Init_queue();
while (1)
{
char symbol;
int weight;
cin >> symbol >> weight; //C++里的输入,输入symnol和weight
if (weight == 0) //如果输入的权值为0,表示输入结束
break;
Tree t = new struct TNode;
t->data = symbol;
t->left = NULL;
t->right = NULL;
EnQueue(q, t, weight);
}
return q;
}
弹出队列中优先级最小的结点:
//弹出队列优先级最小的
Tree Dequeue(queue& q)
{
if (q.front == NULL)
{
cout << "空队!" << endl;
exit(1);
}
Node p = q.front;
q.front = p->next;
Tree e = p->val;
q.size--;
delete[] p;
return e;
}
树的函数,根据优先级队列创建一棵树:
//树的函数
//创建一棵树
Tree Create_Tree(queue& q)
{
while (q.size != 1)
{
int priority = q.front->priority + q.front->next->priority;
Tree left = Dequeue(q);
Tree right = Dequeue(q);
Tree newTNode = new struct TNode;
newTNode->left = left;
newTNode->right = right;
EnQueue(q, newTNode, priority);
}
Tree root = new struct TNode;
root = Dequeue(q);
return root;
}
表的函数,根据树创建一张表:
//创建一张表
table Create_Table(Tree root)
{
table t = new struct Table;
t->first = NULL;
t->last = NULL;
char code[256];
int k = 0;
travel(root, t, code, k);
return t;
}
表的函数,对travel函数的实现:
travel函数表示对树的遍历,从而建立起表,采用表尾插入法
void travel(Tree root, table& t, char code[256], int k)
{
if (root->left == NULL && root->right == NULL)
{
code[k] = '\0';
bNode b = new struct BNode;
b->symbol = root->data;
strcpy(b->code, code);
b->next = NULL;
//尾部插入法
if (t->first == NULL) //空表
{
t->first = b;
t->last = b;
}
else
{
t->last->next = b;
t->last = b;
}
}
if (root->left != NULL)
{
code[k] = '0';
travel(root->left, t, code, k + 1);
}
if (root->right != NULL)
{
code[k] = '1';
travel(root->right, t, code, k + 1);
}
}
编解码
至此,Huffman树以及编码表已经构建完毕,现在就来实现编解码的函数来检验上述的Huffman树。
编码:
需要传入编码表来进行编码
void EnCode(table t, char* str)
{
cout << "EnCodeing............./" << endl;
int len = strlen(str);
for (int i = 0; i < len; i++)
{
bNode p = t->first;
while (p != NULL)
{
if (p->symbol == str[i])
{
cout << p->code;
break;
}
p = p->next;
}
}
cout << endl;
}
解码:
需要传入Huffman树来进行编码
void DeCode(Tree root, char* str)
{
cout << "DeCode............./" << endl;
Tree p = root;
int len = strlen(str);
for (int i = 0; i < len; i++)
{
if (p->left == NULL && p->right == NULL)
{
cout << p->data;
p = root;
}
if (str[i] == '0')
p = p->left;
if (str[i] == '1')
p = p->right;
if (str[i] != '0' && str[i] != '1')
{
cout << "The Input String Is Not Encoded correctly !" << endl;
return;
}
}
if (p->left == NULL && p->right == NULL)
cout << p->data;
cout << endl;
}
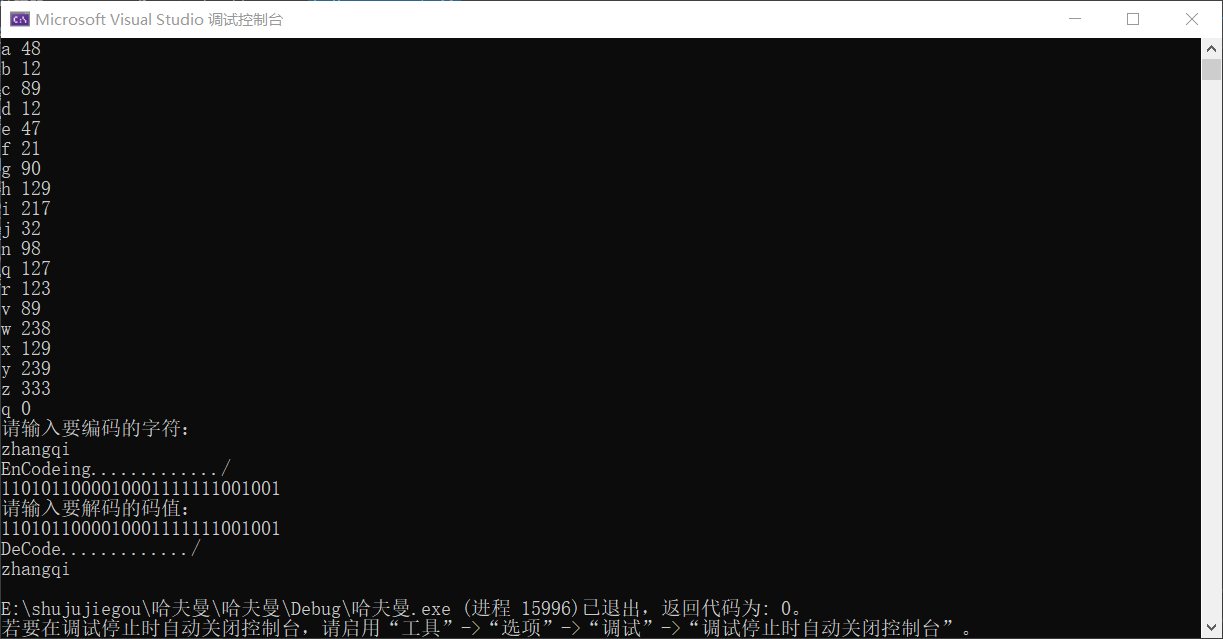
测试数据
int main()
{
queue q = Create_Queue();
Tree root = Create_Tree(q);
table t = Create_Table(root);
char str[256];
cout << "请输入要编码的字符:" << endl;
cin >> str;
EnCode(t, str);
cout << "请输入要解码的码值:" << endl;
char str1[256];
cin >> str1;
DeCode(root, str1);
}
附上截图:
Huffman树及其编解码的更多相关文章
- huffman编解码英文文本[Python]
对英文文本的字母进行huffman编码,heapq优先队列构建huffman树 python huffman.py source.txt result.txt import sys import he ...
- [数据结构与算法]哈夫曼(Huffman)树与哈夫曼编码
声明:原创作品,转载时请注明文章来自SAP师太技术博客( 博/客/园www.cnblogs.com):www.cnblogs.com/jiangzhengjun,并以超链接形式标明文章原始出处,否则将 ...
- Huffman树及其应用
哈夫曼树又称为最优二叉树,哈夫曼树的一个最主要的应用就是哈夫曼编码,本文通过简单的问题举例阐释哈夫曼编码的由来,并用哈夫曼树的方法构造哈夫曼编码,最终解决问题来更好的认识哈夫曼树的应用--哈夫曼编码. ...
- 数据结构与算法(周鹏-未出版)-第六章 树-6.5 Huffman 树
6.5 Huffman 树 Huffman 树又称最优树,可以用来构造最优编码,用于信息传输.数据压缩等方面,是一类有着广泛应用的二叉树. 6.5.1 二叉编码树 在计算机系统中,符号数据在处理之前首 ...
- JPEG文件编/解码详解
JPEG文件编/解码详解(1) JPEG(Joint Photographic Experts Group)是联合图像专家小组的英文缩写.它由国际电话与电报咨询委员会CCITT(The Interna ...
- 哈夫曼编解码压缩解压文件—C++实现
前言 哈夫曼编码是一种贪心算法和二叉树结合的字符编码方式,具有广泛的应用背景,最直观的是文件压缩.本文主要讲述如何用哈夫曼编解码实现文件的压缩和解压,并给出代码实现. 哈夫曼编码的概念 哈夫曼树又称作 ...
- 各种音视频编解码学习详解 h264 ,mpeg4 ,aac 等所有音视频格式
编解码学习笔记(一):基本概念 媒体业务是网络的主要业务之间.尤其移动互联网业务的兴起,在运营商和应用开发商中,媒体业务份量极重,其中媒体的编解码服务涉及需求分析.应用开发.释放 license收费等 ...
- HUFFMAN 树
在一般的数据结构的书中,树的那章后面,著者一般都会介绍一下哈夫曼(HUFFMAN) 树和哈夫曼编码.哈夫曼编码是哈夫曼树的一个应用.哈夫曼编码应用广泛,如 JPEG中就应用了哈夫曼编码. 首先介绍什么 ...
- [数据结构] 2.2 Huffman树
注:本文原创,转载请注明出处,本人保留对未注明出处行为的责任追究. 1.Huffman树是什么 Huffman树也称为哈夫曼编码,是一种编码方式,常用于协议的制定,以节省传输空间. A - F字母,出 ...
随机推荐
- 【Offer】[49] 【丑数】
题目描述 思路分析 测试用例 Java代码 代码链接 题目描述 我们把只包含因子2.3和5的数称作丑数( Ugly Number).求按从小到大的顺序的第1500个丑数.例如,6.8都是丑数,但14不 ...
- mariadb报:ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (111 "Connection refused")
我这边移除了mysql.sock文件后,重启服务就成功了. 还有一种情况,就是加入galera后,可能是server.cnf配置信息出了问题导致的,修改后,重新运行galera即可,数据库就可以启动成 ...
- Python 为了提升性能,竟运用了共享经济
大家或许知道,Python 为了提高内存的利用效率,采用了一套共用对象内存的分配策略. 例如,对于那些数值较小的数字对象([-5, 256]).布尔值对象.None 对象.较短的字符串对象(通常 是 ...
- java PDF转word的初步实现
package com.springboot.springboot.util; import java.io.File; import java.io.FileOutputStream; import ...
- mybatis-geneator
一.简介 在使用mybatis时我们需要重复的去创建pojo类.mapper文件以及dao类并且需要配置它们之间的依赖关系,比较麻烦且做了大量的重复工作,mybatis官方也发现了这个问题, 因此给我 ...
- 第1次作业:使用Packet Tracer分析HTTP数据包
个人信息: • 姓名:李微微 • 班级:计算1811 • 学号:201821121001 一.摘要 本文将会描述使用Packet Tracer工具用到的网络结构 ...
- MOOC C++笔记(二):类和对象基础
第二周:类和对象基础 面向对象程序设计的四个基本特点 抽象.封装.继承.多态. 面向对象程序设计的过程 1.从客观事物抽象出类 抽象出的事物带有成员函数与成员变量(类似于带函数的结构体) 成员变量和成 ...
- 59 (OC)* atomic是否绝对安全
场景:如今项目中有这样一个场景,在一个自定义类型的Property在一个线程中改变的同时也要同时在另一个线程中使用它,使我不得不将Property定义成atomic,但是由此发现atomic并不会保证 ...
- 08 (OC)* 事件的传递和响应机制
前言:苹果的官方文档<Event Handling Guide for iOS>对事件处理做了非常详尽清晰的解释,建议大家仔细研读 1. iOS中的事件介绍 2. 事件的产生和传递 3. ...
- Tcloud 云测平台-使用介绍
Tcloud使用介绍 前端github地址:https://github.com/bigbaser/Tcloud后端github地址:https://github.com/bigbaser/Tclou ...