elasticsearch倒排索引与TF-IDF算法
elasticsearch专栏:https://www.cnblogs.com/hello-shf/category/1550315.html
一、倒排索引(Inverted Index)简介
在关系数据库系统里,索引是检索数据最有效率的方式。但对于搜索引擎,它并不能满足其特殊要求,比如海量数据下比如百度或者谷歌要搜索百亿级的网页,如果使用类似关系型数据库使用的B+树索引,可想而知其对cpu的计算能力要求得有多高。其次关系型数据库中一般存储的都是结构化的数据,数据格式都是一定的,操作上一般也都是curd等比较简单的操作。
倒排索引区别于正向索引,一般的倒排索引被用来做全文搜索。比如现在有一本10w字的书,单词使用量为3k,我要从中搜索某个词出现的章节,我们该怎么做?
正排索引:遍历这本书,记录该次出现的章节。我们几乎要遍历完10w个词才能统计完。
倒排索引:建立倒排索引,将每个词作为key,该词出现的章节为value。我们只要在3k个单词中找到我们的目标词即可。
这样的话,显然倒排索引对于全文搜索性能更好。(上面举得例子不太好,凑合吧)
一般的正排索引是以key找value,而倒排索引则是以value找key。反转了key-value的关系。
二、es中的倒排索引
在es中text类型字段默认只会建立倒排索引,其它几种类型在建立倒排索引的时候还会建立正排索引,当然es是支持自定义的。在这里这个正排索引其实就是Doc Value。本章节我们主要是介绍倒排索引。下面我们介绍一个例子,看看倒排索引是如何建立的。
比如我们有两个doc(document 文档),都有一个content字段
doc_1:The quick brown fox jumped over the lazy dog
doc_2:Quick brown foxes jump over lazy dogs in summer
首先在es底层分词器会对doc进行分词,得到一个个term(单词),然后建立一个映射关系,记录存在各个单词的文档。首先我们分析一下各个单词存在的文档。
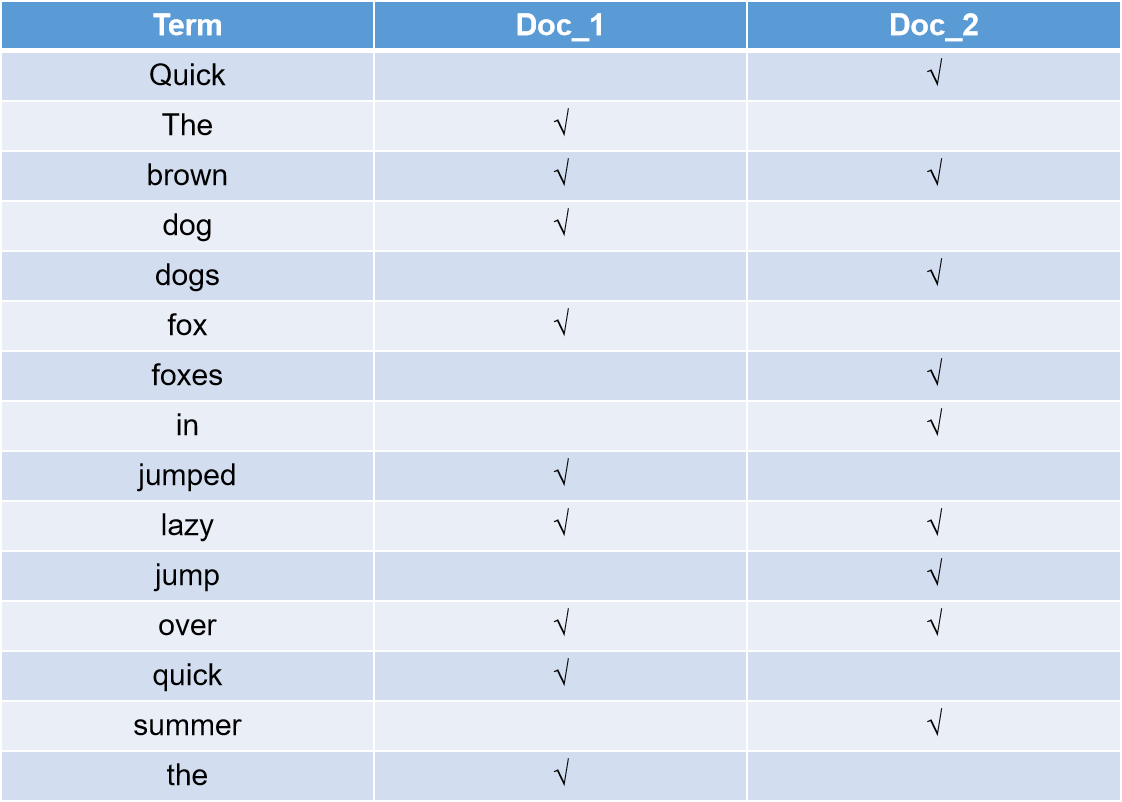
因为每个doc都是由id唯一标识的,所以其会建立一个映射关系。
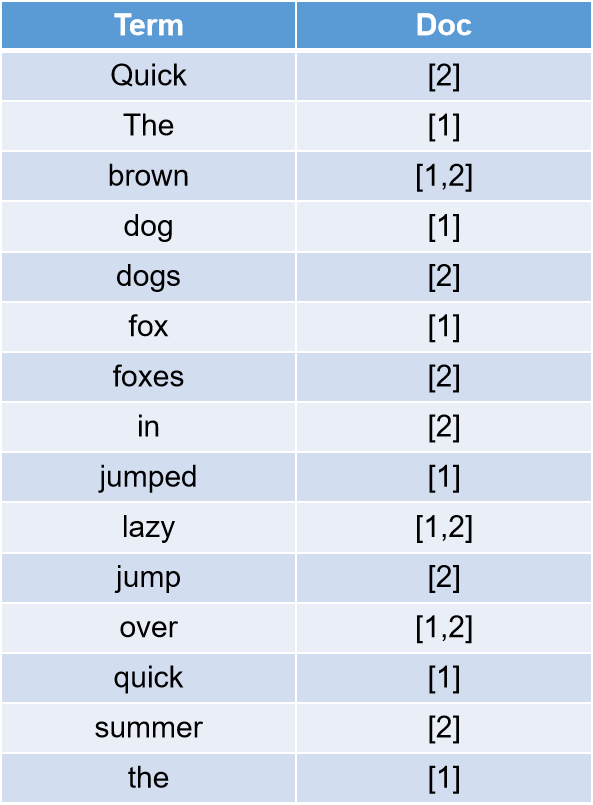
当es建立了这种映射关系,当我们搜索一个单词的时候,是不是就不需要遍历每个文档了呢。当然,es的倒排索引并不会这么简单。
term优化,比如我们用百度搜索“JUmped”这个词
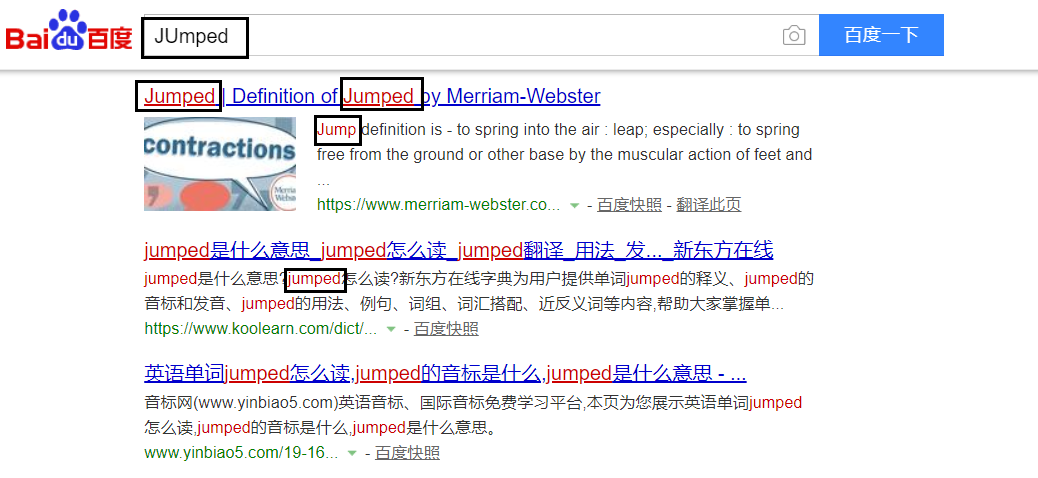
很容易发现,竟然区分好了大小写,并且还只能的匹配到了不同的时态。所以es同样也是这样的,es的分词器会对单词进行一定的处理,比如:
大小写转换:Quick --> quick
近义词转换:mother --> mom
时态转换:jumped --> jump
单复数转换:dogs --> dog
......
注意:不同的分词器的分词方式和算法都是不尽相同的。要注意这一点。
当es进行了term优化之后,我们再看看这个倒排索引:
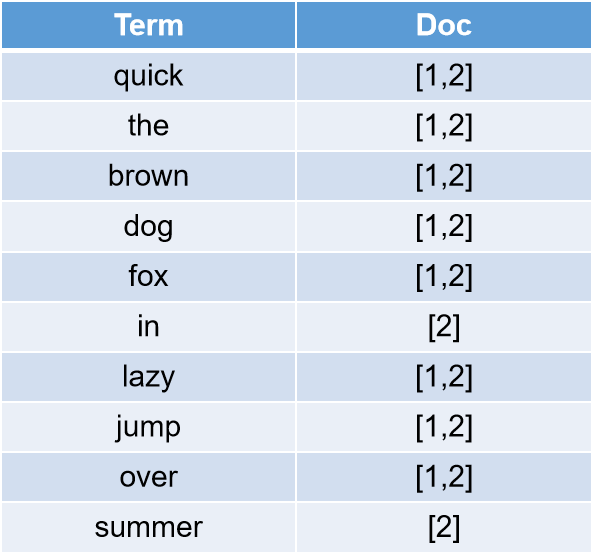
当倒排索引如上所示,我们很容易就能进行全文搜索。
三、TF-IDF算法
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜寻引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。
Term frequency:搜索文本中的各个词条在field文本中出现了多少次,出现次数越多,就越相关
在es中进行全文搜索时,搜索结果的匹配度也是采用的TF-IDF算法。这个匹配度是能够在es的元数据 _score 属性中体现出来的。通过实验验证一下。
首先建立一个索引
PUT /my_index?pretty
插入数据
PUT /my_index/my_index_type/1
{
"content":"The quick brown fox jumped over the lazy dog"
}
PUT /my_index/my_index_type/2
{
"content":"Quick brown foxes jump over lazy dogs in summer"
}
搜索
GET /my_index/my_index_type/_search
{
"query":{
"match":{
"content": "quick"
}
}
}
搜索结果
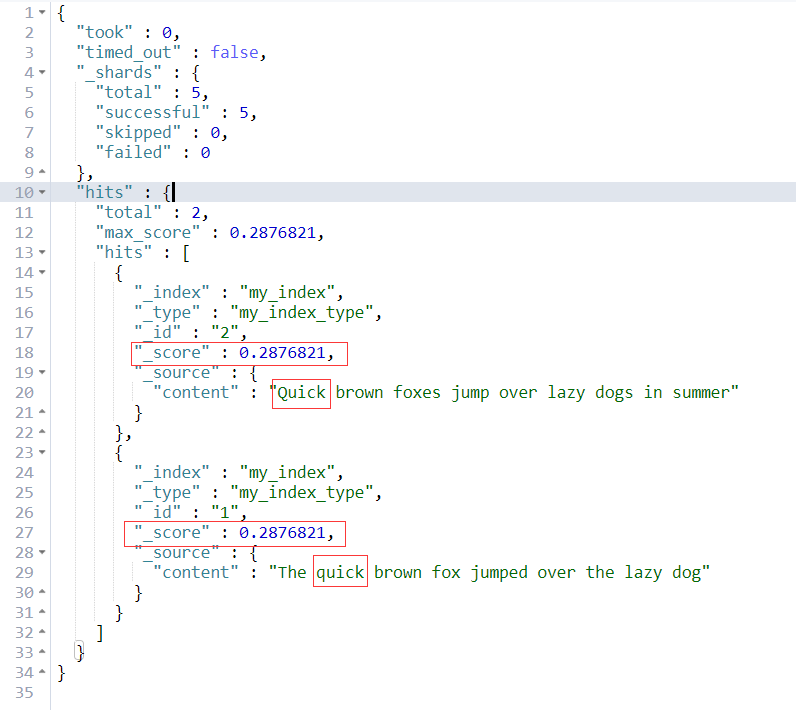
通过以上结果我们很容易发现,es通过TF-IDF算法计算出来了相关度 _score。并且还勿略了大小写。
如果我们搜索单词“summer”,结果如下所示,只匹配到了doc1。

参考文献:
《elasticsearch-权威指南》
如有错误的地方还请留言指正。
原创不易,转载请注明原文地址:https://www.cnblogs.com/hello-shf/p/11543460.html
elasticsearch倒排索引与TF-IDF算法的更多相关文章
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- 55.TF/IDF算法
主要知识点: TF/IDF算法介绍 查看es计算_source的过程及各词条的分数 查看一个document是如何被匹配到的 一.算法介绍 relevance score算法,简单来说 ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- tf–idf算法解释及其python代码
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- 25.TF&IDF算法以及向量空间模型算法
主要知识点: boolean model IF/IDF vector space model 一.boolean model 在es做各种搜索进行打分排序时,会先用boolean mo ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
随机推荐
- seq2seq通俗理解----编码器和解码器(TensorFlow实现)
1. 什么是seq2seq 在⾃然语⾔处理的很多应⽤中,输⼊和输出都可以是不定⻓序列.以机器翻译为例,输⼊可以是⼀段不定⻓的英语⽂本序列,输出可以是⼀段不定⻓的法语⽂本序列,例如: 英语输⼊:&quo ...
- JavaScript中几种常见的兼容问题及解决方案
在js中好用的东西一般都存在兼容问题,以下,我整理了一些常用的兼容处理方法,自己用的时候可以把他们放在一个JS文件中,需要用到时候直接引入,会比较方便. 一.获取非行内样式 function getS ...
- Linux 防火墙开放、查询、关闭端口
1. 开放指定端口 firewall-cmd --zone=public --add-port=5121/tcp --permanent # --permanent 永久生效,如果不加此条,重启后该命 ...
- 关于turtle画蟒蛇小实例
import turtle turtle.setup(800,600) turtle.pensize(25) turtle.pencolor('blue') turtle.penup() #抬笔 tu ...
- 关于web.xml配置
整理自网上: web应用是一种可以通过Web访问的应用程序.在J2EE领域下,web应用就是遵守基于JAVA技术的一系列标准的应用程序. 最简单的web应用什么样? 2个文件夹.1个xml文件就能成为 ...
- 主席树区间第K大
主席树的实质其实还是一颗线段树, 然后每一次修改都通过上一次的线段树,来添加新边,使得每次改变就改变logn个节点,很多节点重复利用,达到节省空间的目的. 1.不带修改的区间第K大. HDU-2665 ...
- light 1205 - Palindromic Numbers(数位dp)
题目链接:http://www.lightoj.com/volume_showproblem.php?problem=1205 题解:这题作为一个数位dp,是需要咚咚脑子想想的.这个数位dp方程可能不 ...
- Codeforces Round #483 (Div. 2) B. Minesweeper
题目地址:http://codeforces.com/contest/984/problem/B 题目大意:扫雷游戏,给你一个n*m的地图,如果有炸弹,旁边的八个位置都会+1,问这幅图是不是正确的. ...
- python读取大文件只能读取部分的问题
最近准备重新研究一下推荐系统的东西,用到的数据集是Audioscrobbler音乐数据集.我用python处理数据集中artist_data.txt这个文件的时候,先读取每一行然后进行处理: with ...
- 【Offer】[32] 【从上到下打印二叉树】
题目描述 思路分析 测试用例 Java代码 代码链接 题目描述 不换行:从上到下打印出二叉树的每个节点,同层的节点按照从左到右的顺序打印.例如,输入下图的二叉树,则依次打印出8,6,10,5,7,9, ...