elasticsearch倒排索引与TF-IDF算法
elasticsearch专栏:https://www.cnblogs.com/hello-shf/category/1550315.html
一、倒排索引(Inverted Index)简介
在关系数据库系统里,索引是检索数据最有效率的方式。但对于搜索引擎,它并不能满足其特殊要求,比如海量数据下比如百度或者谷歌要搜索百亿级的网页,如果使用类似关系型数据库使用的B+树索引,可想而知其对cpu的计算能力要求得有多高。其次关系型数据库中一般存储的都是结构化的数据,数据格式都是一定的,操作上一般也都是curd等比较简单的操作。
倒排索引区别于正向索引,一般的倒排索引被用来做全文搜索。比如现在有一本10w字的书,单词使用量为3k,我要从中搜索某个词出现的章节,我们该怎么做?
正排索引:遍历这本书,记录该次出现的章节。我们几乎要遍历完10w个词才能统计完。
倒排索引:建立倒排索引,将每个词作为key,该词出现的章节为value。我们只要在3k个单词中找到我们的目标词即可。
这样的话,显然倒排索引对于全文搜索性能更好。(上面举得例子不太好,凑合吧)
一般的正排索引是以key找value,而倒排索引则是以value找key。反转了key-value的关系。
二、es中的倒排索引
在es中text类型字段默认只会建立倒排索引,其它几种类型在建立倒排索引的时候还会建立正排索引,当然es是支持自定义的。在这里这个正排索引其实就是Doc Value。本章节我们主要是介绍倒排索引。下面我们介绍一个例子,看看倒排索引是如何建立的。
比如我们有两个doc(document 文档),都有一个content字段
doc_1:The quick brown fox jumped over the lazy dog
doc_2:Quick brown foxes jump over lazy dogs in summer
首先在es底层分词器会对doc进行分词,得到一个个term(单词),然后建立一个映射关系,记录存在各个单词的文档。首先我们分析一下各个单词存在的文档。
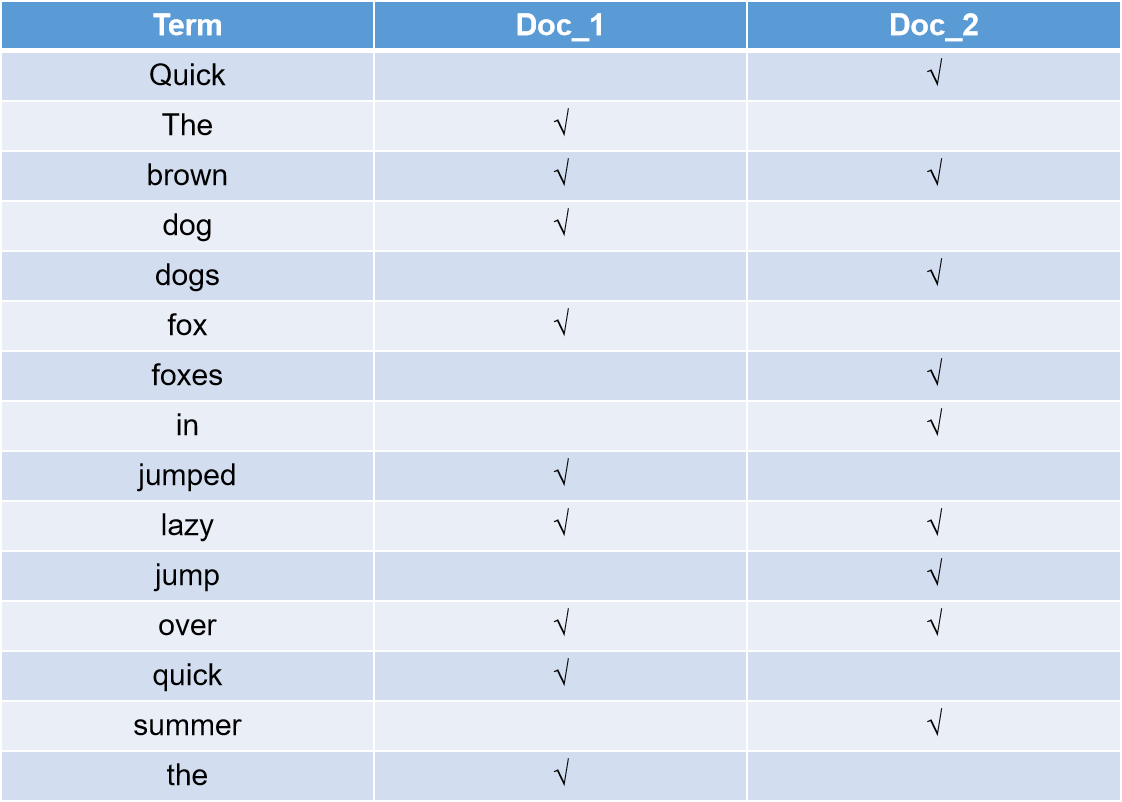
因为每个doc都是由id唯一标识的,所以其会建立一个映射关系。
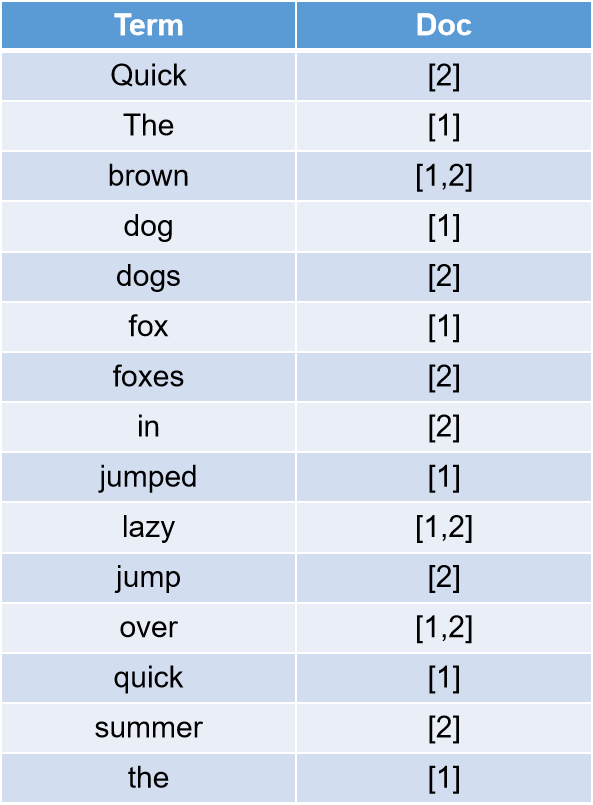
当es建立了这种映射关系,当我们搜索一个单词的时候,是不是就不需要遍历每个文档了呢。当然,es的倒排索引并不会这么简单。
term优化,比如我们用百度搜索“JUmped”这个词
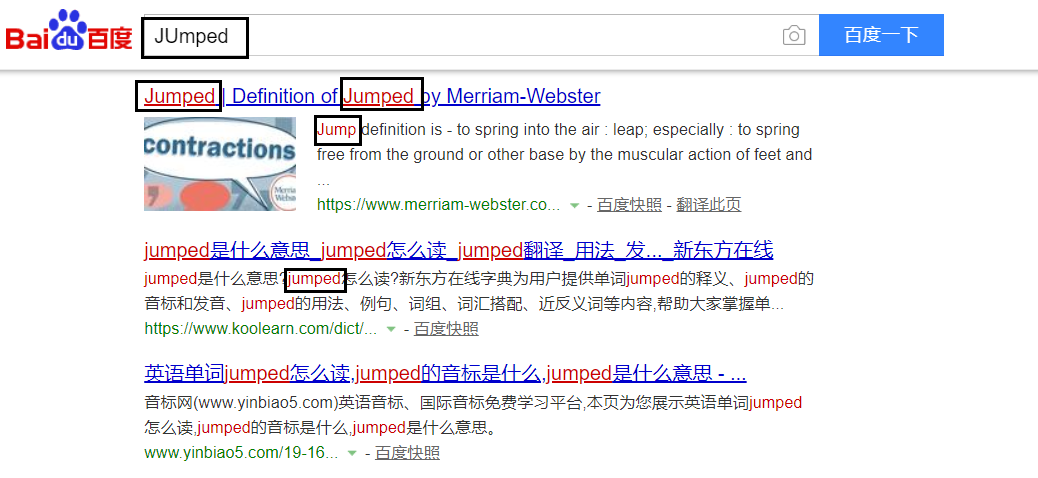
很容易发现,竟然区分好了大小写,并且还只能的匹配到了不同的时态。所以es同样也是这样的,es的分词器会对单词进行一定的处理,比如:
大小写转换:Quick --> quick
近义词转换:mother --> mom
时态转换:jumped --> jump
单复数转换:dogs --> dog
......
注意:不同的分词器的分词方式和算法都是不尽相同的。要注意这一点。
当es进行了term优化之后,我们再看看这个倒排索引:
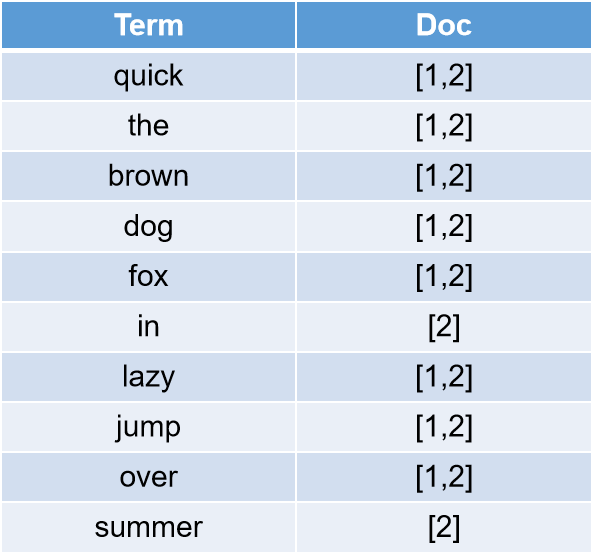
当倒排索引如上所示,我们很容易就能进行全文搜索。
三、TF-IDF算法
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术。TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜寻引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜寻引擎还会使用基于连结分析的评级方法,以确定文件在搜寻结果中出现的顺序。
Term frequency:搜索文本中的各个词条在field文本中出现了多少次,出现次数越多,就越相关
在es中进行全文搜索时,搜索结果的匹配度也是采用的TF-IDF算法。这个匹配度是能够在es的元数据 _score 属性中体现出来的。通过实验验证一下。
首先建立一个索引
PUT /my_index?pretty
插入数据
PUT /my_index/my_index_type/1
{
"content":"The quick brown fox jumped over the lazy dog"
}
PUT /my_index/my_index_type/2
{
"content":"Quick brown foxes jump over lazy dogs in summer"
}
搜索
GET /my_index/my_index_type/_search
{
"query":{
"match":{
"content": "quick"
}
}
}
搜索结果
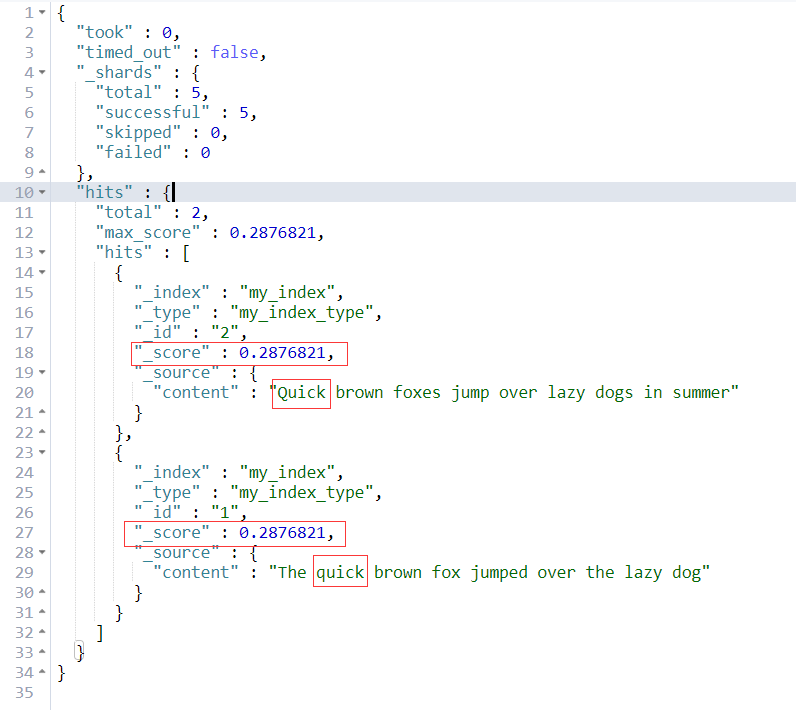
通过以上结果我们很容易发现,es通过TF-IDF算法计算出来了相关度 _score。并且还勿略了大小写。
如果我们搜索单词“summer”,结果如下所示,只匹配到了doc1。

参考文献:
《elasticsearch-权威指南》
如有错误的地方还请留言指正。
原创不易,转载请注明原文地址:https://www.cnblogs.com/hello-shf/p/11543460.html
elasticsearch倒排索引与TF-IDF算法的更多相关文章
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- 55.TF/IDF算法
主要知识点: TF/IDF算法介绍 查看es计算_source的过程及各词条的分数 查看一个document是如何被匹配到的 一.算法介绍 relevance score算法,简单来说 ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- tf–idf算法解释及其python代码
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- 25.TF&IDF算法以及向量空间模型算法
主要知识点: boolean model IF/IDF vector space model 一.boolean model 在es做各种搜索进行打分排序时,会先用boolean mo ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
随机推荐
- socket-遇到一枚假程序员
1. 一脸懵比 今天又偶然看到socket,对socket有点简单的概念,知道是网络编程.客户端与服务端通信等,但是不是太了解,就随便搜了下,几千万条记录,随便点开看了几页,socket跟网络编程也是 ...
- jq ajax传递json对象到服务端及contentType的用法
目录 0.一般情况下,通过键值对的方式将参数传递到服务端 1.ajax 传递复杂json对象到服务端 2.content-Type 对asp.net mvc项目的重要性 0.一般情况下,通过键值对的方 ...
- Jedis操作Redis--Key操作
/** * Key(键) * DEL,DUMP,EXISTS,EXPIRE,EXPIREAT,KEYS,MIGRATE,MOVE,OBJECT,PERSIST,PEXPIRE,PEXPIREAT,PT ...
- Linux网络配置(10)
Linux网络配置原理图(NAT模式) 查看网络IP和网关: CentOS7:ip addr CentOS6:ifconfig Ping测试主机之间网络的连通性:ping [www.baidu.com ...
- POJ-2406Power Strings-KMP+定理
Power Strings 题意:给一个字符串S长度不超过10^6,求最大的n使得S由n个相同的字符串a连接而成,如:"ababab"则由n=3个"ab"连接而 ...
- JOBDU 1027 欧拉回路
题目1027:欧拉回路 时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:3620 解决:1847 题目描述: 欧拉回路是指不令笔离开纸面,可画过图中每条边仅一次,且可以回到起点的一条 ...
- webapi 参数传递详解
原因 经常有朋友遇到webapi参数传递问题,自己也碰到过一些坑,在此记录下正确的姿势,简单参数传递相信没有人会有问题,容易出现问题的是对象参数和表单参数. 1.WebApi5.2.3有FromBod ...
- 基于C-W节约算法的车辆路径规划问题的Java实现
VRP问题概述 解决算法分类 项目描述 算法结果 车辆路线问题(VRP)最早是由Dantzig和Ramser于1959年首次提出,它是指一定数量的客户,各自有不同数量的货物需求,配送中心向客户提供货物 ...
- [DP]换钱的方法数
题目三 给定数组arr, arr中所有的值都为整数且不重复.每个值代表一种面值的货币,每种面值的货币可以使用任意张,在给定一个整数aim代表要找的钱数,求换钱有多少种方法. 解法一 --暴力递归 用0 ...
- redis事务与关系型数据库事务比较
redis 是一个高性能的key-value 数据库.作为no sql 数据库redis 与传统关系型数据库相比有简单灵活.数据结构丰富.高速读写等优点. 本文主要针对redis 在事物方面的处理与传 ...