理解Spark SQL(三)—— Spark SQL程序举例
上一篇说到,在Spark 2.x当中,实际上SQLContext和HiveContext是过时的,相反是采用SparkSession对象的sql函数来操作SQL语句的。使用这个函数执行SQL语句前需要先调用DataFrame的createOrReplaceTempView注册一个临时表,所以关键是先要将RDD转换成DataFrame。实际上,在Spark中实际声明了
type DataFrame = Dataset[Row]
所以,DataFrame是Dataset[Row]的别名。RDD是提供面向低层次的API,而DataFrame/Dataset提供面向高层次的API(适合于SQL等面向结构化数据的场合)。
下面提供一些Spark SQL程序的例子。
例子一:SparkSQLExam.scala
package bruce.bigdata.spark.example import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._ object SparkSQLExam { case class offices(office:Int,city:String,region:String,mgr:Int,target:Double,sales:Double) def main(args: Array[String]) { val spark = SparkSession
.builder
.appName("SparkSQLExam")
.getOrCreate() runSparkSQLExam1(spark)
runSparkSQLExam2(spark) spark.stop() } private def runSparkSQLExam1(spark: SparkSession): Unit = { import spark.implicits._ val rddOffices=spark.sparkContext.textFile("/user/hive/warehouse/orderdb.db/offices/offices.txt").map(_.split("\t")).map(p=>offices(p(0).trim.toInt,p(1),p(2),p(3).trim.toInt,p(4).trim.toDouble,p(5).trim.toDouble))
val officesDataFrame = spark.createDataFrame(rddOffices) officesDataFrame.createOrReplaceTempView("offices")
spark.sql("select city from offices where region='Eastern'").map(t=>"City: " + t(0)).collect.foreach(println) } private def runSparkSQLExam2(spark: SparkSession): Unit = { import spark.implicits._
import org.apache.spark.sql._
import org.apache.spark.sql.types._ val schema = new StructType(Array(StructField("office", IntegerType, false), StructField("city", StringType, false), StructField("region", StringType, false), StructField("mgr", IntegerType, true), StructField("target", DoubleType, true), StructField("sales", DoubleType, false)))
val rowRDD = spark.sparkContext.textFile("/user/hive/warehouse/orderdb.db/offices/offices.txt").map(_.split("\t")).map(p => Row(p(0).trim.toInt,p(1),p(2),p(3).trim.toInt,p(4).trim.toDouble,p(5).trim.toDouble))
val dataFrame = spark.createDataFrame(rowRDD, schema) dataFrame.createOrReplaceTempView("offices2")
spark.sql("select city from offices2 where region='Western'").map(t=>"City: " + t(0)).collect.foreach(println) } }
使用下面的命令进行编译:
[root@BruceCentOS4 scala]# scalac SparkSQLExam.scala
在编译之前,需要在CLASSPATH中增加路径:
export CLASSPATH=$CLASSPATH:$SPARK_HOME/jars/*:$(/opt/hadoop/bin/hadoop classpath)
然后打包成jar文件:
[root@BruceCentOS4 scala]# jar -cvf spark_exam_scala.jar bruce
然后通过spark-submit提交程序到yarn集群执行,为了方便从客户端查看结果,这里采用yarn cient模式运行。
[root@BruceCentOS4 scala]# $SPARK_HOME/bin/spark-submit --class bruce.bigdata.spark.example.SparkSQLExam --master yarn --deploy-mode client spark_exam_scala.jar
运行结果截图:
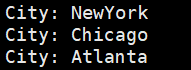
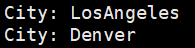
例子二:SparkSQLExam.scala(需要启动hive metastore)
package bruce.bigdata.spark.example
import org.apache.spark.sql.{SaveMode, SparkSession}
object SparkHiveExam {
def main(args: Array[String]) {
val spark = SparkSession
.builder()
.appName("Spark Hive Exam")
.config("spark.sql.warehouse.dir", "/user/hive/warehouse")
.enableHiveSupport()
.getOrCreate()
import spark.implicits._
//使用hql查看hive数据
spark.sql("show databases").collect.foreach(println)
spark.sql("use orderdb")
spark.sql("show tables").collect.foreach(println)
spark.sql("select city from offices where region='Eastern'").map(t=>"City: " + t(0)).collect.foreach(println)
//将hql查询出的数据保存到另外一张新建的hive表
//找出订单金额超过1万美元的产品
spark.sql("""create table products_high_sales(mfr_id string,product_id string,description string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' STORED AS TEXTFILE""")
spark.sql("""select mfr_id,product_id,description
from products a inner join orders b
on a.mfr_id=b.mfr and a.product_id=b.product
where b.amount>10000""").write.mode(SaveMode.Overwrite).saveAsTable("products_high_sales")
//将HDFS文件数据导入到hive表中
spark.sql("""CREATE TABLE IF NOT EXISTS offices2 (office int,city string,region string,mgr int,target double,sales double )
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' STORED AS TEXTFILE""")
spark.sql("LOAD DATA INPATH '/user/hive/warehouse/orderdb.db/offices/offices.txt' INTO TABLE offices2")
spark.stop()
}
}
使用下面的命令进行编译:
[root@BruceCentOS4 scala]# scalac SparkHiveExam.scala
使用下面的命令打包:
[root@BruceCentOS4 scala]# jar -cvf spark_exam_scala.jar bruce
使用下面的命令运行:
[root@BruceCentOS4 scala]# $SPARK_HOME/bin/spark-submit --class bruce.bigdata.spark.example.SparkHiveExam --master yarn --deploy-mode client spark_exam_scala.jar
程序运行结果:
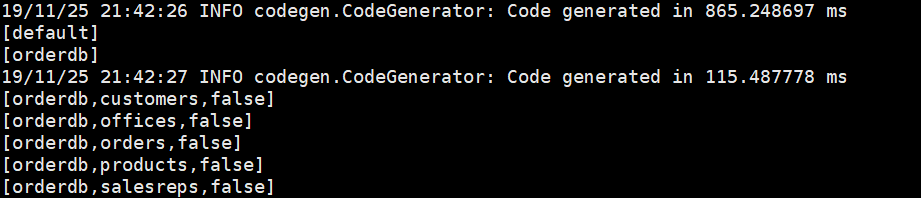

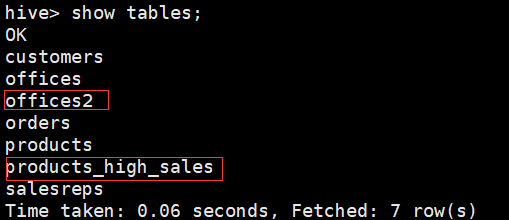
另外上述程序运行后,hive中多了2张表:
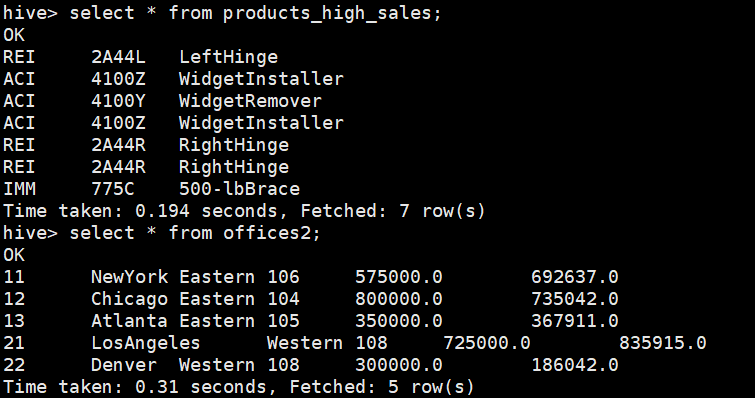
例子三:spark_sql_exam.py
from __future__ import print_function from pyspark.sql import SparkSession
from pyspark.sql.types import * if __name__ == "__main__":
spark = SparkSession \
.builder \
.appName("Python Spark SQL exam") \
.config("spark.some.config.option", "some-value") \
.getOrCreate() schema = StructType([StructField("office", IntegerType(), False), StructField("city", StringType(), False),
StructField("region", StringType(), False), StructField("mgr", IntegerType(), True),
StructField("Target", DoubleType(), True), StructField("sales", DoubleType(), False)]) rowRDD = spark.sparkContext.textFile("/user/hive/warehouse/orderdb.db/offices/offices.txt").map(lambda p: p.split("\t")) \
.map(lambda p: (int(p[0].strip()), p[1], p[2], int(p[3].strip()), float(p[4].strip()), float(p[5].strip()))) dataFrame = spark.createDataFrame(rowRDD, schema)
dataFrame.createOrReplaceTempView("offices")
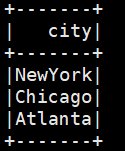
spark.sql("select city from offices where region='Eastern'").show() spark.stop()
执行命令运行程序:
[root@BruceCentOS4 spark]# $SPARK_HOME/bin/spark-submit --master yarn --deploy-mode client spark_sql_exam.py
程序运行结果:
例子四:JavaSparkSQLExam.java
package bruce.bigdata.spark.example; import java.util.ArrayList;
import java.util.List; import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
import org.apache.spark.sql.AnalysisException; public class JavaSparkSQLExam {
public static void main(String[] args) throws AnalysisException {
SparkSession spark = SparkSession
.builder()
.appName("Java Spark SQL exam")
.config("spark.some.config.option", "some-value")
.getOrCreate(); List<StructField> fields = new ArrayList<>();
fields.add(DataTypes.createStructField("office", DataTypes.IntegerType, false));
fields.add(DataTypes.createStructField("city", DataTypes.StringType, false));
fields.add(DataTypes.createStructField("region", DataTypes.StringType, false));
fields.add(DataTypes.createStructField("mgr", DataTypes.IntegerType, true));
fields.add(DataTypes.createStructField("target", DataTypes.DoubleType, true));
fields.add(DataTypes.createStructField("sales", DataTypes.DoubleType, false)); StructType schema = DataTypes.createStructType(fields); JavaRDD<String> officesRDD = spark.sparkContext()
.textFile("/user/hive/warehouse/orderdb.db/offices/offices.txt", 1)
.toJavaRDD(); JavaRDD<Row> rowRDD = officesRDD.map((Function<String, Row>) record -> {
String[] attributes = record.split("\t");
return RowFactory.create(Integer.valueOf(attributes[0].trim()), attributes[1], attributes[2], Integer.valueOf(attributes[3].trim()), Double.valueOf(attributes[4].trim()), Double.valueOf(attributes[5].trim()));
}); Dataset<Row> dataFrame = spark.createDataFrame(rowRDD, schema); dataFrame.createOrReplaceTempView("offices");
Dataset<Row> results = spark.sql("select city from offices where region='Eastern'");
results.collectAsList().forEach(r -> System.out.println(r)); spark.stop();
}
}
编译打包后通过如下命令执行:
[root@BruceCentOS4 spark]# $SPARK_HOME/bin/spark-submit --class bruce.bigdata.spark.example.JavaSparkSQLExam --master yarn --deploy-mode client spark_exam_java.jar
运行结果:

上面是一些关于Spark SQL程序的一些例子,分别采用了Scala/Python/Java来编写的。另外除了这三种语言,Spark还支持R语言编写程序,因为我自己也不熟悉,就不举例了。不管用什么语言,其实API都是基本一致的,主要是采用DataFrame和Dataset的高层次API来调用和执行SQL。使用这些API,可以轻松的将结构化数据转化成SQL来操作,同时也能够方便的操作Hive中的数据。
理解Spark SQL(三)—— Spark SQL程序举例的更多相关文章
- spark实验(三)--Spark和Hadoop的安装(1)
一.实验目的 (1)掌握在 Linux 虚拟机中安装 Hadoop 和 Spark 的方法: (2)熟悉 HDFS 的基本使用方法: (3)掌握使用 Spark 访问本地文件和 HDFS 文件的方法. ...
- 数据库系统原理之SQL(三)
数据库系统原理之SQL(三) 1. SQL的组成 1. 数据查询 2. 数据定义 3. 数据操作 4. 数据控制 2. 数据定义语言 CREATE创建数据库或数据库对象 创建数据库 ~~~ CREAT ...
- 基于Spark1.3.0的Spark sql三个核心部分
基于Spark1.3.0的Spark sql三个核心部分: 1.可以架子啊各种结构化数据源(JSON,Hive,and Parquet) 2.可以让你通过SQL,saprk内部程序或者外部攻击,通过标 ...
- Spark SQL概念学习系列之SQL on Spark的简介(三)
AMPLab 将大数据分析负载分为三大类型:批量数据处理.交互式查询.实时流处理.而其中很重要的一环便是交互式查询. 大数据分析栈中需要满足用户 ad-hoc.reporting. iterative ...
- 《Spark Python API 官方文档中文版》 之 pyspark.sql (三)
摘要:在Spark开发中,由于需要用Python实现,发现API与Scala的略有不同,而Python API的中文资料相对很少.每次去查英文版API的说明相对比较慢,还是中文版比较容易get到所需, ...
- Spark官方1 ---------Spark SQL和DataFrame指南(1.5.0)
概述 Spark SQL是用于结构化数据处理的Spark模块.它提供了一个称为DataFrames的编程抽象,也可以作为分布式SQL查询引擎. Spark SQL也可用于从现有的Hive安装中读取数据 ...
- Spark学习之Spark SQL(8)
Spark学习之Spark SQL(8) 1. Spark用来操作结构化和半结构化数据的接口--Spark SQL. 2. Spark SQL的三大功能 2.1 Spark SQL可以从各种结构化数据 ...
- 小记---------spark组件与其他组件的比较 spark/mapreduce ;spark sql/hive ; spark streaming/storm
Spark与Hadoop的对比 Scala是Spark的主要编程语言,但Spark还支持Java.Python.R作为编程语言 Hadoop的编程语言是Java
- Spark(1.6.1) Sql 编程指南+实战案例分析
首先看看从官网学习后总结的一个思维导图 概述(Overview) Spark SQL是Spark的一个模块,用于结构化数据处理.它提供了一个编程的抽象被称为DataFrames,也可以作为分布式SQL ...
随机推荐
- 玩转OneNET物联网平台之MQTT服务① —— OneNetMqtt全方位调试
授人以鱼不如授人以渔,目的不是为了教会你具体项目开发,而是学会学习的能力.希望大家分享给你周边需要的朋友或者同学,说不定大神成长之路有博哥的奠基石... QQ技术互动交流群:ESP8266&3 ...
- Kubernetes2-K8s的集群部署
一.简介 1.架构参考 Kubernetes1-K8s的简单介绍 2.实例架构 192.168.216.51 master etcd 192.168.216.53 node1 192.168.216 ...
- 源码剖析Yii错误 Invalid parameter number: no parameters were bound
ActiveRecord使用的一个陷阱导致 Invalid parameter number: no parameters were bound 请看下面的例子 $criteria = new CDb ...
- LeetCode刷题笔记(2)HashMap相关应用
1.问题描述 Example 1: Input: A = "this apple is sweet", B = "this apple is sour" Out ...
- 实现文字色彩渐变(Mask)
文字色彩渐变是指的文字本身的颜色,不是背景渐变.要实现此效果可以采用Mask组件,本文先从介绍mask说起 1)Mask介绍 mask组件实现的作用是,mask组件所在游戏物体下的子游戏物体在mask ...
- 解决axios发送post请求,后端接收不到数据
https://segmentfault.com/a/1190000012635783
- C和C++中的引用传递
两种引用传递的定义方式 第一种 #include<stdio.h> void changeValue(int *a); int main(){ int a =1; changeValue( ...
- SpringBoot系列:Spring Boot异步调用@Async
在实际开发中,有时候为了及时处理请求和进行响应,我们可能会多任务同时执行,或者先处理主任务,也就是异步调用,异步调用的实现有很多,例如多线程.定时任务.消息队列等, 这一章节,我们就来讲讲@Async ...
- 优化 Git Commit Message
目前很多项目都是通过 Git 进行管理的,Git 每次提交代码的过程中 提交说明 commit message 是必须的.但仅仅必须是不够的,好的提交说明可以帮助我们提高项目的整体质量. 作用与优点 ...
- [考试反思]0714/0716,NOIP模拟测试3/4
这几天时间比较紧啊(其实只是我效率有点低我在考虑要不要坐到后面去吹空调) 但是不管怎么说,考试反思还是要写的吧. 第三次考试反思没写总感觉缺了点什么,但是题都刷不完... 一进图论看他们刷题好快啊为什 ...