elk安装与搭建
Elasticsearch安装配置
·下载elasticsearch.tar.gz包,解压压缩包。(此处为单机版es,集群请参考 https://www.cnblogs.com/lazycxy/p/9468074.html)
·创建ES用户和组(创建elsearch用户组及elsearch用户),因为使用root用户执行ES程序,将会出现错误;所以这里需要创建单独的用户去执行ES 文件;命令如下:
命令一:groupadd elsearch
命令二:useradd elsearch -g elsearch
命令三:chown -R elsearch:elsearch elasticsearch-5.6.3 //该命令是更改该文件夹下所属的用户组的权限
·修改ES的配置文件,使用cd命令进入到config 文件下,执行 vi elasticsearch.yml 命令
命令一:vi elasticsearch.yml
修改如图所示三处配置,保存退出。
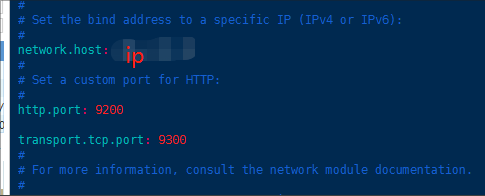
·切换到elsearch用户,启动elasticsearch;命令如下:
命令一:su elsearch
命令二:./elasticsearch (执行 ./elasticesrarch -d 是后台运行)
错误一:
此时会提示 vm.max_map_count [65530] is too low 这个值设置的太小,需要修改vm.max_map_count这个变量的值,切换到root用户修改配置sysctl.conf 增加配置值: vm.max_map_count=655360 执行命令 sysctl -p 这样就可以了,然后切到elsearch用户,重新启动ES服务 就可以了

错误二:
代表进程不够用了
解决方案: 切到root 用户:进入到security目录下的limits.conf;执行命令 vim /etc/security/limits.conf 在文件的末尾添加下面的参数值:
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096

前面的*符号必须带上,然后重新启动服务器即可。执行完成后可以使用命令 ulimit -n 查看进程数
最终切换到elsearch用户,启动es服务即可。

Kibana安装配置
在浏览器中输入ip:port查看是否启动成功,如图所示,单机elasticsearch启动成功
·下载Kibana.tar.gz包,解压压缩包。
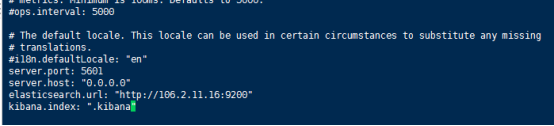
·修改kibana.yml配置文件
vim kibana.yml 编辑配置文件,在最后面加上如下配置就行:
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.url: "http://ip:9200"
//这里ip:port要和es配置文件中填写的一致
kibana.index: ".kibana"
·启动完毕,可以浏览器输入url:服务器外网ip:5601 查看是否成功启动:· 启动服务:cd命令进入bin目录,执行sh kibana & 命令 后台启动kibana

logstash 安装配置
·下载logstash.tar.gz包,解压压缩包。
·进入bin目录,创建配置文件logstash1.conf
cd logstash-6.4.2/bin/进入bin目录
新建文件 vim logstash1.conf ,写入内容(监听tomcat的日志):
input {
file {
path => "tomcat应用目录/logs/*.log" //此处代表监控的日志文件
start_position => beginning
}
}
filter {
}
output {
elasticsearch {
hosts => "ip:9200"
}
}
启动logstash:sh logstash -f logstash1.conf
至此 elk的环境就安装好了,kibana怎么去统计分析日志,将在下一篇文章讲解
elk安装与搭建的更多相关文章
- spring mvc+ELK从头开始搭建日志平台
最近由于之前协助前公司做了点力所能及的事情,居然收到了一份贵重的端午礼物,是给我女儿的一个乐高积木,整个有7大包物件,我花了接近一天的时间一砖一瓦的组织起来,虽然很辛苦但是能够从过程中体验到乐趣.这次 ...
- ELK平台的搭建
ELK是指Elasticsearch + Logstash + Kibaba三个组件的组合.本文讲解一个基于日志文件的ELK平台的搭建过程,有关ELK的原理以及更多其他信息,会在接下来的文章中继续研究 ...
- ELK - MAC环境搭建
ELK - MAC环境搭建 本文旨在记录elasticsearch.logstash.kibana在mac下的安装与启动. 写在前面 ELK的官方文档对与它们的使用方法已经讲的非常清楚了,这里只对相关 ...
- [elk]停电日志离线恢复故障处理-elk环境极速搭建
es数据手动导入 周末停电了两天,发现两天的日志没导入: 原因: 1. elk开启没设启动 2.日志入库时间是当前时间,不是日志本身的time字段 - 导入步骤 1. 先把日志拖下来 2. 事先需要干 ...
- 搭建ELK日志分析平台(上)—— ELK介绍及搭建 Elasticsearch 分布式集群
笔记内容:搭建ELK日志分析平台(上)-- ELK介绍及搭建 Elasticsearch 分布式集群笔记日期:2018-03-02 27.1 ELK介绍 27.2 ELK安装准备工作 27.3 安装e ...
- ELK 安装Beat
章节 ELK 介绍 ELK 安装Elasticsearch ELK 安装Kibana ELK 安装Beat ELK 安装Logstash Beat是数据采集工具,安装在服务器上,将采集到的数据发送给E ...
- ELK扫盲及搭建
1. ELK部署说明 1.1ELK介绍: 1.1.1 ELK是什么? ELK是三个开源软件的缩写,分别表示:ElasticSearch , Logstash, Kibana , 它们都是开源软件,EL ...
- ELK+FileBeat+Log4Net搭建日志系统
ELK+FileBeat+Log4Net搭建日志系统 来源:https://www.zybuluo.com/muyanfeixiang/note/608470 标签(空格分隔): ELK Log4Ne ...
- ELK安装配置及nginx日志分析
一.ELK简介1.组成ELK是Elasticsearch.Logstash.Kibana三个开源软件的组合.在实时数据检索和分析场合,三者通常是配合使用,而且又都先后归于 Elastic.co 公司名 ...
随机推荐
- 机器学习-FP Tree
接着是上一篇的apriori算法: FP Tree数据结构 为了减少I/O次数,FP Tree算法引入了一些数据结构来临时存储数据.这个数据结构包括三部分,如下图所示 第一部分是一个项头表.里面记录了 ...
- C#3.0新增功能09 LINQ 基础07 LINQ 中的查询语法和方法语法
连载目录 [已更新最新开发文章,点击查看详细] 介绍性的语言集成查询 (LINQ) 文档中的大多数查询是使用 LINQ 声明性查询语法编写的.但是在编译代码时,查询语法必须转换为针对 .NET ...
- Salesforce Admin篇(三) Delegated Administrator
项目中,我们可能会遇见以下的场景. 1. HR 经理针对申请者和工作相关的表的app会经常需要修改布局查看需要的页面的字段: 2. 开发者将record type对应的picklist values等 ...
- java练习---5
//程序员:罗元昊 2017.9.17 package demo;import java.util.Scanner;public class Ly { public static void main ...
- Flink实战(八) - Streaming Connectors 编程
1 概览 1.1 预定义的源和接收器 Flink内置了一些基本数据源和接收器,并且始终可用.该预定义的数据源包括文件,目录和插socket,并从集合和迭代器摄取数据.该预定义的数据接收器支持写入文件和 ...
- 重复造轮子系列——基于FastReport设计打印模板实现桌面端WPF套打和商超POS高度自适应小票打印
重复造轮子系列——基于FastReport设计打印模板实现桌面端WPF套打和商超POS高度自适应小票打印 一.引言 桌面端系统经常需要对接各种硬件设备,比如扫描器.读卡器.打印机等. 这里介绍下桌面端 ...
- AbstractList
概述 此类提供 List 接口的骨干实现,以最大限度地减少实现“随机访问”数据存储(如数组)支持的该接口所需的工作.对于连续的访问数据(如链表),应优先使用 AbstractSequentialLis ...
- JS原生隐士标签扩展
最近项目开发中,开发了不少的接口,有一个接口是这样子的.先从A公司拿到数据后,存放到我们公司数据库里,然后需要将数据展示给客户,下面这个界面,后台要实时刷新,后台写了个定时器,2S刷一次从后台拼接好H ...
- 如何编译生成Linux-C静态链接库
目标生成的静态库文件为:libnpcp.a 举例:我们有四个文件分别为:npcp.c npcp.h other.h main.c main.h在npcp.c里面#include "other ...
- python 获取大乐透中奖结果
实现思路: 1.通过urllib库爬取http://zx.500.com/dlt/页面,并过滤出信息 2.将自己的买的彩票的号与开奖号进行匹配,查询是否中奖 3.将中奖结果发生到自己邮箱 caipia ...