机器学习-FP Tree
接着是上一篇的apriori算法:
FP Tree数据结构
为了减少I/O次数,FP Tree算法引入了一些数据结构来临时存储数据。这个数据结构包括三部分,如下图所示
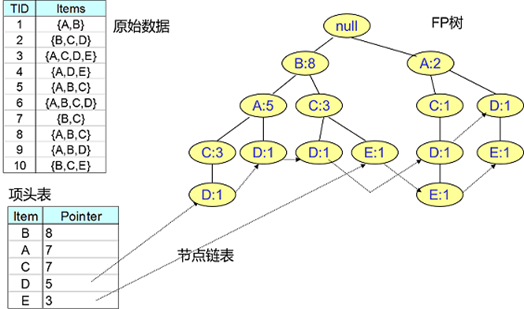
第一部分是一个项头表。里面记录了所有的1项频繁集出现的次数,按照次数降序排列。
比如上图中B在所有10组数据中出现了8次,因此排在第一位,这部分好理解。
第二部分是FP Tree,它将我们的原始数据集映射到了内存中的一颗FP树,这个FP树比较难理解,它是怎么建立的呢?
这个我们后面再讲。第三部分是节点链表。所有项头表里的1项频繁集都是一个节点链表的头,
它依次指向FP树中该1项频繁集出现的位置。这样做主要是方便项头表和FP Tree之间的联系查找和更新,也好理解。
下面讲项头表和FP树的建立过程。
项头表的建立
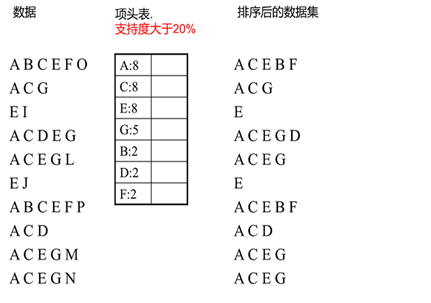
FP树的建立需要首先依赖项头表的建立。首先我们看看怎么建立项头表。
我们第一次扫描数据,得到所有频繁一项集的的计数。然后删除支持度低于阈值的项,将1项频繁集放入项头表,并按照支持度降序排列。接着第二次也是最后一次扫描数据,将读到的原始数据剔除非频繁1项集,并按照支持度降序排列。
上面这段话很抽象,我们用下面这个例子来具体讲解。
我们有10条数据,首先第一次扫描数据并对1项集计数,我们发现O,I,L,J,P,M, N都只出现一次,支持度低于20%的阈值,因此他们不会出现在下面的项头表中。剩下的A,C,E,G,B,D,F按照支持度的大小降序排列,组成了我们的项头表。
接着我们第二次扫描数据,对于每条数据剔除非频繁1项集,并按照支持度降序排列。
比如数据项ABCEFO,里面O是非频繁1项集,因此被剔除,只剩下了ABCEF。按照支持度的顺序排序,它变成了ACEBF。
其他的数据项以此类推。为什么要将原始数据集里的频繁1项数据项进行排序呢?这是为了我们后面的FP树的建立时,可以尽可能的共用祖先节点。
通过两次扫描,项头表已经建立,排序后的数据集也已经得到了,下面我们再看看怎么建立FP树。
FP Tree的建立
有了项头表和排序后的数据集,就可以开始FP树的建立了。
开始时FP树没有数据,建立FP树时一条条的读入排序后的数据集,插入FP树,插入时按照排序后的顺序,插入FP树中,排序靠前的节点是祖先节点,而靠后的是子孙节点。
如果有共用的祖先,则对应的公用祖先节点计数加1。插入后,如果有新节点出现,则项头表对应的节点会通过节点链表链接上新节点。直到所有的数据都插入到FP树后,FP树的建立完成。
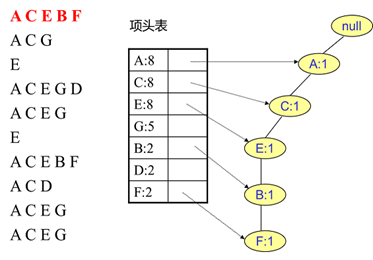
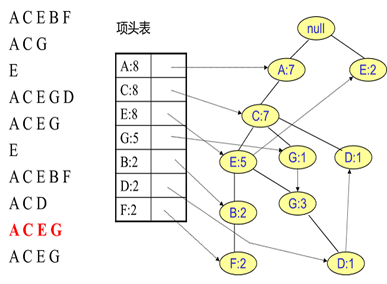
首先,插入第一条数据ACEBF,如下图所示。此时FP树没有节点,因此ACEBF是一个独立的路径,所有节点计数为1, 项头表通过节点链表链接上对应的新增节点。
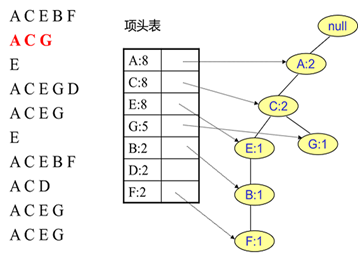
接着插入数据ACG,如下图所示。由于ACG和现有的FP树可以有共有的祖先节点序列AC,因此只需要增加一个新节点G,将新节点G的计数记为1。同时A和C的计数加1成为2。当然,对应的G节点的节点链表要更新。
同样的办法可以更新后面8条数据,如下8张图。由于原理类似,这里就不多文字讲解了,大家可以自己去尝试插入并进行理解对比。相信如果大家自己可以独立的插入这10条数据,那么FP树建立的过程就没有什么难度了。
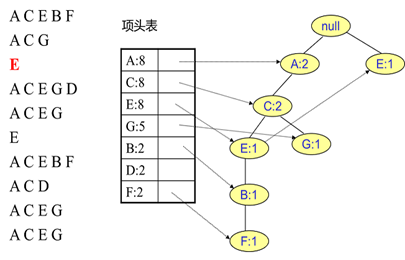
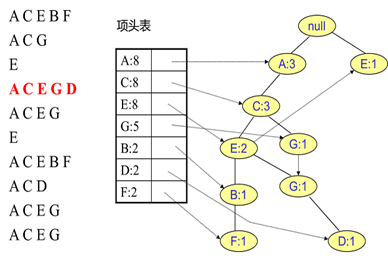
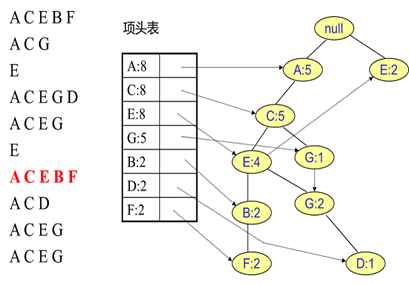
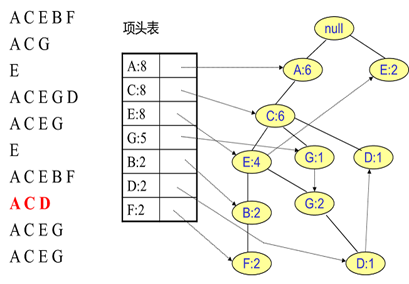
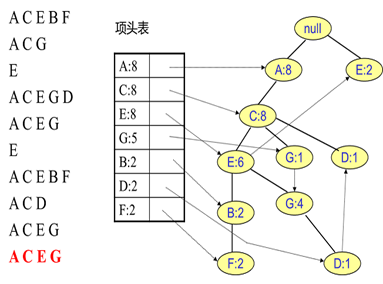
FP Tree 的使用
FP树建立起来了,那么怎么去挖掘频繁项集呢?
得到了FP树和项头表以及节点链表,首先要从项头表的底部项依次向上挖掘。
对于项头表对应于FP树的每一项,要找到它的条件模式基。
所谓条件模式基是以要挖掘的节点作为叶子节点所对应的FP子树。
得到这个FP子树,将子树中每个节点的的计数设置为叶子节点的计数,并删除计数低于支持度的节点。从这个条件模式基,就可以递归挖掘得到频繁项集了。
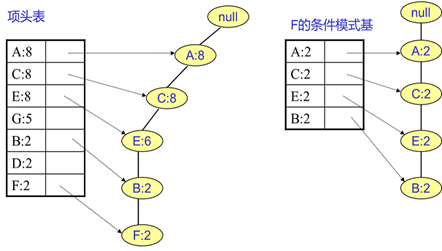
还是以上面的例子来讲解。看看先从最底下的F节点开始,先来寻找F节点的条件模式基,由于F在FP树中只有一个节点,因此候选就只有下图左所示的一条路径,对应{A:8,C:8,E:6,B:2,F:2}。接着将所有的祖先节点计数设置为叶子节点的计数,即FP子树变成{A:2,C:2,E:2,B:2, F:2}。一般条件模式基可以不写叶子节点,因此最终的F的条件模式基如下图右所示。通过它,很容易得到F的频繁2项集为{A:2,F:2}, {C:2,F:2}, {E:2,F:2}, {B:2,F:2}。递归合并二项集,得到频繁三项集为{A:2,C:2,F:2},{A:2,E:2,F:2},...还有一些频繁三项集,就不写了。当然一直递归下去,最大的频繁项集为频繁5项集,为{A:2,C:2,E:2,B:2,F:2}
F挖掘完了,开始挖掘D节点。
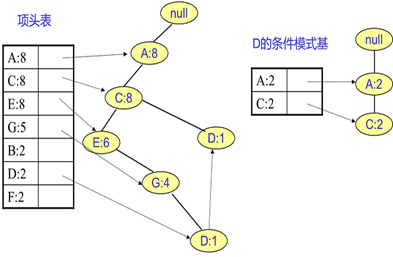
D节点比F节点复杂一些,因为它有两个叶子节点,因此首先得到的FP子树如下图左。接着将所有的祖先节点计数设置为叶子节点的计数,即变成{A:2, C:2,E:1 G:1,D:1, D:1}此时E节点和G节点由于在条件模式基里面的支持度低于阈值,被删除,最终在去除低支持度节点并不包括叶子节点后D的条件模式基为{A:2, C:2}。通过它,很容易得到D的频繁2项集为{A:2,D:2}, {C:2,D:2}。递归合并二项集,得到频繁三项集为{A:2,C:2,D:2}。D对应的最大的频繁项集为频繁3项集。
同样的方法可以得到B的条件模式基如下图右边,递归挖掘到B的最大频繁项集为频繁4项集{A:2, C:2, E:2,B:2}。
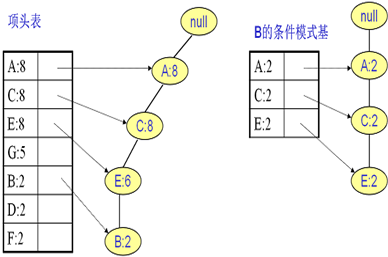
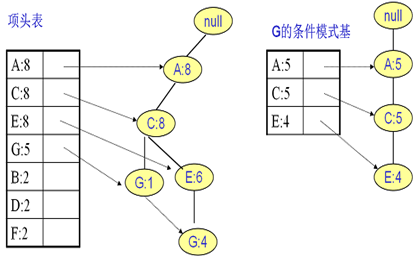
继续挖掘G的频繁项集,挖掘到的G的条件模式基如下图右边,递归挖掘到G的最大频繁项集为频繁4项集{A:5, C:5, E:4,G:4}。
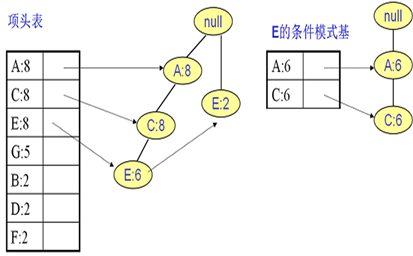
E的条件模式基如下图右边,递归挖掘到E的最大频繁项集为频繁3项集{A:6, C:6, E:6}。
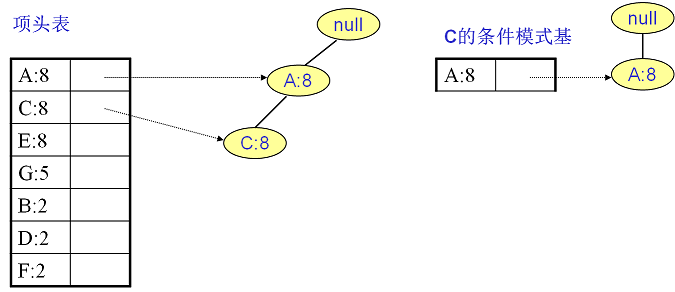
C的条件模式基如下图右边,递归挖掘到C的最大频繁项集为频繁2项集{A:8, C:8}。至于A,由于它的条件模式基为空,因此可以不用去挖掘了。
至此得到了所有的频繁项集,如果只是要最大的频繁K项集,从上面的分析可以看到,最大的频繁项集为5项集。包括{A:2, C:2, E:2,B:2,F:2}。
通过上面的流程,相信大家对FP Tree的挖掘频繁项集的过程也很熟悉了。
这里对FP Tree算法流程做一个归纳。FP Tree算法包括三步:
1)扫描数据,得到所有频繁一项集的的计数。然后删除支持度低于阈值的项,将1项频繁集放入项头表,并按照支持度降序排列。
2)扫描数据,将读到的原始数据剔除非频繁1项集,并按照支持度降序排列。
3)读入排序后的数据集,插入FP树,插入时按照排序后的顺序,插入FP树中,排序靠前的节点是祖先节点,而靠后的是子孙节点。如果有共用的祖先,则对应的公用祖先节点计数加1。插入后,如果有新节点出现,则项头表对应的节点会通过节点链表链接上新节点。直到所有的数据都插入到FP树后,FP树的建立完成。
4)从项头表的底部项依次向上找到项头表项对应的条件模式基。从条件模式基递归挖掘得到项头表项项的频繁项集。
5)如果不限制频繁项集的项数,则返回步骤4所有的频繁项集,否则只返回满足项数要求的频繁项集。
FP Tree算法改进了Apriori算法的I/O瓶颈,巧妙的利用了树结构,这让我们想起了BIRCH聚类,BIRCH聚类也是巧妙的利用了树结构来提高算法运行速度。利用内存数据结构以空间换时间是常用的提高算法运行时间瓶颈的办法。
在实践中,FP Tree算法是可以用于生产环境的关联算法,而Apriori算法则做为先驱,起着关联算法指明灯的作用。除了FP Tree,像GSP,CBA之类的算法都是Apriori派系的。
机器学习-FP Tree的更多相关文章
- FP Tree算法原理总结
在Apriori算法原理总结中,我们对Apriori算法的原理做了总结.作为一个挖掘频繁项集的算法,Apriori算法需要多次扫描数据,I/O是很大的瓶颈.为了解决这个问题,FP Tree算法(也称F ...
- 用Spark学习FP Tree算法和PrefixSpan算法
在FP Tree算法原理总结和PrefixSpan算法原理总结中,我们对FP Tree和PrefixSpan这两种关联算法的原理做了总结,这里就从实践的角度介绍如何使用这两个算法.由于scikit-l ...
- FP Tree算法原理总结(转载)
FP Tree算法原理总结 在Apriori算法原理总结中,我们对Apriori算法的原理做了总结.作为一个挖掘频繁项集的算法,Apriori算法需要多次扫描数据,I/O是很大的瓶颈.为了解决这个问题 ...
- 机器学习(十五)— Apriori算法、FP Growth算法
1.Apriori算法 Apriori算法是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策. Apriori算法采用了迭代的方法,先搜 ...
- 机器学习实战 - 读书笔记(12) - 使用FP-growth算法来高效发现频繁项集
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第12章 - 使用FP-growth算法来高效发现频繁项集. 基本概念 FP-growt ...
- Frequent Pattern 挖掘之二(FP Growth算法)(转)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- 关联规则算法之FP growth算法
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达到这样的效果,它采用了一种简洁的数据结 ...
- Frequent Pattern (FP Growth算法)
FP树构造 FP Growth算法利用了巧妙的数据结构,大大降低了Aproir挖掘算法的代价,他不需要不断得生成候选项目队列和不断得扫描整个数据库进行比对.为了达 到这样的效果,它采用了一种简洁的数据 ...
- Spark机器学习(9):FPGrowth算法
关联规则挖掘最典型的例子是购物篮分析,通过分析可以知道哪些商品经常被一起购买,从而可以改进商品货架的布局. 1. 基本概念 首先,介绍一些基本概念. (1) 关联规则:用于表示数据内隐含的关联性,一般 ...
随机推荐
- jquery-ui sortable 使用实例
jquery-ui sortable 使用实例 最近公司需要做任务看板,需要拖拽效果.点击查看效果.由于网站是基于vue的技术栈,最开始找了一个现成的vue封装的拖拽组件:Vue.Draggable, ...
- Git 常用命令大全(转)
Git 是一个很强大的分布式版本控制系统.它不但适用于管理大型开源软件的源代码,管理私人的文档和源代码也有很多优势. Git常用操作命令: 1) 远程仓库相关命令 检出仓库:$ git clone g ...
- ListView背景色突变问题
ListView中加入 android:cacheColorHint="#00000000" 的属性即可
- python发送邮件554DT:SPM已解决
说明:本例使用163邮箱 一.报错信息 使用SMTP发送邮件遇到以下报错: 554, b'DT:SPM 163 smtp10,DsCowACXeOtmjRRdsY8aCw--.21947S2 1561 ...
- 前后端分离时代,Java 程序员的变与不变!
事情的起因是这样的,有个星球的小伙伴向邀请松哥在知乎上回答一个问题,原题是: 前后端分离的时代,Java后台程序员的技术建议? 松哥认真看了下这个问题,感觉对于初次接触前后端分离的小伙伴来说,可能都会 ...
- spring_three
转账案例 坐标: ; } } 创建增强类Logger.java /** * 用于记录日志的工具类,它里面提供了公共的代码 */ @Component("logger") @Aspe ...
- spring 5.x 系列第7篇 —— 整合Redis客户端 Jedis和Redisson (xml配置方式)
文章目录 一.说明 1.1 Redis 客户端说明 1.2 Redis可视化软件 1.3 项目结构说明 1.3 依赖说明 二.spring 整合 jedis 2.1 新建基本配置文件 2.2 单机配置 ...
- git操作相关
-- 创建远程仓库 git init --bare git仓库文件夹名称 从远程仓库复制出本地仓库 git clone ./lth.git local 本地仓库和远程仓库的同步 本地仓库的配置文件co ...
- 【MySQL插入更新重复值】ON DUPLICATE KEY UPDATE用法
要插入的数据 与表中记录数据的 惟一索引或主键中产生重复值,那么就会发生旧行的更新 弊端:造成主键自增不连续.适合数据量不大的表. ON DUPLICATE KEY UPDATE后面的条件 eg有如 ...
- javascript函数详解
//函数的两种声明方式 //在同一个<script>标签中,函数的调用和声明位置可以没有先后的顺序,因为在同一个标签中,都是等加载到内存中,然后在运行 //但是如果是在两个script标枪 ...