TF-IDF算法——原理及实现
TF-IDF算法是一种用于信息检索与数据挖掘的常用加权技术。TF的意思是词频(Term - frequency),IDF的意思是逆向文件频率(inverse Document frequency).
TF-IDF是传统的统计算法,用于评估一个词在一个文档集中对于某一个文档的重要程度。它与这个词在当前文档中的词频成正比,与文档集中的其他词频成反比。
首先说一下TF(词频)的计算方法,TF指的是当前文档的词频,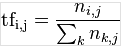 ,在这个公式中,分子表示的是改词在某一文档中出现的次数,分母表示在该文档中所有关键词出现的次数之和。
,在这个公式中,分子表示的是改词在某一文档中出现的次数,分母表示在该文档中所有关键词出现的次数之和。
然后来说下IDF(逆向词频)的计算方法,IDF指的是某个词汇普遍性的度量。 ,这个公式中,log内的部分,分子表示的是文档集中文档的个数,分母表示的是包含当前关键词的文档的个数,对于这个分数取对数,得到的就是,当前词汇的IDF的值。
,这个公式中,log内的部分,分子表示的是文档集中文档的个数,分母表示的是包含当前关键词的文档的个数,对于这个分数取对数,得到的就是,当前词汇的IDF的值。
下面,我来介绍下通过python对TF-IDF算法的设计及实现:
对象1:文章集(属性:文章对象的集合,包含关键字的文章数)
对象1: 文章(属性:关键词对象的集合;关键词出现的总次数;关键词对应对象的字典)
对象2:文章-关键词(属性:关键词名称;关键词在当前文章中出现的次数;TF_IDF)
实现流程:
1、创建文章对象,初始关键字的Map集
2、遍历关键字,每遍历一个关键字,
2.1 关键词出现的总次数加一
2.2 判断文章关键字中是够存在当前关键字,如果存在,找出他,加一,如果不存在,创建一个文章关键字对象,塞到文章的关键字的集中去;
2.3 若果这个关键字是第一次出现,则记录关键字出现的文章数(如果关键字在关键字-文章数 字典中存在,则文章数+1,否则将其加入到关键字-文章数字典中,并赋初始值1)
2.4 遍历完成,文章的关于关键词的Map集装载完成,然后将当前的文章add到文章集的对象中去
3 遍历文章集,计算出关键字对应的TF-IDF,并输出
实现代码:(实现代码以读取一个文件模拟多个文档)
# TF_IDF.py
# -*- coding: utf-8 -*-
import jieba
import math class DocumentSet():
documentList = []
key_Count = {} #关键词对应的文章数 class Document():
docKeySumCount=0 #文章中所有关键词总次数
docKeySet={} #关键词对象列表
def __init__(self,docid):
self.docid = docid class DocKey():
docKeyCount = 1 #当前关键词在当前文章中出现的次数
TF_IDF = 0 #当前关键词的TF-IDF值
def __init__(self,word):
self.word = word
f = open("C:/Users/zw/Desktop/key-words.txt", 'r')
line='start'
docList = DocumentSet()
while line:
line = f.readline()
datafile = line.split('\t')
if(datafile.__len__()>=2):
doc = Document(datafile[0])
wordList = list(jieba.cut(datafile[1]))
for i in wordList:
doc.docKeySumCount = doc.docKeySumCount + 1
if i not in doc.docKeySet.keys():
doc.docKeySet[i] = DocKey(i)
else:
doc.docKeySet[i].docKeyCount = doc.docKeySet[i].docKeyCount+1
#记录包含关键词的文章数
if doc.docKeySet[i].docKeyCount <= 1:
if i not in docList.key_Count.keys():
docList.key_Count[i]=1
else:
docList.key_Count[i]=docList.key_Count[i]+1
docList.documentList.append(doc)
f.close()
for d in docList.documentList:
for k in d.docKeySet.keys():
d.docKeySet[k].TF_IDF = d.docKeySet[k].docKeyCount/d.docKeySumCount + math.log(docList.documentList.__len__()/docList.key_Count[k])
print ('文章id :%s 关键字【%s】的TF-IDF值为:%s',d.docid ,k, d.docKeySet[k].TF_IDF)
TF-IDF算法——原理及实现的更多相关文章
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- 55.TF/IDF算法
主要知识点: TF/IDF算法介绍 查看es计算_source的过程及各词条的分数 查看一个document是如何被匹配到的 一.算法介绍 relevance score算法,简单来说 ...
- tf–idf算法解释及其python代码
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- 25.TF&IDF算法以及向量空间模型算法
主要知识点: boolean model IF/IDF vector space model 一.boolean model 在es做各种搜索进行打分排序时,会先用boolean mo ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
- 广告系统中weak-and算法原理及编码验证
wand(weak and)算法基本思路 一般搜索的query比较短,但如果query比较长,如是一段文本,需要搜索相似的文本,这时候一般就需要wand算法,该算法在广告系统中有比较成熟的应 该,主要 ...
随机推荐
- 洛谷 题解 P3871 【[TJOI2010]中位数】
这题先定义一个大根堆(maxn)维护mid(n为奇数mid+1)的元素.再定义一个小根堆(minn)维护mid(n为奇数mid+1)到n的元素.然后对于插入元素的情况进行分类讨论. 当add x时 一 ...
- 【Offer】[55-2] 【平衡二叉树】
题目描述 思路分析 测试用例 Java代码 代码链接 题目描述 输入一棵二叉树的根节点,判断该树是不是平衡二叉树.如果某二叉树中任意节点的左.右子树的深度相差不超过1,那么它就是一棵平衡二叉树.例如, ...
- 剑指Offer(三十二):把数组排成最小的数
剑指Offer(三十二):把数组排成最小的数 搜索微信公众号:'AI-ming3526'或者'计算机视觉这件小事' 获取更多算法.机器学习干货 csdn:https://blog.csdn.net/b ...
- Python 70行代码实现简单算式计算器
描述:用户输入一系列算式字符串,程序返回计算结果. 要求:不使用eval.exec函数. 实现思路:找到当前字符串优先级最高的表达式,在算术运算中,()优先级最高,则取出算式最底层的(),再进行加减乘 ...
- 联邦学习开源框架FATE助力腾讯神盾沙箱,携手打造数据安全合作生态
近日,微众银行联邦学习FATE开源社区迎来了两位新贡献者——来自腾讯的刘洋及秦姝琦,作为云计算安全领域的专家,两位为FATE构造了新的功能点,并在Github上提交修复了相关漏洞.(Github项目地 ...
- Django-下载安装-配置-创建django项目-三板斧简单使用
目录 Django 简介 使用 django 的注意事项 计算机名不能有中文 Django版本问题 django下载安装 在命令行下载安装 在pycharm图形界面下载安装 检验是否安装成功 创建Dj ...
- Scrapy框架的下载与安装
一.下载scrapy 首先,如果安装了anaconda, 可以直接在terminal窗口中输入: conda install scrapy 在图示符中,输入y, 表示继续处理信息 二.验证 是否安装成 ...
- TypeScript模块系统、命名空间、声明合并
命名空间 命名空间能有效避免全局污染.在ES6引入模块之后,命名空间就较少被提及了.如果使用了全局的类库,命名空间仍是一个好的解决方案. namespace Shape{ const pi = Mat ...
- IntelliJ IDEA 设置 vue 支持
一.IntelliJ IDEA支持.vue文件 安装vue.js file --> settings --> plugins,输入vue,点击搜索结果里的vue.js右边的install按 ...
- cmd命令查看已连接的WiFi密码
实验环境:Windows 10.命令提示符(管理员权限) 一.CMD命令查看WiFi密码 使用方法: ①.运行CMD(命令提示符) (确保无线网卡启用状态)②.输入命令查看WiFi配置文件: # ...