Hive 系列(三)—— Hive CLI 和 Beeline 命令行的基本使用
一、Hive CLI
1.1 Help
使用 hive -H 或者 hive --help 命令可以查看所有命令的帮助,显示如下:
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B --定义用户自定义变量
--database <databasename> Specify the database to use -- 指定使用的数据库
-e <quoted-query-string> SQL from command line -- 执行指定的 SQL
-f <filename> SQL from files --执行 SQL 脚本
-H,--help Print help information -- 打印帮助信息
--hiveconf <property=value> Use value for given property --自定义配置
--hivevar <key=value> Variable subsitution to apply to hive --自定义变量
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file --在进入交互模式之前运行初始化脚本
-S,--silent Silent mode in interactive shell --静默模式
-v,--verbose Verbose mode (echo executed SQL to the console) --详细模式1.2 交互式命令行
直接使用 Hive 命令,不加任何参数,即可进入交互式命令行。
1.3 执行SQL命令
在不进入交互式命令行的情况下,可以使用 hive -e 执行 SQL 命令。
hive -e 'select * from emp';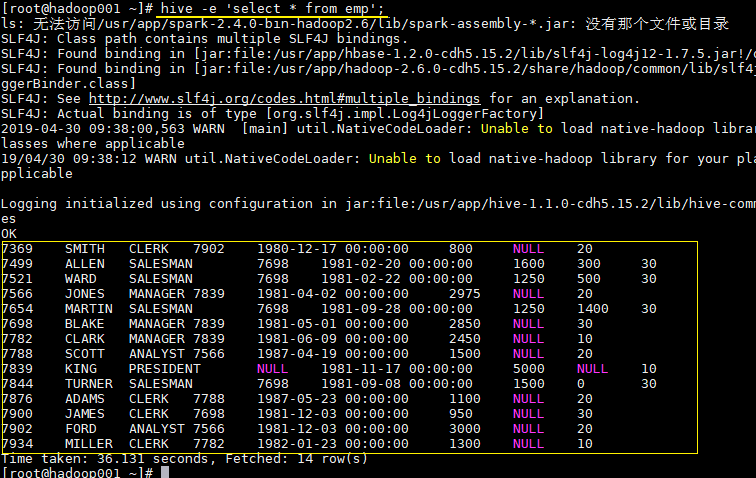
1.4 执行SQL脚本
用于执行的 sql 脚本可以在本地文件系统,也可以在 HDFS 上。
# 本地文件系统
hive -f /usr/file/simple.sql;
# HDFS文件系统
hive -f hdfs://hadoop001:8020/tmp/simple.sql;其中 simple.sql 内容如下:
select * from emp;1.5 配置Hive变量
可以使用 --hiveconf 设置 Hive 运行时的变量。
hive -e 'select * from emp' \
--hiveconf hive.exec.scratchdir=/tmp/hive_scratch \
--hiveconf mapred.reduce.tasks=4;hive.exec.scratchdir:指定 HDFS 上目录位置,用于存储不同 map/reduce 阶段的执行计划和这些阶段的中间输出结果。
1.6 配置文件启动
使用 -i 可以在进入交互模式之前运行初始化脚本,相当于指定配置文件启动。
hive -i /usr/file/hive-init.conf;其中 hive-init.conf 的内容如下:
set hive.exec.mode.local.auto = true;hive.exec.mode.local.auto 默认值为 false,这里设置为 true ,代表开启本地模式。
1.7 用户自定义变量
--define <key=value> 和 --hivevar <key=value> 在功能上是等价的,都是用来实现自定义变量,这里给出一个示例:
定义变量:
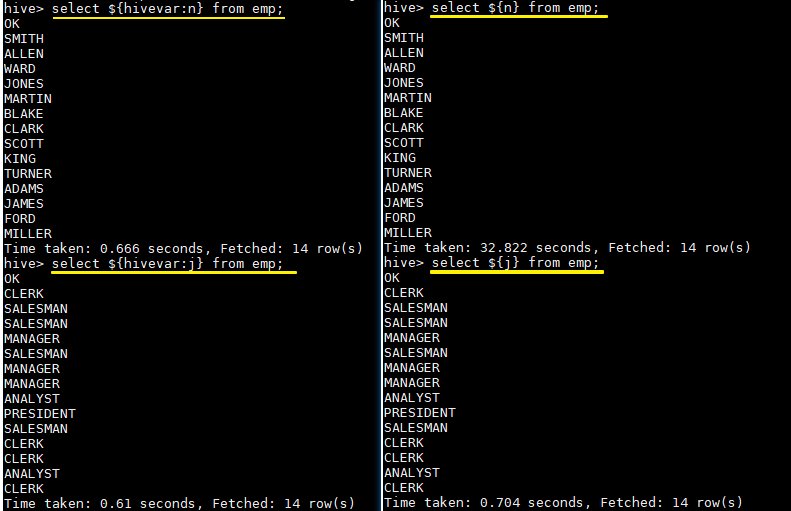
hive --define n=ename --hiveconf --hivevar j=job;在查询中引用自定义变量:
# 以下两条语句等价
hive > select ${n} from emp;
hive > select ${hivevar:n} from emp;
# 以下两条语句等价
hive > select ${j} from emp;
hive > select ${hivevar:j} from emp;结果如下:
二、Beeline
2.1 HiveServer2
Hive 内置了 HiveServer 和 HiveServer2 服务,两者都允许客户端使用多种编程语言进行连接,但是 HiveServer 不能处理多个客户端的并发请求,所以产生了 HiveServer2。
HiveServer2(HS2)允许远程客户端可以使用各种编程语言向 Hive 提交请求并检索结果,支持多客户端并发访问和身份验证。HS2 是由多个服务组成的单个进程,其包括基于 Thrift 的 Hive 服务(TCP 或 HTTP)和用于 Web UI 的 Jetty Web 服务器。
HiveServer2 拥有自己的 CLI(Beeline),Beeline 是一个基于 SQLLine 的 JDBC 客户端。由于 HiveServer2 是 Hive 开发维护的重点 (Hive0.15 后就不再支持 hiveserver),所以 Hive CLI 已经不推荐使用了,官方更加推荐使用 Beeline。
2.1 Beeline
Beeline 拥有更多可使用参数,可以使用 beeline --help 查看,完整参数如下:
Usage: java org.apache.hive.cli.beeline.BeeLine
-u <database url> the JDBC URL to connect to
-r reconnect to last saved connect url (in conjunction with !save)
-n <username> the username to connect as
-p <password> the password to connect as
-d <driver class> the driver class to use
-i <init file> script file for initialization
-e <query> query that should be executed
-f <exec file> script file that should be executed
-w (or) --password-file <password file> the password file to read password from
--hiveconf property=value Use value for given property
--hivevar name=value hive variable name and value
This is Hive specific settings in which variables
can be set at session level and referenced in Hive
commands or queries.
--property-file=<property-file> the file to read connection properties (url, driver, user, password) from
--color=[true/false] control whether color is used for display
--showHeader=[true/false] show column names in query results
--headerInterval=ROWS; the interval between which heades are displayed
--fastConnect=[true/false] skip building table/column list for tab-completion
--autoCommit=[true/false] enable/disable automatic transaction commit
--verbose=[true/false] show verbose error messages and debug info
--showWarnings=[true/false] display connection warnings
--showNestedErrs=[true/false] display nested errors
--numberFormat=[pattern] format numbers using DecimalFormat pattern
--force=[true/false] continue running script even after errors
--maxWidth=MAXWIDTH the maximum width of the terminal
--maxColumnWidth=MAXCOLWIDTH the maximum width to use when displaying columns
--silent=[true/false] be more silent
--autosave=[true/false] automatically save preferences
--outputformat=[table/vertical/csv2/tsv2/dsv/csv/tsv] format mode for result display
--incrementalBufferRows=NUMROWS the number of rows to buffer when printing rows on stdout,
defaults to 1000; only applicable if --incremental=true
and --outputformat=table
--truncateTable=[true/false] truncate table column when it exceeds length
--delimiterForDSV=DELIMITER specify the delimiter for delimiter-separated values output format (default: |)
--isolation=LEVEL set the transaction isolation level
--nullemptystring=[true/false] set to true to get historic behavior of printing null as empty string
--maxHistoryRows=MAXHISTORYROWS The maximum number of rows to store beeline history.
--convertBinaryArrayToString=[true/false] display binary column data as string or as byte array
--help display this message
2.3 常用参数
在 Hive CLI 中支持的参数,Beeline 都支持,常用的参数如下。更多参数说明可以参见官方文档 Beeline Command Options
| 参数 | 说明 |
|---|---|
| -u <database URL> | 数据库地址 |
| -n <username> | 用户名 |
| -p <password> | 密码 |
| -d <driver class> | 驱动 (可选) |
| -e <query> | 执行 SQL 命令 |
| -f <file> | 执行 SQL 脚本 |
| -i (or)--init <file or files> | 在进入交互模式之前运行初始化脚本 |
| --property-file <file> | 指定配置文件 |
| --hiveconf property=value | 指定配置属性 |
| --hivevar name=value | 用户自定义属性,在会话级别有效 |
示例: 使用用户名和密码连接 Hive
$ beeline -u jdbc:hive2://localhost:10000 -n username -p password
三、Hive配置
可以通过三种方式对 Hive 的相关属性进行配置,分别介绍如下:
3.1 配置文件
方式一为使用配置文件,使用配置文件指定的配置是永久有效的。Hive 有以下三个可选的配置文件:
hive-site.xml :Hive 的主要配置文件;
- hivemetastore-site.xml: 关于元数据的配置;
hiveserver2-site.xml:关于 HiveServer2 的配置。
示例如下,在 hive-site.xml 配置 hive.exec.scratchdir:
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/mydir</value>
<description>Scratch space for Hive jobs</description>
</property>3.2 hiveconf
方式二为在启动命令行 (Hive CLI / Beeline) 的时候使用 --hiveconf 指定配置,这种方式指定的配置作用于整个 Session。
hive --hiveconf hive.exec.scratchdir=/tmp/mydir3.3 set
方式三为在交互式环境下 (Hive CLI / Beeline),使用 set 命令指定。这种设置的作用范围也是 Session 级别的,配置对于执行该命令后的所有命令生效。set 兼具设置参数和查看参数的功能。如下:
0: jdbc:hive2://hadoop001:10000> set hive.exec.scratchdir=/tmp/mydir;
No rows affected (0.025 seconds)
0: jdbc:hive2://hadoop001:10000> set hive.exec.scratchdir;
+----------------------------------+--+
| set |
+----------------------------------+--+
| hive.exec.scratchdir=/tmp/mydir |
+----------------------------------+--+3.4 配置优先级
配置的优先顺序如下 (由低到高):
hive-site.xml - >hivemetastore-site.xml- > hiveserver2-site.xml - >-- hiveconf- > set
3.5 配置参数
Hive 可选的配置参数非常多,在用到时查阅官方文档即可AdminManual Configuration
参考资料
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
Hive 系列(三)—— Hive CLI 和 Beeline 命令行的基本使用的更多相关文章
- Hive 学习之路(三)—— Hive CLI和Beeline命令行的基本使用
一.Hive CLI 1.1 Help 使用hive -H或者 hive --help命令可以查看所有命令的帮助,显示如下: usage: hive -d,--define <key=value ...
- Hive Beeline 命令行参数
[hadoop@hive ~]$ beeline --help[中文版] The Beeline CLI 支持以下命令行参数: Option Description --autoCommit=[tru ...
- 入门大数据---HiveCLI和Beeline命令行的基本使用
一.Hive CLI 1.1 Help 使用 hive -H 或者 hive --help 命令可以查看所有命令的帮助,显示如下: usage: hive -d,--define <key=va ...
- cli框架 获取 命令行 参数
package main import ( "fmt" "log" "os" "github.com/urfave/cli&quo ...
- hive学习(三) hive的分区
1.Hive 分区partition 必须在表定义时指定对应的partition字段 a.单分区建表语句: create table day_table (id int, content string ...
- 三,JVM 自带命令行工具之JMap
jmap:java内存映像工具 jmap(Memory Map for java ) 命令用于生成堆转储快照(一般被称为headdump 或dump文件) jmap命令格式:jmap [option ...
- [Go] gocron源码阅读-通过第三方cli包实现命令行参数获取和管理
gocron源码中使用的是下面这个第三方包来实现的,下面就单独的拿出来测试以下效果,和官方flag包差不多 go get github.com/urfave/cli package main impo ...
- Hadoop Hive概念学习系列之hive里的扩展接口(CLI、Beeline、JDBC)(十六)
<Spark最佳实战 陈欢>写的这本书,关于此知识点,非常好,在94页. hive里的扩展接口,主要包括CLI(控制命令行接口).Beeline和JDBC等方式访问Hive. CLI和B ...
- Hive 系列(一)安装部署
Hive 系列(一)安装部署 Hive 官网:http://hive.apache.org.参考手册 一.环境准备 JDK 1.8 :从 Oracle 官网下载,设置环境变量(JAVA_HOME.PA ...
随机推荐
- xshell && xftp 下载
链接:https://pan.baidu.com/s/1aLdgOSshytIYhArkB7tghQ 提取码:fqjb
- 第10组 团队Git现场编程实战
组员职责分工 姓名 分工 童景霖 博客 朱晓倩 制作UI 万本琳 制作UI 唐怡 制作UI 陈心怡 制作UI 黄永福 测评福州最受欢迎的商圈.后期代码修改和完善 郑志强 测评各个价位的前五美食餐厅代码 ...
- fiddler自动生成jmeter测试脚本
概述 昨天我们在课堂上讲了如何通过fiddler抓包,单一接口可以复制到jmeter中进行接口测试,那么如果抓包获取了大量的接口,我们如何快速实现接口转换成jmx文件呢? 今天给大家介绍fiddler ...
- “未在本地计算机上注册“Microsoft.Jet.OLEDB.4.0”提供程序
一.背景: 开发一个工具的小项目,因为数据少,我就不想安装sqlserver数据库,就用Access数据库. 二.问题: 在客户安装程序的时候,接口访问Access数据库的时候,报错“未在本地计算机上 ...
- PowerDesigner应用01 逆向工程之配置数据源并导出PDM文件
物理数据模型(Physical Data Model)PDM,提供了系统初始设计所需要的基础元素,以及相关元素之间的关系:数据库的物理设计阶段必须在此基础上进行详细的后台设计,包括数据库的存储过程.操 ...
- FZU Monthly-201906 获奖名单
FZU Monthly-201906 获奖名单 冠军: 空缺 一等奖: 陈金杰 S031702334 空缺 二等奖: 黄海东 S031702647 吴宜航 S031702645 蔡煜晖 S111801 ...
- 冰多多团队-第六次Scrum会议
冰多多团队-第六次Scrum会议 工作情况 团队成员 已完成任务 待完成任务 zpj ASR bug修复 接入IAT模块 牛雅哲 完成语音识别->词典->termux的接口设计,熟悉了语法 ...
- HTML5快速写页面的方法
1 如果有原型的HTML页面(Axure导出来),可以在此从F12的“查看器”基础上拷贝到一个新文件,继续写代码. 2 利用EditPlus软件的工具 3 使用Dreamweaver CS5,可以直观 ...
- golang调用c动态库
golang调用c动态库 简介 golang调用c语言动态库,动态方式调用,可指定动态库路径,无需系统目录下 核心技术点 封装c动态库 go语言调用c代码 实例代码 封装c动态库 头文件 test_s ...
- Sword 哈希表
哈希表 哈希表是一种典型的以空间换取时间的数据结构,在没有冲突的情况下,对任意元素的插入.索引.删除的时间复杂度都是O().这样优秀的时间复杂度是通过将元素的key值以hash方法f映射到哈希表中的某 ...