MapTask工作机制
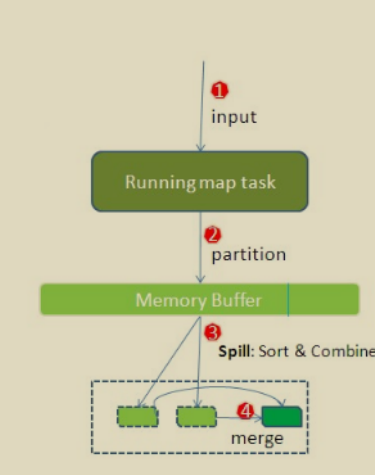
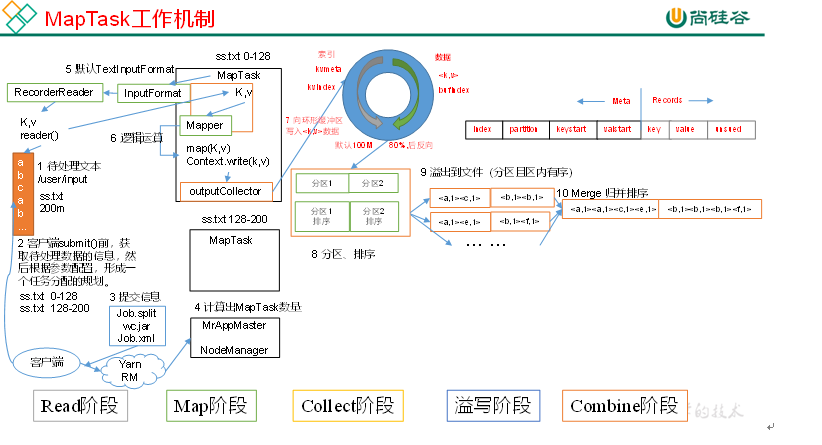
(1)Read阶段:MapTask通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
(2)Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。
(3)Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。
(4)Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
溢写阶段详情:
步骤1:利用快速排序算法对缓存区内的数据进行排序,排序方式是,先按照分区编号Partition进行排序,然后按照key进行排序。这样,经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序。
步骤2:按照分区编号由小到大依次将每个分区中的数据写入任务工作目录下的临时文件output/spillN.out(N表示当前溢写次数)中。如果用户设置了Combiner,则写入文件之前,对每个分区中的数据进行一次聚集操作。
步骤3:将分区数据的元信息写到内存索引数据结构SpillRecord中,其中每个分区的元信息包括在临时文件中的偏移量、压缩前数据大小和压缩后数据大小。如果当前内存索引大小超过1MB,则将内存索引写到文件output/spillN.out.index中。
(5)Combine阶段:当所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
当所有数据处理完后,MapTask会将所有临时文件合并成一个大文件,并保存到文件output/file.out中,同时生成相应的索引文件output/file.out.index。
在进行文件合并过程中,MapTask以分区为单位进行合并。对于某个分区,它将采用多轮递归合并的方式。每轮合并io.sort.factor(默认10)个文件,并将产生的文件重新加入待合并列表中,对文件排序后,重复以上过程,直到最终得到一个大文件。
让每个MapTask最终只生成一个数据文件,可避免同时打开大量文件和同时读取大量小文件产生的随机读取带来的开销。
MapTask工作机制的更多相关文章
- 【大数据】MapTask工作机制
1.MapTask工作机制 整个map阶段流程大体如上图所示.简单概述:input File通过getSplits被逻辑切分为多个split文件,通通过RecordReader(默认使用lineRec ...
- MapReduce之MapTask工作机制
1. 阶段定义 MapTask:map----->sort map:Mapper.map()中将输出的key-value写出之前 sort:Mapper.map()中将输出的key-value写 ...
- MapReduce框架原理-MapTask工作机制
MapReduce框架原理-MapTask工作机制 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. maptask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速 ...
- MapReduce框架原理-MapTask和ReduceTask工作机制
MapTask工作机制 并行度决定机制 1)问题引出 maptask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速度.那么,mapTask并行任务是否越多越好呢? 2)MapTa ...
- 浅谈MapReduce工作机制
1.MapTask工作机制 整个map阶段流程大体如上图所示.简单概述:input File通过getSplits被逻辑切分为多个split文件,通通过RecordReader(默认使用lineRec ...
- Hadoop MapReduce 一文详解MapReduce及工作机制
@ 目录 前言-MR概述 1.Hadoop MapReduce设计思想及优缺点 设计思想 优点: 缺点: 2. Hadoop MapReduce核心思想 3.MapReduce工作机制 剖析MapRe ...
- MapReduce06 MapReduce工作机制
目录 5 MapReduce工作机制(重点) 5.1 MapTask工作机制 5.2 ReduceTask工作机制 5.3 ReduceTask并行度决定机制 手动设置ReduceTask数量 测试R ...
- hadoop MapReduce 工作机制
摸索了将近一个月的hadoop , 在centos上配了一个伪分布式的环境,又折腾了一把hadoop eclipse plugin,最后终于实现了在windows上编写MapReduce程序,在cen ...
- MapRdeuce&Yarn的工作机制(YarnChild是什么)
MapRdeuce&Yarn的工作机制 一幅图解决你所有的困惑 那天在集群中跑一个MapReduce的程序时,在机器上jps了一下发现了每台机器中有好多个YarnChild.困惑什么时Yarn ...
随机推荐
- 关于AQS的一点总结
关于AQS的一点总结 2017年03月13日 09:48:13 那只是一股逆流 阅读数:772 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net/ ...
- servlet规范--Servlet 规范其实就是对 HTTP 协议做面向对象的封装
Servlet规范 一个最基本的 Java Web 项目所需的 jar 包只需要一个 servlet-api.jar ,这个 jar 包中的类大部分都是接口,还有一些工具类,共有 2 个包,分别是 j ...
- K8S学习笔记之使用Fluent-bit将容器标准输入和输出的日志发送到Kafka
0x00 概述 K8S内部署微服务后,对应的日志方案是不落地方案,即微服务的日志不挂在到本地数据卷,所有的微服务日志都采用标准输入和输出的方式(stdin/stdout/stderr)存放到管道内,容 ...
- ASP.NETCore 3.0 Autofac替换及控制器属性注入及全局容器使用
1.Autofac基础使用 参考: https://www.cnblogs.com/li150dan/p/10071079.html 2.ASP.NETCore 3.0 Autofac 容器替换 需要 ...
- element-ui 上传图片或视频时,先回显在上传
<el-upload class="upload-demo" ref="vidos" :action="URL+'/api/post/file' ...
- 35、element ui tab切换加载echarts不显示或显示不全问题解决:
<el-tabs v-model="activeName" @tab-click="handleClick" type="border-card ...
- Java 之 System 类
java.lang.System 类中提供了大量的静态方法,可以获取与系统相关的信息或系统级操作. 一.标准输入.标准输出和错误输出流对象 PrintStream err:“标准”错误输出流. Inp ...
- [转] Cache 和 Buffer的区别
程序员开发过程中经常会遇到“缓存”.“缓冲”等相似概念,之前没有特别关注,现在停下来做一下总结,才能更好地前行. 先来下枯燥的概念: 1.Cache:缓存区,是高速缓存,是位于CPU和主内存之间的容量 ...
- 数据结构与算法—simhash
引入 随着信息爆炸时代的来临,互联网上充斥着着大量的近重复信息,有效地识别它们是一个很有意义的课题. 例如,对于搜索引擎的爬虫系统来说,收录重复的网页是毫无意义的,只会造成存储和计算资源的浪费: 同时 ...
- Win10 Microsoft Store 微软商店 Error 0x00000193 解决方法
0x00 前言 最近使用 CFW 过程中使用 Fiddle Web Debug 设置 Store 的回环代理的过程中发现无论是否使用代理,Store 都无法访问网络的问题,在最下面的提示中出现了 0x ...