MapReduce06 MapReduce工作机制
5 MapReduce工作机制(重点)
5.1 MapTask工作机制
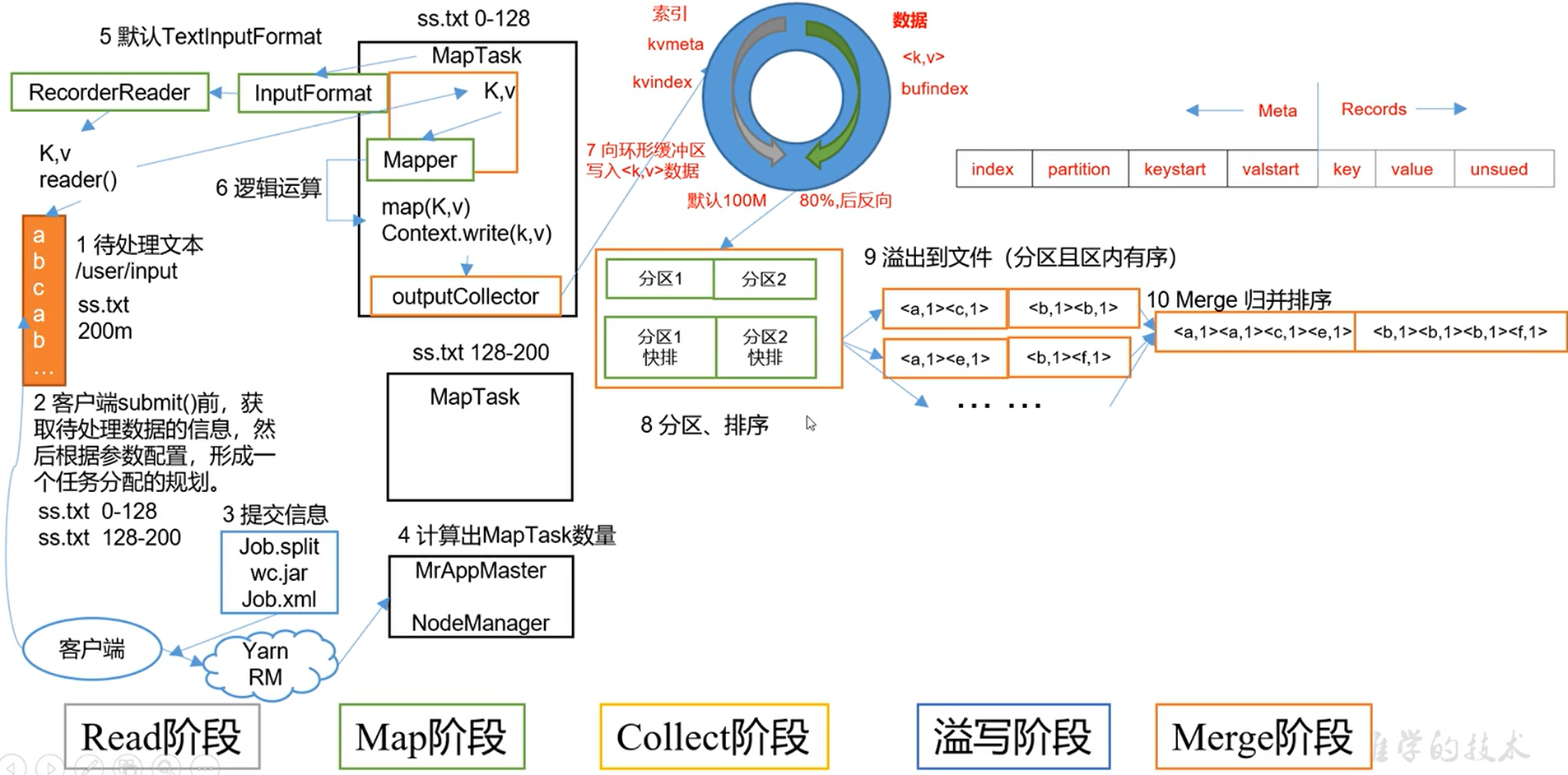
Read阶段
主要是Job的提交流程
1.切片划分
2.提交给Yarn
Job.split 切片信息
wc.jar 集群模式会提交,本地模式不会提交
Job.xml 配置信息
3.Yarn开启NodeManager(单个节点服务器资源老大) AppMaster(单个任务运行的老大) AppMaster开启对应的MapTask进入Map阶段
4.由InputFormat读取数据,默认TextInputFormat,读完之后返回给map,进入用户自己写的Mapper。一个MapTask产生一个文件
5.2 ReduceTask工作机制
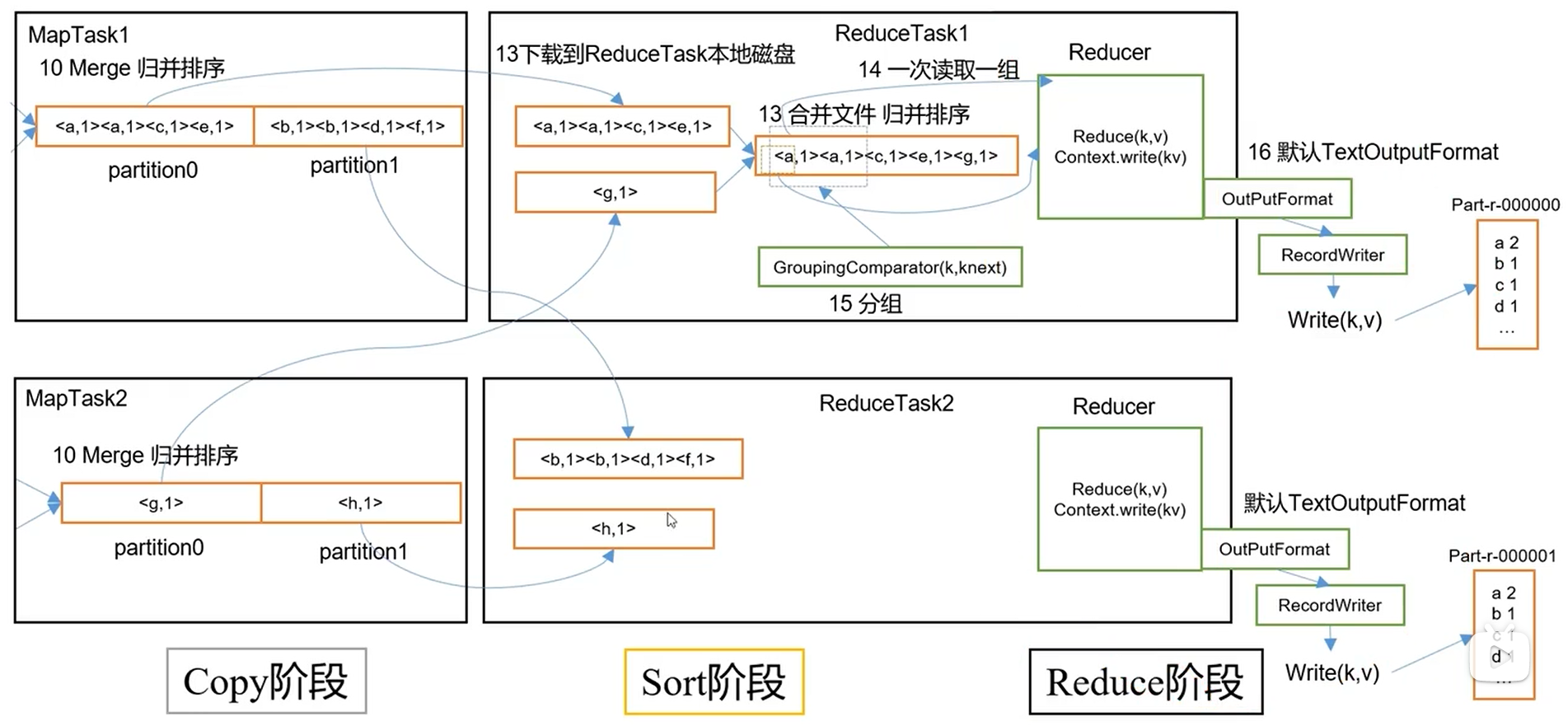
ReduceTask主动去抓取数据
5.3 ReduceTask并行度决定机制
MapTask并行度由切片个数决定,切片个数由输入文件和切片规则决定。
computeSplitSize(Math.max(minSize,Math.min(maxSize,blocksize)))
ReduceTask并行度由谁决定?
手动设置ReduceTask数量
//设置ReduceTasks的个数
job.setNumReduceTasks(5);
测试ReduceTask多少合适
注意事项
1.ReduceTask=0,表示没有Reduce阶段,输出文件个数和Map个数一致。
2.ReduceTask默认值就是1,所以输出文件个数为一个。
3.如果数据分布不均匀,就有可能在Reduce阶段产生数据倾斜(如136 1亿个,其他1个)
4.ReduceTask数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个ReduceTask。
5.具体多少个ReduceTask,需要根据集群性能而定。
6.如果分区数不是1,但是ReduceTask为1,是否执行分区过程。答案是:不执行分区过程。因为在MapTask的源码中,执行分区的前提是先判断ReduceNum个数是否大于1。不大于1肯定不执行。
MapReduce06 MapReduce工作机制的更多相关文章
- hadoop MapReduce 工作机制
摸索了将近一个月的hadoop , 在centos上配了一个伪分布式的环境,又折腾了一把hadoop eclipse plugin,最后终于实现了在windows上编写MapReduce程序,在cen ...
- MapReduce工作机制——Word Count实例(一)
MapReduce工作机制--Word Count实例(一) MapReduce的思想是分布式计算,也就是分而治之,并行计算提高速度. 编程思想 首先,要将数据抽象为键值对的形式,map函数输入键值对 ...
- hadoop知识点总结(一)hadoop架构以及mapreduce工作机制
1,为什么需要hadoop 数据分析者面临的问题 数据日趋庞大,读写都出现性能瓶颈: 用户的应用和分析结果,对实时性和响应时间要求越来越高: 使用的模型越来越复杂,计算量指数级上升. 期待的解决方案 ...
- 浅谈MapReduce工作机制
1.MapTask工作机制 整个map阶段流程大体如上图所示.简单概述:input File通过getSplits被逻辑切分为多个split文件,通通过RecordReader(默认使用lineRec ...
- [hadoop读书笔记] 第五章 MapReduce工作机制
P205 MapReduce的两种运行机制 第一种:经典的MR运行机制 - MR 1 可以通过一个简单的方法调用来运行MR作业:Job对象上的submit().也可以调用waitForCompleti ...
- MapReduce工作机制
MapReduce是什么? MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,MapReduce程序本质上是并行运行的,因此可以解决海量数据的计算问题. MapReduce ...
- yarn/mapreduce工作机制及mapreduce客户端代码编写
首先需要知道的就是在老版本的hadoop中是没有yarn的,mapreduce既负责资源分配又负责业务逻辑处理.为了解耦,把资源分配这块抽了出来,形成了yarn,这样不仅mapreudce可以用yar ...
- 图文详解MapReduce工作机制
job提交阶段 1.准备好待处理文本. 2.客户端submit()前,获取待处理数据的信息,然后根据参数配置,形成一个任务分配的规划. 3.客户端向Yarn请求创建MrAppMaster并提交切片等相 ...
- MapReduce的工作机制
<Hadoop权威指南>中的MapReduce工作机制和Shuffle: 框架 Hadoop2.x引入了一种新的执行机制MapRedcue 2.这种新的机制建议在Yarn的系统上,目前用于 ...
随机推荐
- 数列极限计算中运用皮亚诺Taylor展开巧解
这是讲义里比较精华的几个题目,今晚翻看也是想到了,总结出来(处理k/n2形式). 推广式子如下: 例题如下:
- NavigationView使用简介
Android支持直接创建带有NavigationView的Activity,这里主要介绍NavigationView的逻辑. NavigationView通常是跟DrawerLayout一起使用.D ...
- OpenWrt编译问题记录
错误一.config.status: error: cannot find input file: `xmetadataretriever/Makefile.in' configure: creati ...
- Python matplotlib pylot和pylab的区别
matplotlib是Python中强大的绘图库. matplotlib下pyplot和pylab均可以绘图. 具体来说两者的区别 pyplot 方便快速绘制matplotlib通过pyplot模块提 ...
- Linux使用ssh测试端口
在windows上可以使用telnet客户端测试,在linux如果不方便安装telnet客户端的时候可以通关ssh来测试端口 具体命令如下 ssh -v -p 8080 root@59.207.252 ...
- 一文搞懂js中的typeof用法
基础 typeof 运算符是 javascript 的基础知识点,尽管它存在一定的局限性(见下文),但在前端js的实际编码过程中,仍然是使用比较多的类型判断方式. 因此,掌握该运算符的特点,对于写出好 ...
- rocketmq广播消息的(五)
一.简介 广播消费指的是:一条消息被多个consumer消费,即使这些consumer属于同一个ConsumerGroup,消息也会被ConsumerGroup中的每个Consumer都消费一次,广播 ...
- spring笔记-MultiValueMap
即一个键对应多个值,Spring的内部实现是LinkedMultiValueMap MultiValueMap接口 一键多值的使用场景是比较多的,在使用该数据结构之前,通常会自己定义 Map<K ...
- [后端及服务器][WSL2(Ubuntu)+Docker]从零开始在WSL中安装Docker
目录 简介 WSL 安装 开启虚拟化(BIOS) 检查系统版本 安装WSL 老版本安装详情 简介 想花三篇文章写下从Windows(WSL)上开启Docker部署php/node/vue/html等项 ...
- 使用json.net实现复杂对象转换为QueryString
目标:生成复杂对象的QueryString,比如 new { Field1 = 1, Field2 = new { Field3 = "2", Field4 = new[] { n ...