MapTask工作机制
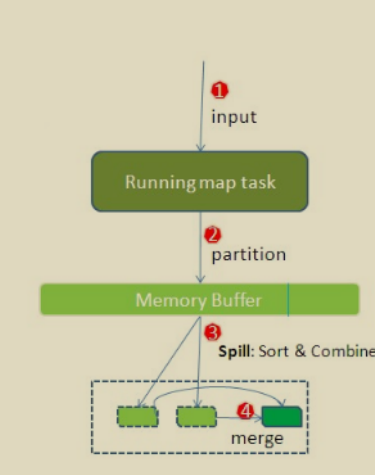
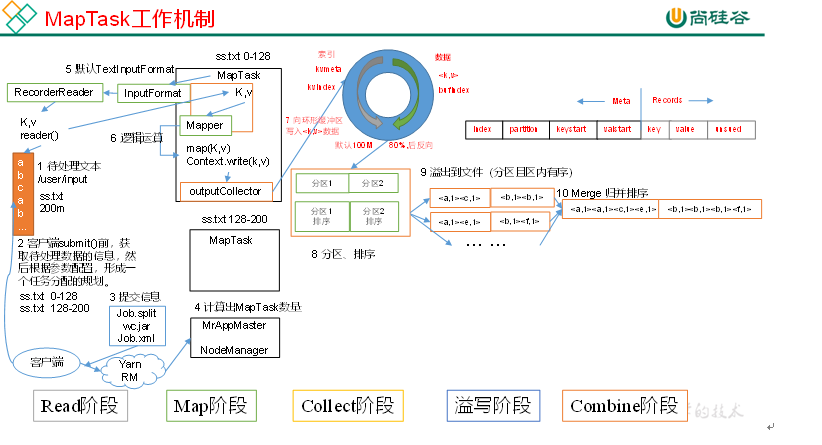
(1)Read阶段:MapTask通过用户编写的RecordReader,从输入InputSplit中解析出一个个key/value。
(2)Map阶段:该节点主要是将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。
(3)Collect收集阶段:在用户编写map()函数中,当数据处理完成后,一般会调用OutputCollector.collect()输出结果。在该函数内部,它会将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。
(4)Spill阶段:即“溢写”,当环形缓冲区满后,MapReduce会将数据写到本地磁盘上,生成一个临时文件。需要注意的是,将数据写入本地磁盘之前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
溢写阶段详情:
步骤1:利用快速排序算法对缓存区内的数据进行排序,排序方式是,先按照分区编号Partition进行排序,然后按照key进行排序。这样,经过排序后,数据以分区为单位聚集在一起,且同一分区内所有数据按照key有序。
步骤2:按照分区编号由小到大依次将每个分区中的数据写入任务工作目录下的临时文件output/spillN.out(N表示当前溢写次数)中。如果用户设置了Combiner,则写入文件之前,对每个分区中的数据进行一次聚集操作。
步骤3:将分区数据的元信息写到内存索引数据结构SpillRecord中,其中每个分区的元信息包括在临时文件中的偏移量、压缩前数据大小和压缩后数据大小。如果当前内存索引大小超过1MB,则将内存索引写到文件output/spillN.out.index中。
(5)Combine阶段:当所有数据处理完成后,MapTask对所有临时文件进行一次合并,以确保最终只会生成一个数据文件。
当所有数据处理完后,MapTask会将所有临时文件合并成一个大文件,并保存到文件output/file.out中,同时生成相应的索引文件output/file.out.index。
在进行文件合并过程中,MapTask以分区为单位进行合并。对于某个分区,它将采用多轮递归合并的方式。每轮合并io.sort.factor(默认10)个文件,并将产生的文件重新加入待合并列表中,对文件排序后,重复以上过程,直到最终得到一个大文件。
让每个MapTask最终只生成一个数据文件,可避免同时打开大量文件和同时读取大量小文件产生的随机读取带来的开销。
MapTask工作机制的更多相关文章
- 【大数据】MapTask工作机制
1.MapTask工作机制 整个map阶段流程大体如上图所示.简单概述:input File通过getSplits被逻辑切分为多个split文件,通通过RecordReader(默认使用lineRec ...
- MapReduce之MapTask工作机制
1. 阶段定义 MapTask:map----->sort map:Mapper.map()中将输出的key-value写出之前 sort:Mapper.map()中将输出的key-value写 ...
- MapReduce框架原理-MapTask工作机制
MapReduce框架原理-MapTask工作机制 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. maptask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速 ...
- MapReduce框架原理-MapTask和ReduceTask工作机制
MapTask工作机制 并行度决定机制 1)问题引出 maptask的并行度决定map阶段的任务处理并发度,进而影响到整个job的处理速度.那么,mapTask并行任务是否越多越好呢? 2)MapTa ...
- 浅谈MapReduce工作机制
1.MapTask工作机制 整个map阶段流程大体如上图所示.简单概述:input File通过getSplits被逻辑切分为多个split文件,通通过RecordReader(默认使用lineRec ...
- Hadoop MapReduce 一文详解MapReduce及工作机制
@ 目录 前言-MR概述 1.Hadoop MapReduce设计思想及优缺点 设计思想 优点: 缺点: 2. Hadoop MapReduce核心思想 3.MapReduce工作机制 剖析MapRe ...
- MapReduce06 MapReduce工作机制
目录 5 MapReduce工作机制(重点) 5.1 MapTask工作机制 5.2 ReduceTask工作机制 5.3 ReduceTask并行度决定机制 手动设置ReduceTask数量 测试R ...
- hadoop MapReduce 工作机制
摸索了将近一个月的hadoop , 在centos上配了一个伪分布式的环境,又折腾了一把hadoop eclipse plugin,最后终于实现了在windows上编写MapReduce程序,在cen ...
- MapRdeuce&Yarn的工作机制(YarnChild是什么)
MapRdeuce&Yarn的工作机制 一幅图解决你所有的困惑 那天在集群中跑一个MapReduce的程序时,在机器上jps了一下发现了每台机器中有好多个YarnChild.困惑什么时Yarn ...
随机推荐
- SWIG 3 中文手册——2. 引言
目录 2 引言 2.1 SWIG 是什么? 2.2 为什么使用 SWIG? 2.3 一个 SWIG 示例 2.3.1 SWIG 接口文件 2.3.2 swig 命令 2.3.3 构建 Perl5 模块 ...
- vertica审计日志
最近时段的所有请求: select * from dc_requests_issued order by time desc limit 10; 默认在磁盘上保留50MB: dbadmin=> ...
- [转帖] db file sequential read及优化
http://blog.itpub.net/12679300/viewspace-1185623/ db file sequential read及优化 原创 Oracle 作者:wzq609 时间: ...
- Svn CleanUp failed解决方案
在项目目录下找到wc.db文件,使用sqlite工具打开,清空main下的WC_LOCK和 WORK_QUEUE表即可.
- day60——单表操作补充(批量插入、查询、表结构)
day60 批量插入(bulk_create) # bulk_create obj_list = [] for i in range(20): obj = models.Book( title=f'金 ...
- SQL Server返回DATETIME类型,年、月、日、时、分、秒、毫秒
SQL Server返回DATETIME类型的年.月.日,有两种方法,如下所示: DECLARE @now DATETIME=GETDATE() --第一种方法 SELECT @now,YEAR(@n ...
- C#项目 App.config 配置文件不同使用环境配置
问题 部署项目时,常常需要根据不同的环境使用不同的配置文件.例如,在部署网站时可能希望禁用调试选项,并更改连接字符串以使其指向不同的数据库.在创建 Web 项目时,Visual Studio 自动生成 ...
- 题解 POJ 2559【Largest Rectangle in a Histogram】(单调栈)
题目链接:http://poj.org/problem?id=2559 思路:单调栈 什么是单调栈? 单调栈,顾名思义,就是单调的栈,也就是占中存的东西永远是单调(也就是递增或递减)的 如何实现一个单 ...
- Java之路---Day13
2019-10-28-22:40:14 目录 1.Instanceof关键字 2.Final关键字 2.1Final关键字修饰类 2.2Final关键字修饰成员方法 2.3Final关键字修饰局部变量 ...
- jmeter-Unable to access jarfile ApacheJMeter.jar
jmeter在运行时报错Unable to access jarfile ApacheJMeter.jar.如下图: 检查后发现jmeter_home/bin/目录下缺失 ApacheJMeter.j ...